-
回归算法的评估指标
回归算法:对历史数据进行拟合,形成拟合方程。接下来使用该方程对新数据进行预测。下图中红线表示的是一元数据的拟合方程,如果数据是二元数据,那么它的拟合方程就是一个拟合平面,对于更高维的数据,它的拟合方程将更加复杂。
对于回归算法,我们评价它的好坏,就是看它的预测结果与我们的真实结果的差异大小。在回归算法中,我们最常用的评估指标分别是:平均绝对值误差,平均绝对百分比误差、均方误差,均方根误差,可决系数、校正决定系数、误差平方和。
1.平均绝对值误差
计算每一个样本的预测值和真实值的差的绝对值,然后求和再取平均值。其公式如下, Yi为真实值, F(Xi)算法的预测值。,可以更好地反映预测值误差的实际情况 ,在线性回归的时候我们的目的就是让这个损失函数最小。
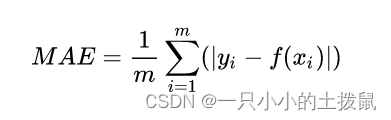
Python方法:
- MAE_1 = np.mean(abs(y_test - prediction))
- print(MAE_1)
- [out]:3.3446655035987476
MSE相当于模型中的 损失函数 ,线性回归过程中尽量让该损失函数最小。那么模型之间的对比也可以用它来比较。平均绝对误差可以避免误差相互抵消的问题,因而可以准确反映实际预测误差的大小。MSE可以评价模型的预测精度,MSE的值越小,说明预测模型对于目标的拟合程度越精确。
2、平均绝对百分比误差
范围[0,+∞),MAPE 为0%表示完美模型,MAPE 大于 100 %则表示劣质模型。MAPE 的值越小,说明预测模型拥有更好的精确度。MAPE 是一个百分比值,因此比其他统计量更容易理解。例如,如果 MAPE 为 5,则表示预测结果较真实结果平均偏离 5 %。MAPE 的值越小,说明预测模型拥有更好的精确度。
Python方法:
- import numpy as np
- def mape(y_true, y_pred):
- """
- 参数:
- y_true -- 测试集目标真实值
- y_pred -- 测试集目标预测值
- 返回:
- mape -- MAPE 评价指标
- """
- n = len(y_true)
- mape = sum(np.abs((y_true - y_pred)/y_true))/n*100
- return mape
平均绝对百分比误差,与RMSE相比,更加鲁棒,因为MAPE对每个点的误差进行了归一化。理论上,MAPE 的值越小,说明预测模型拟合效果越好,具有更好的精确度
3.均方误差
计算每一个样本的预测值与真实值差的平方,然后求和再取平均值。一般用来检测模型的预测值和真实值之间的偏差

Python方法:
- MSE_1 = np.mean((y_test - prediction)**2)
- print(MSE_1)
- [out]:19.831323672063235
4.均方根误差
均方根误差就是在均方误差的基础上再开方。即均方误差开根号,方均根偏移代表预测的值和观察到的值之差的样本标准差。将误差的结果就跟数据变成一个级别的。

python方法:
- RMSE_1 = np.sqrt(np.mean((y_test - prediction)**2))
- print(RMSE_1)
- [out]:4.45323743719816
RMSE(Root Mean Squard Error)均方根误差,RMSE其实是MSE开根号,两者实质一样,但RMSE能更好的描述数据。因为MSE单位量级和误差的量级不一样,而RMSE跟数据是一个级别的,更容易感知数据。
缺点:易受异常值的影响。5.可决系数
可决系数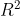 的值为0~1之间的值。
越接近于1,说明模型的效果越好,
越接近于0,说明的模型效果越差,当然
也存在负值,此时说明模型的效果非常的差。公式中
的值为0~1之间的值。
越接近于1,说明模型的效果越好,
越接近于0,说明的模型效果越差,当然
也存在负值,此时说明模型的效果非常的差。公式中
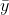 为 y 的平均值。
为 y 的平均值。

其中,分子部分表示真实值与预测值的平方差之和,类似于均方差 MSE;分母部分表示真实值与均值的平方差之和,类似于方差 Var。上面分子就是我们训练出的模型预测的所有误差,下面分母就是不管什么我们猜的结果就是y的平均数。
python方法:- R_1 = 1 - np.mean((y_test - prediction)**2)/np.mean((y_test - np.mean(y_test)**2))
- print(R_1)
- [out]:0.7836295385076281
根据 R-Squared 的取值,来判断模型的好坏,其取值范围为[0,1]:如果结果是 0,说明模型拟合效果很差;如果结果是 1,说明模型无错误。一般来说,R2 越接近于1,说明回归直线对观测值的拟合程度越好;相反,R2值越小,说明回归直线对观测值的拟合程度越差。
6、校正决定系数
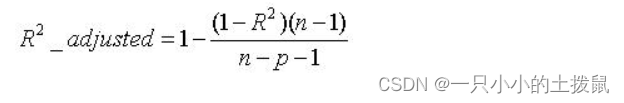
其中,n为样本数量,p为特征数量。 取值范围还是负无穷到1,大多是 0~1
一般来说,R-Squared 越大,表示模型拟合效果越好。R-Squared 反映的是大概有多准,因为,随着样本数量的增加,R-Square必然增加,无法真正定量说明准确程度,只能大概定量。
Adjusted R-Square 抵消样本数量对 R-Square的影响,做到了真正的 0~1,越大越好。 且越大越好。
- R2:r2_score(y_test,y_predict)
- Adjusted_R2::1-((1-r2_score(y_test,y_predict))*(n-1))/(n-p-1)
(机器学习)如何评价回归模型?——Adjusted R-Square(校正决定系数)_远行人_Xu的博客-CSDN博客_adjusted r square表示什么?
这个式子其实就是将R-Square式子中那个 “一堆除以一堆” 乘以 “一个稍大于1的数” 再被1减。样本数量(接上文flag)会影响“一个稍大于1的数”,故而 抵消样本数量对R-Square的影响 ,从而更能用一个0~1的数字描述回归模型的拟合情况好坏。
小结:
1. MAE, MSE, RMSE可以准确的计算出预测结果和真实的结果的误差大小,但却无法衡量模型的好坏程度。但是这些指标可以指导我们的模型改进工作,如调参,特征选择等。
2.的结果可以很清楚的说明模型的好坏,该值越接近于1,表明模型的效果越好。该值越接近于0,表明模型的效果越差。3、上面的几种衡量标准针对不同的模型会有不同的值。比如说预测房价, 那么误差单位就是万元。数子可能是3,4,5之类的。那么预测身高就可能是0.1,0.6之类的。没有什么可读性,到底多少才算好呢?不知道,那要根据模型的应用场景来。
看看分类算法的衡量标准就是正确率,而正确率又在0~1之间,最高百分之百。最低0。很直观,而且不同模型一样的。那么线性回归有没有这样的衡量标准呢?答案是有的。那就是R2
-
相关阅读:
offline RL | CQL:魔改 Bellman error 更新,得到 Q 函数 lower-bound
RSS阅读器
iOS性能优化
【探索微软 Edge:现代化的网页浏览体验】
MongoDB、Elasticsearch
如何理解 AnnData ?
利用ChatGPT进行数据分析并生成数据分析报告
浏览器渲染原理
测试自动化:TPT API
maven基础
- 原文地址:https://blog.csdn.net/qq_40379132/article/details/126291360