-
MYSQLg高级------聚簇索引和非聚簇索引
开始我们需要先了解点相关的知识,帮助大家更好的理解:(有基础的可以忽视,请大家多多包含)
MySQL支持两种存储引擎分别是innoDB和MyISAM,默认使用innoDB存储引擎;innoDB
Mysql 索引根据物理存储形式,Innodb中包括聚簇索引和非聚簇索引;
聚簇索引(clustered index)也称之为聚集索引,也称之为主键索引;
非聚簇索引(non clustered index )也称为二级索引,辅助索引;
扩展:
每个InnoDB表都有一个特殊的索引,称为聚簇索引,用于存储行数据。
-
在创建数据库表的时候,首先会查看数据表中有没有主键,有的话就使用主键创建一个索引,这个主键索引就是**聚簇索引(**如果主键没有逻辑唯一且非空的列或列集,最好是设置成自动递增的)。
-
如果没有为表创建主键,则MySQL会在所有键列都不为NULL的情况下找到第一个UNIQUE(唯一索引)索引,InnoDB会将其用作聚集索引。
-
如果表没有PRIMARY KEY(主键索引)或合适的UNIQUE(唯一索引)索引,则InnoDB在包含行ID值的合成列上内部生成一个名GEN_CLUST_INDEX的隐藏的聚集索引(隐藏的是看不到的,也就是说不会出现在desc table中,行ID是一个6字节(rowid)的字段,随着插入新行而单调增加)。
-
总之,innoDB引擎创建的主键索引就是聚簇索引。聚簇索引包含主键id,数据库对应行数据和指针并将这些数据存储在B+Tree的叶子结点上。其余非主键索引全部都是辅助索引(非聚簇索引),对于InnoDB存储引擎创建的辅助索引(非聚簇索引),索引内容只包含当前字段的内容与主键id,通过查询主键id进行数据的二次查找
从这三种情况来看的话,就是说不管你有没有创建主键,mysql都会给你弄一个聚簇索引,你创建了就用你设置的主键为聚簇索引,没有创建就给你来个隐藏的。
聚簇索引:将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据(一个表中只有一个聚簇索引)
非聚簇索引:将数据与索引分开存储,索引结构的叶子节点指向了数据对应的位置
在innodb中,在聚簇索引之上创建的索引称之为辅助索引(除了聚簇索引都是非聚簇索引),非聚簇索引都是辅助索引,像复合索引、前缀索引、唯一索引。辅助索引叶子节点存储的不再是行的物理位置,而是主键值,辅助索引访问数据总是需要二次查找。


根据上面的图片我们也可以理解为:聚簇索引:聚簇索引可以直接的找到数据
非聚簇索引:需要根据条件先找到聚簇索引再通过聚簇索引找到索引对应的数据;
如果看完上面觉得还是理解不了,那么继续看下面的
从sql代码的角度带大家再理解下:
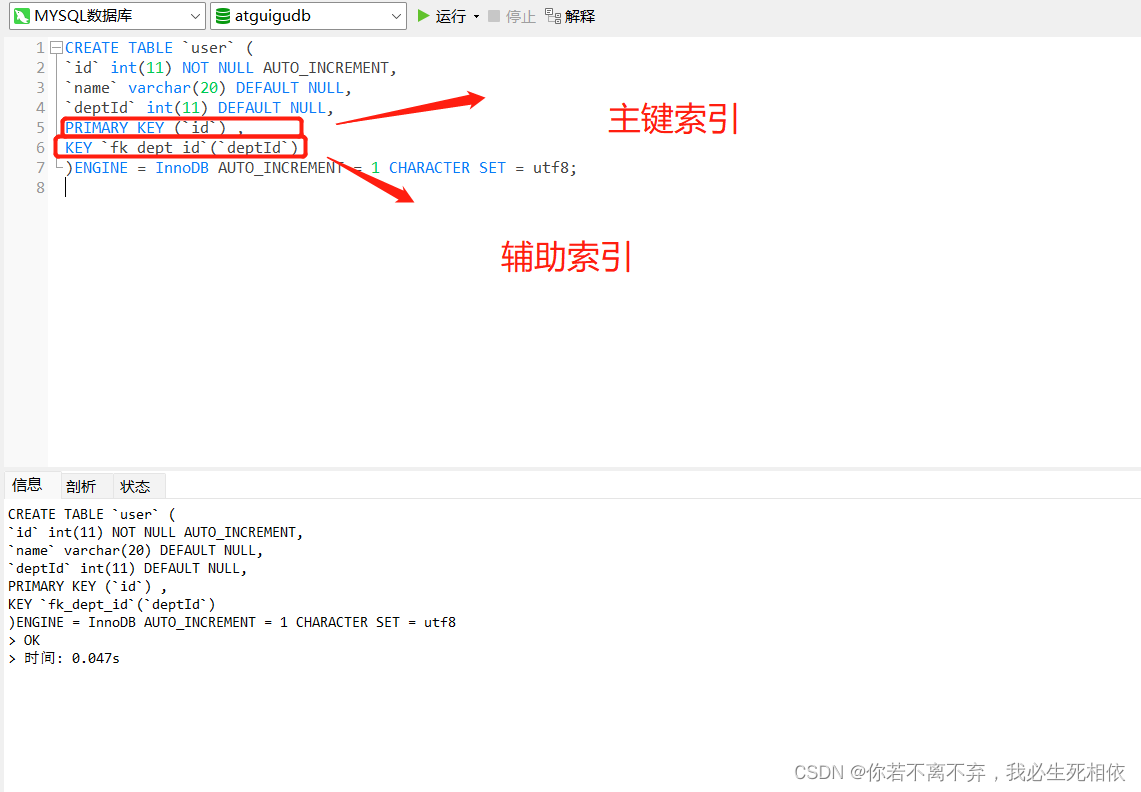
CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(20) DEFAULT NULL, `deptId` int(11) DEFAULT NULL, PRIMARY KEY (`id`) , KEY `fk_dept_id`(`deptId`) )ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8; INSERT INTO `atguigudb`.`user` (`id`, `name`, `deptId`) VALUES (1, '小闫', 10); INSERT INTO `atguigudb`.`user` (`id`, `name`, `deptId`) VALUES (2, '老闫', 10); INSERT INTO `atguigudb`.`user` (`id`, `name`, `deptId`) VALUES (3, '小闫01', 10); INSERT INTO `atguigudb`.`user` (`id`, `name`, `deptId`) VALUES (4, '小闫02', 10); INSERT INTO `atguigudb`.`user` (`id`, `name`, `deptId`) VALUES (5, '小闫03', 10);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
查看索引
(如果对索引的了解及其应用不是明白,请移步)SHOW INDEX FROM user;- 1

无论哪种方式都是帮助大家更好的去理解他;(不足之处,坦然接受批评)
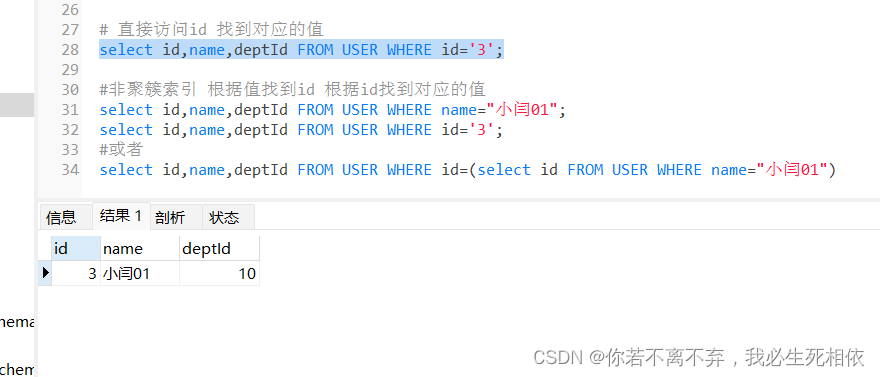
#我们要查询出id 为3 name为 小闫01 的数据; #分别用聚簇索引 和 非聚簇索引的思想帮助大家理解下 # 直接访问id 找到对应的值 select id,name,deptId FROM USER WHERE name='3'; #非聚簇索引 根据值找到id 根据id找到对应的值 select id,name,deptId FROM USER WHERE name="小闫01"; select id,name,deptId FROM USER WHERE name='3'; #或者 select id,name,deptId FROM USER WHERE id=(select id FROM USER WHERE name="小闫01")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
聚簇索引
非聚簇索引

聚簇索引具有唯一性,由于聚簇索引是将数据跟索引结构放到一块,因此一个表仅有一个聚簇索引。
表中行的物理顺序和索引中行的物理顺序是相同的,在创建任何非聚簇索引之前创建聚簇索引,这是因为聚簇索引改变了表中行的物理顺序,数据行
按照一定的顺序排列,并且自动维护这个顺序;MyISAM
MyISAM使用的是非聚簇索引,非聚簇索引的两棵B+树看上去没什么不同,节点的结构完全一致只是存储的内容不同而已,主键索引B+树的节点存储了主键,辅助键索引B+树存储了辅助键。表数据存储在独立的地方,这两颗B+树的叶子节点都使用一个地址指向真正的表数据,对于表数据来说,这两个键没有任何差别。由于索引树是独立的,通过辅助键检索无需访问主键的索引树。


扩展:(根据自己需求自行查看)
使用聚簇索引的优势:
提问?
