-
Linux三剑客之grep、sed、awk
一、grep 命令,擅长查找字符串,正向查找,反向查找,正则查找,多文件查找,递归查找等
grep 后面跟的字符串可以是正则表达式、可以通过 -i 忽略大小写、可以通过 -n 显示行号

二、sed(全称:Stream Editor),擅长对文件做数据做修改的操作,非常高效
1. a 在指定行下添加数据,比如在第一行下添加数haha
sed '1a\haha' hello.txt

2.i 在指定行前面添加数据,如
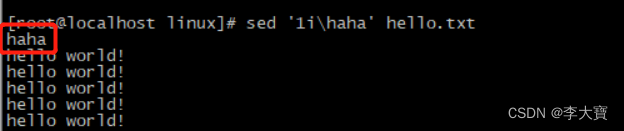
3.在文件末尾添加数据 $在这里表示最后一行的意思
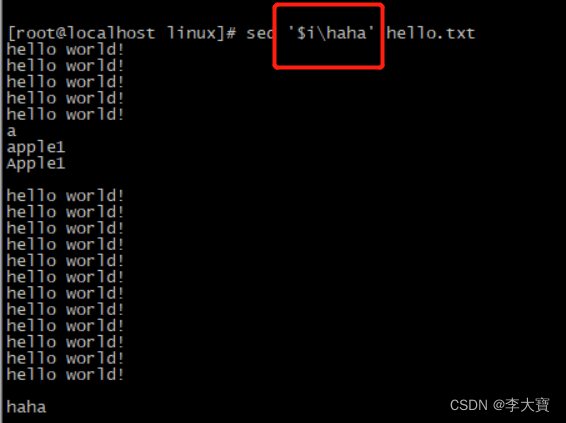
4.用d可以删除指定行

5.替换 sed[address]s/pattern/replacement/flags
s表示替换 pattern要需要替换的内容 replacement替换的内容 flags表示要替换的字符串在这行中出现第几次才替换,其中g表示只要匹配到都替换,空表示只会在第一次匹配成功时候才替换
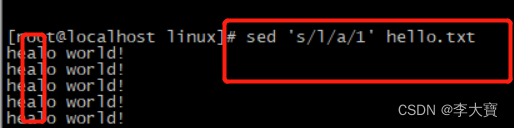



sed 默认是不修改源文件的,要修改源文件,需要加上参数-i 即可
三、awk
awk是一个强大的文本分析工具,相对于grep的查找,sed编辑,awk在对数据分析并生成报告时候,显得尤为强大,简单说,awk就是把文件逐行的读入,以空白符为默认分割符将每行内容分片,切成的部分再进行各种分析处理,它在处理文本数据的时候,会自动给每行赋予变量,变量从1开始
$1 表示文本的第1个数据 $2 表示文本的第二个数据 $0 代表整个文本行的内容

我们可以用- F指定字段分隔符 awk -F: '{print $1}' /etc/passwd

可以对数据进行过滤,只获得满足条件的数据

可以通过$指定具体是哪一列,需要把具体的对比逻辑放到小括号里面

-
相关阅读:
想成为IC后端工程师得会啥?主要工作内容是什么?
uniapp 学习笔记二十四 购物车编辑弹窗页面搭建
Day 252/300 《图解HTTP》读书笔记(四)——HTTP报文头信息
CDO关注的5大趋势
简单好用的文档管理系统MinDoc
mybatis一级缓存、二级缓存的意义是什么?
【考研英语】2011 年英语(一)排序题思路复盘(费曼学习法)
基于SpringBoot的企业客户管理系统
华山西安三日行
swift内存绑定
- 原文地址:https://blog.csdn.net/libaowen609/article/details/126286289