-
【web-解析目标】(1.1.1)解析内容和功能:web信息抓取
目录
一、web-解析目标
1.1、第一步:收集信息
收集和分析与其有关的一些关键信息
------>了解攻击目标
1.2、第二步:分析功能
枚举应用程序的内容与功能(一些功能不明显, 需要猜测和运气)
------->实际功能与运行机制,功能区域进行分类, 参照各种实例在找不同类型的漏洞
1.3、第三步:目标所使用的技术
分析应用程序运行机制的每一个方面、核心安全机制及其(在客户端和服务器上)使用的技术
------>确定攻击面,选择主要目标, 发现可供利用的漏洞
二、Web信息抓取
2.1、自动抓取
使用各种工具(BurpSuite、WebScarab、ZedAttack Proxy和CAT)自动抓取Web站点的内容。工具首先请求一个Web页面对其进行分析, 查找连接到其他内容的链接,然后再请求这些链接页面,再继续进行这个循环, 直到找不到新的内容为止
分析HTML菜单, 并使用各种预先设定值或随机数将这些表单返回给应用程序, 以扩大搜索范围、浏览多阶段功能、进行基于表单的导航(如什么地方使用下拉列表作为内容菜单)。一些工具还对客户端JavaScript行某种形式的分析, 以提取指向其他内容的URL
许多Web服务器的Web根目录下有一个名为robots. txt的文件, 其中列出了站点不希望Web爬虫访问或坟索引擎列入索引的URL。这个文件中可能包含敏感功能的参考信息等敏感信息
使用BurpSuie解析web程序(就是代理后,点开页面,bp会自动爬取,如robots.txt引用的目录未链接到任何地方,可能就爬不出来)
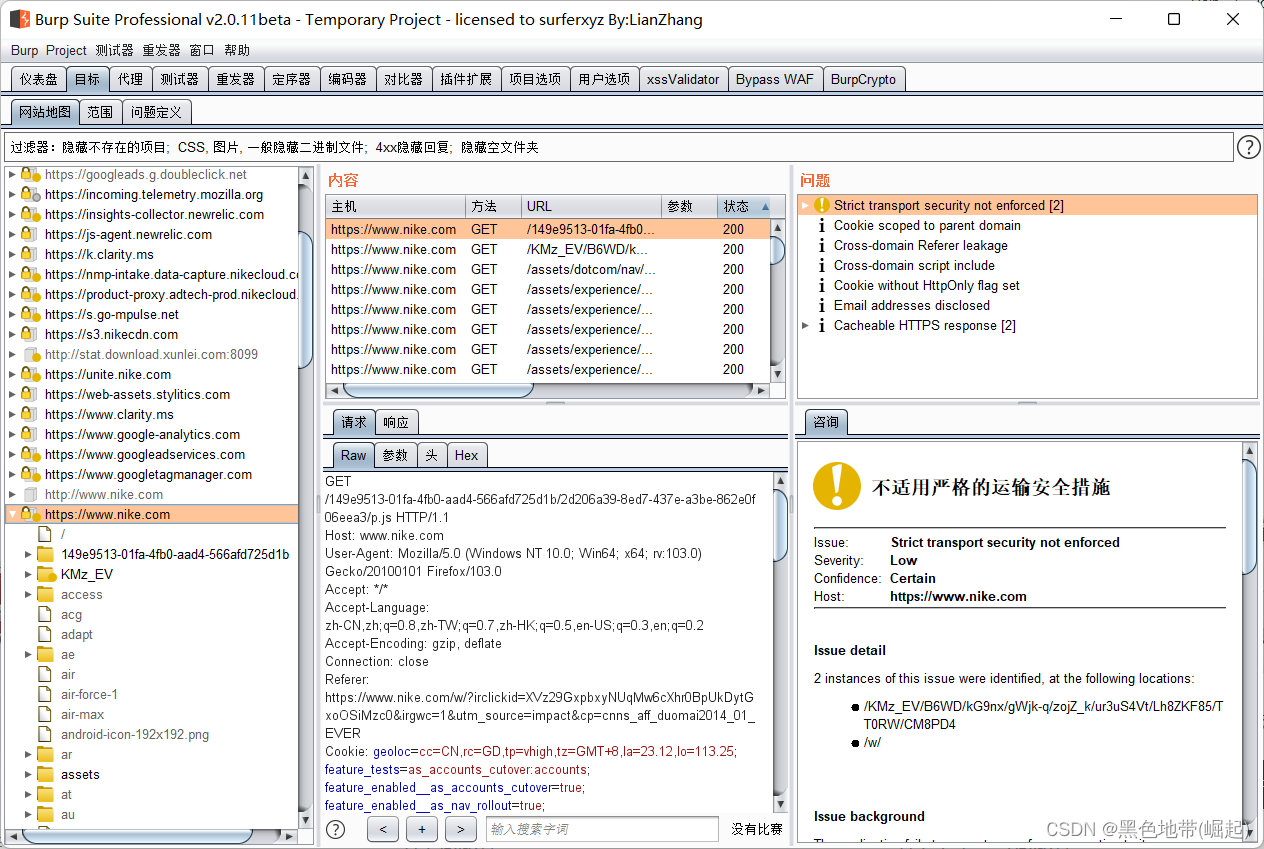
缺点:
1、可能无法正确处理不常用的导航机制(使用复杂的JavaScnpt代码动态建立和处理的菜单),会遗漏某个方面的功能
2、可能无法抓取到隐藏在编译客户端对象(如Flash和Java applet)中的链接
3、多阶段功能会执行输入检查(如用户注册表单中可能包含姓名、电子邮件地址, 电话号码和邮政编码字段), 可能不会接受由自动工具提交的值。
(自动应用程序爬虫会向每一个可编辑的表单字段提交测试字符串,程序返回一条错误消息, 称数据无效,由于爬虫无法处理这种错误消息, 也就无法成功通过注册,无法发现注册后的其他内容或功能)
4、自动化爬虫通常使用URL作为内容标识符。为避免重复的抓取, 如果链接内容已被请求, 它们会识别出来并不会再向其发出诮求。
许多程序使用基于表单的导航机制,相同的URL可能返回不同的内容和功能,就会被遗漏
5、一些应用程序在URL中插入实际上并不用于确定资源或功能的可变数据。每个页面中都可能包含要请求的新URL, 导致不断的抓取
6、应用程序的身份验证机制,要实现有效抓取, 必须能够处理这种机制才能访问它所保护的功能。如果为其手动配置会话令牌或提交给登录功能的证书, 前面提到的爬虫就能实现有效抓取。然而, 即使获得令牌或证书, 由于各种原因, 爬虫执行的一些操作也会让通过验证的会话中断