每次使用辅助索引检索都要经过两次B+树查找,看上去聚簇索引的效率明显要低于非聚簇索引,这不是多此一举吗?聚簇索引的优势在哪?(InnoDB聚簇索引和MyISAM的非聚簇索引对比InnoDB的优势)回答
1.由于行数据和聚簇索引的叶子节点存储在一起,同一页中会有多条行数据,访问同一数据页不同行记录时,已经把页加载到了Buffer中(缓存器),再次访问时,会在内存中完成访问,不必访问磁盘。这样主键和行数据是一起被载入内存的,找到叶子节点就可以立刻将行数据返回了,如果按照主键Id来组织数据,获得数据更快。2.辅助索引的叶子节点,存储主键值,而不是数据的存放地址。好处是当行数据放生变化时,索引树的节点也需要分裂变化;或者是我们需要查找的数据,在上一次IO读写的缓存中没有,需要发生一次新的IO操作时,可以避免对辅助索引的维护工作,只需要维护聚簇索引树就好了。另一个好处是,因为辅助索引存放的是主键值,减少了辅助索引占用的存储空间大小。
注:我们知道一次io读写,可以获取到16K大小的资源,我们称之为读取到的数据区域为Page。而我们的B树,B+树的索引结构,叶子节点上存放好多个关键字(索引值)和对应的数据,都会在一次IO操作中被读取到缓存中,所以在访问同一个页中的不同记录时,会在内存里操作,而不用再次进行IO操作了。除非发生了页的分裂,即要查询的行数据不在上次IO操作的换村里,才会触发新的IO操作。
3.因为MyISAM的主索引并非聚簇索引,那么他的数据的物理地址必然是凌乱的,拿到这些物理地址,按照合适的算法进行I/O读取,于是开始不停的寻道不停的旋转。聚簇索引则只需一次I/O。(强烈的对比)
4.不过,如果涉及到大数据量的排序、全表扫描、count之类的操作的话,还是MyISAM占优势些,因为索引所占空间小,这些操作是需要在内存中完成的。
聚簇索引需要注意的地方
当使用主键为聚簇索引时,主键最好不要使用uuid,因为uuid的值太过离散,不适合排序且可能出线新增加记录的uuid,会插入在索引树中间的位置,导致索引树调整复杂度变大,消耗更多的时间和资源。
建议使用int类型的自增,方便排序并且默认会在索引树的末尾增加主键值,对索引树的结构影响最小。而且,主键值占用的存储空间越大,辅助索引中保存的主键值也会跟着变大,占用存储空间,也会影响到IO操作读取到的数据量。
为什么主键通常建议使用自增id
聚簇索引的数据的物理存放顺序与索引顺序是一致的,即:只要索引是相邻的,那么对应的数据一定也是相邻地存放在磁盘上的。如果主键不是自增id,那么可以想 象,它会干些什么,不断地调整数据的物理地址、分页,当然也有其他一些措施来减少这些操作,但却无法彻底避免。但,如果是自增的,那就简单了,它只需要一 页一页地写,索引结构相对紧凑,磁盘碎片少,效率也高。
一个表中只能有一个索引吗?
可以按照需求创建多个索引,但不要太多(维护会比较麻烦)
每个索引是一个B+树,还是所有索引共用一个B+树?
一个索引一个B+树
如果多颗B+树的情况下,那么数据需要存几分?
1分
如果大家看完还是不够理解那么就去看看 :视频地址
-
-
相关阅读:
RocketMQ(18)——高可用配置
java毕业生设计学生会管理系统2021计算机源码+系统+mysql+调试部署+lw
Linux内核EXPORT_SYMBOL宏解析
bash shell 无法使用 perl 正则
JDK新特性-Stream流
范数-空间范数
【Pytorch Lighting】第 8 章:自监督学习
等精度频率计的设计与验证
mapbox 地图 生成矢量数据圆
你真的知道什么是正弦和余弦吗?使用 Python 和 Turtle 可视化数学
- 原文地址:https://blog.csdn.net/qq_42055933/article/details/126276127