-
大数据Apache Druid(三):Druid集群搭建

文章目录
7、将安装包分发到node4,node5节点上,并修改host
8、在node3、node4、node5节点上配置Druid环境变量
Druid集群搭建
一、集群搭建
Druid进程可以以任意方式进行部署,为了方便部署,建议分为三种服务器类型:主服务器(Master)、查询服务器(Query)、数据服务器(Data)。
- Master:运行Coordinator和Overlord进程,负责集群可用和读取数据。
- Query:运行Broker和Router进程,负责处理外部客户端的查询。
- Data:运行Historical和Middle Manager进程,负责数据接收和所有可查询数据的存储。
我们按照以上方式来进行Druid集群的搭建。步骤如下:
1、节点划分
节点IP
节点名称
角色
192.168.179.6
node3
zk,Druid Master(overload,coordinator)
192.168.179.7
node4
zk,Druid Data(middleManager,historical)
192.168.179.8
node5
zk,Druid Query(broker,router)
2、Druid安装包下载
Druid安装包下载地址:http://druid.apache.org/downloads.html
选择具体的Druid安装包下载地址:
https://archive.apache.org/dist/druid/
这里我们下载Druid 0.21.1版本
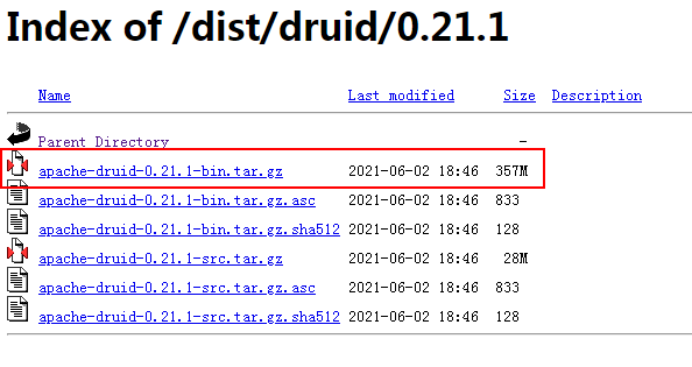
注意:经过测试,Druid0.20.1 版本有bug(在搭建好Druid后,相应的集群内容查询缺少字段导致报错),尽量下载0.21.1版本。
3、上传安装包,解压并配置
将安装包首先上传到node3节点“/software”目录下,并解压
- [root@node3 ~]# cd /software/
- [root@node3 software]# tar -zxvf ./apache-druid-0.21.1-bin.tar.gz
进入“/software/apache-druid-0.21.1/conf/druid/cluster/_common”
配置common.runtime.properties文件如下:
- #由于需要mysql存储元数据,添加“mysql-metadata-storage”外部组件
- druid.extensions.loadList=["druid-hdfs-storage", "druid-kafka-indexing-service", "druid-datasketches","mysql-metadata-storage"]
- #
- # Hostname
- #
- #配置Master 节点为node3
- druid.host=node3
- #
- # Zookeeper
- #
- #配置zookeeper集群,这里使用外部集群
- druid.zk.service.host=node3:2181,node4:2181,node5:2181
- druid.zk.paths.base=/druid
- #
- # Metadata storage
- #
- #配置Metadata Storage存储使用mysql存储,首先注释掉默认的derby,再配置#mysql存储
- # For Derby server on your Druid Coordinator (only viable in a cluster with a single Coordinator, no fail-over):
- #druid.metadata.storage.type=derby
- #druid.metadata.storage.connector.connectURI=jdbc:derby://localhost:1527/var/druid/metadata.db;create=true
- #druid.metadata.storage.connector.host=localhost
- #druid.metadata.storage.connector.port=1527
- # For MySQL (make sure to include the MySQL JDBC driver on the classpath):
- druid.metadata.storage.type=mysql
- druid.metadata.storage.connector.connectURI=jdbc:mysql://node2:3306/druid