会访问所有URL, 可能会请求到退出的功能,致使会话中断
当向某个敏感功能提交无效输入,程序可能会终止会话
若页面都需使用令牌,无法按正确的顺序请求,导致会话结束2.2、用户指定位置抓取
简而言之,就是在bp等软件代理爬取的同时,点开不同的功能页面,进行登录,注册等操作,bp并会继续进行爬取,目的是为了确保收集的数据够丰富,并且不会意外终止发生
-
相关阅读:
C#面:C#面向对象的思想主要包括什么?
破局存量客群营销,试一下客户分群管理(含聚类模型等实操效果评估)
2022最新软件测试八股文,已经帮助3000+测试员入职大厂....
day-3-4-2
《LeetCode力扣练习》代码随想录——链表(设计链表---Java)
进程相关概念
systemverilog function的一点小case
基于嵌入式的密码访问的门锁系统
RTL8762DK RTC(五)
优雅而高效的JavaScript——扩展运算符
- 原文地址:https://blog.csdn.net/qq_53079406/article/details/126264374
 https://blog.csdn.net/qq_53079406/article/details/125898777?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166017886416781667887117%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=166017886416781667887117&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~rank_v31_ecpm-1-125898777-null-null.nonecase&utm_term=robot&spm=1018.2226.3001.4450
https://blog.csdn.net/qq_53079406/article/details/125898777?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166017886416781667887117%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=166017886416781667887117&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~rank_v31_ecpm-1-125898777-null-null.nonecase&utm_term=robot&spm=1018.2226.3001.4450