- druid.metadata.storage.connector.user=root
- druid.metadata.storage.connector.password=123456
- #
- # Deep storage
- #
- #配置Deep Storage存储使用HDFS,首先注释掉默认本地配置再配置HDFS
- # For local disk (only viable in a cluster if this is a network mount):
- #druid.storage.type=local
- #druid.storage.storageDirectory=var/druid/segments
- # For HDFS:
- druid.storage.type=hdfs
- druid.storage.storageDirectory=hdfs://mycluster/druid/segments
- #
- # Indexing service logs
- #
- # 配置索引数据存储使用HDFS,首先注释掉默认本地配置,再配置HDFS
- # For local disk (only viable in a cluster if this is a network mount):
- #druid.indexer.logs.type=file
- #druid.indexer.logs.directory=var/druid/indexing-logs
- # For HDFS:
- druid.indexer.logs.type=hdfs
- druid.indexer.logs.directory=hdfs://mycluster/druid/indexing-logs
4、配置内存
由于Druid默认一些进程使用内存至少8G或者64G内存,我们内存不够所以这里设置下对应角色使用的内存少一些。修改具体如下:
修改Coordinator-overlord的jvm内存:
- #vim /software/apache-druid-0.21.1/conf/druid/cluster/master/coordinator-overlord/jvm.config
- -Xms512m
- -Xmx512m
修改historical的jvm内存:
- #vim /software/apache-druid-0.21.1/conf/druid/cluster/data/historical/jvm.config
- -Xms512m
- -Xmx512m
- -XX:MaxDirectMemorySize=128m
修改historical缓存数据量大小:
- #vim /software/apache-druid-0.21.1/conf/druid/cluster/data/historical/runtime.properties
- #druid.processing.buffer.sizeBytes=500MiB
- druid.processing.buffer.sizeBytes=5000000
- #druid.cache.sizeInBytes=256MiB
- druid.cache.sizeInBytes=2560000
修改middleManager缓存数据量大小:
- #vim /software/apache-druid-0.21.1/conf/druid/cluster/data/middleManager/runtime.properties
- #druid.indexer.fork.property.druid.processing.buffer.sizeBytes=100MiB
- druid.indexer.fork.property.druid.processing.buffer.sizeBytes=1000000
修改broker的jvm内存:
- #vim /software/apache-druid-0.21.1/conf/druid/cluster/query/broker/jvm.config
- -Xms512m
- -Xmx512m
- -XX:MaxDirectMemorySize=128m
修改broker 读取数据缓存大小:
- #vim /software/apache-druid-0.21.1/conf/druid/cluster/query/broker/runtime.properties
- #druid.processing.buffer.sizeBytes=500MiB
- druid.processing.buffer.sizeBytes=5000000
修改router使用的jvm内存:
- #vim /software/apache-druid-0.21.1/conf/druid/cluster/query/router/jvm.config
- -Xms512m
- -Xmx512m
5、mysql中创建druid库及上传mysql驱动包
由于Druid使用MySQL存储元数据,并且配置中使用的是MySQL中druid库,这里在node2 MySQL节点创建对应库:
- [root@node2 ~]# mysql -u root -p123456
- mysql> CREATE DATABASE druid DEFAULT CHARACTER SET utf8;
- Query OK, 1 row affected (0.01 sec)
创建完成之后,将mysql 驱动包上传到node3“/software/apache-druid-0.21.1/extensions/mysql-metadata-storage”路径下。
6、准备HDFS配置文件
由于将Segment和索引数据存放在HDFS中,Druid需要连接HDFS,需要Hadoop中相关配置文件,在node3“/software/apache-druid-0.21.1/conf/druid/cluster/_common”目录下创建目录“hadoop-xml”,将Hadoop中core-site.xml、hdfs-site.xml复制到“hadoop-xml”目录中。
7、将安装包分发到node4,node5节点上,并修改host
将node3安装包分发node4,node5节点:
- [root@node3 software]# scp -r ./apache-druid-0.21.1 node4:/software/
- [root@node3 software]# scp -r ./apache-druid-0.21.1 node5:/software/
上传完成后,在node4,node5对应节点文件“/software/apache-druid-0.21.1/conf/druid/cluster/_common/common.runtime.properties”中修改对应的host:
- #node4节点指定为 Data节点
- #
- # Hostname
- #
- druid.host=node4
- #node5节点指定为Query节点
- #
- # Hostname
- #
- druid.host=node5
8、在node3、node4、node5节点上配置Druid环境变量
- #vim /etc/profile
- export DRUID_HOME=/software/apache-druid-0.21.1/
- export PATH=$PATH:$DRUID_HOME/bin
- #使profile生效
- source /etc/profile
二、Druid集群启动
1、启动zookeeper集群
在zookeeper各个节点上启动zookeeper集群:zkServer.sh start
2、启动HDFS集群
由于数据存储及索引数据使用HDFS存储,所以需要启动HDFS集群。
3、Druid各个节点启动对应服务
在node3、node4、node5上启动对应Druid的Master、Data、Query服务。
- #node3 启动Master 服务
- [root@node3 ~]# start-cluster-master-no-zk-server
- #node4启动Data 服务
- [root@node4 _common]# start-cluster-data-server
- #node5启动Query服务
- [root@node5 ~]# start-cluster-query-server
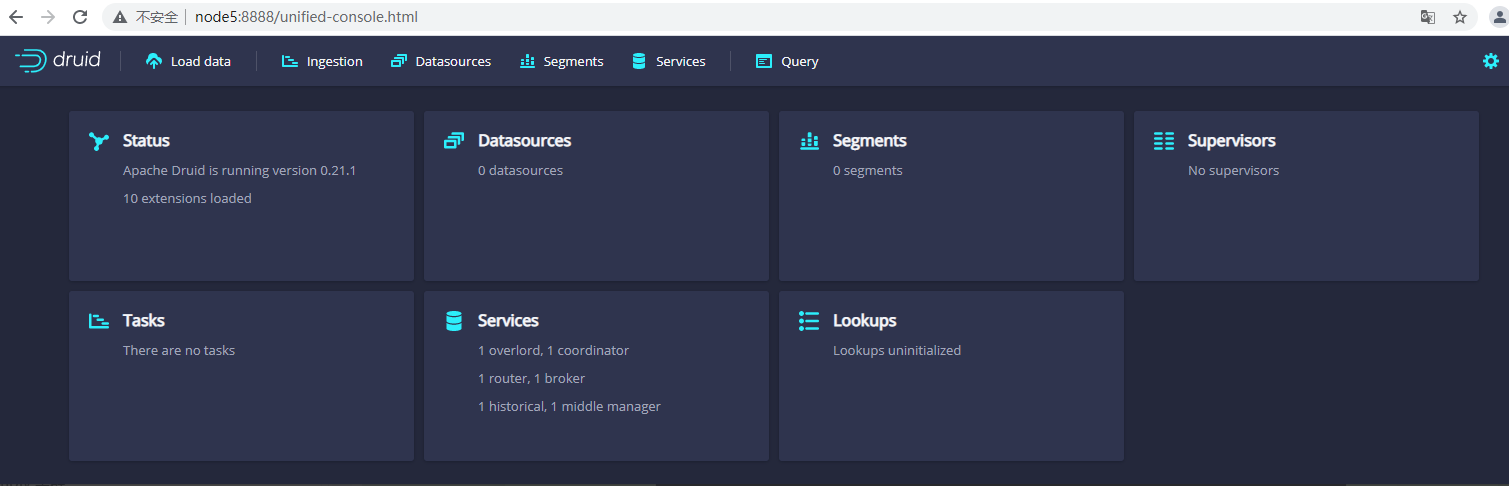
4、查看集群webui
在浏览器访问“http://node5:8888”可以访问Druid webui
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
-
相关阅读:
ArcGIS Pro中的回归分析浅析(加更)关于广义线性回归工具的补充内容
【Spring】 IoC & AOP 控制反转与面向切面编程
sql事务-1
MySQL主从复制与读写分离(附配置实例)
前后端分离跨域问题解决方案
智谱API调用
HTML5与CSS3实现动态网页(下)
一个已经存在10年,却被严重低估的 Python 库
用户体验设计常犯逻辑谬误
基于Java+vue前后端分离高校社团管理系统设计实现(源码+lw+部署文档+讲解等)
- 原文地址:https://blog.csdn.net/xiaoweite1/article/details/126291727
