-
Python Day18 csv文件和Excel文件操作【初级】
Day18 csv文件和Excel文件操作
1. csv文件读操作
1.1 什么是csv文件
csv文件叫逗号分割值文件 —— 每一行内容是通过逗号来区分出不同的列
csv文件可以直接通过excel打开,以行列的形式保存和显示数据,但是相对Excel文件,它只能存储数据,不能保存公式和函数。
1.2 csv读操作
引入模块
import csv- 1
1.2.1 创建打开csv文件
''' 文件对象 = open() 操作文件 文件对象.close() with open() as 文件对象: 操作文件 '''- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
f = open('电影.csv', 'r', encoding='utf-8')- 1
1.2.2 创建reader获取文件内容
csv.reder(文件对象) —— 获取文件内容返回一个迭代器,并且以列表为单位返回每一行内容
reader1 = csv.reader(f) print(list(reader1))- 1
- 2
csv.DictReader(文件对象) —— 获取文件内容返回一个迭代器,并且以字典为单位返回第2行开始的每一行内容(字典的键是第一行内容)
reader2 = csv.DictReader(f) print(list(reader2))- 1
- 2
注意:进行相关操作后需要关闭文件
f.close()- 1
2. csv文件写操作
2.1 csv文件写操作
2.1.1 打开文件
f = open('data.csv', 'w', encoding='utf-8')- 1
2.1.2 创建writer对象
方法1:csv.writer(文件对象) —— 创建writer对象,这个对象在写入数据的时候一行对应一个列表
方法2:csv.DictWriter(文件对象, 键列表) —— 创建writer对象,以字典为单位写入数据
a.以列表为单位写入一行内容
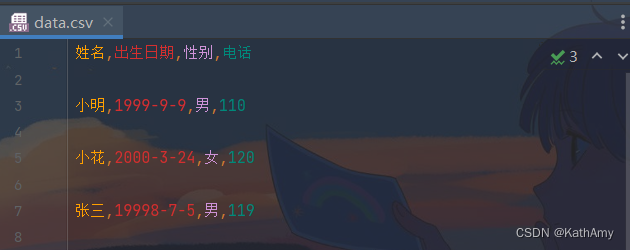
writer = csv.writer(f) # 一次写入一行内容 writer.writerow(['姓名', '出生日期', '性别', '电话']) writer.writerow(['小明', '1999-9-9', '男', '110']) # 一次写入多行内容 writer.writerows([ ['小花', '2000-3-24', '女', '120'], ['张三', '19998-7-5', '男', '119'] ])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
b.以字典为单位写入一行内容
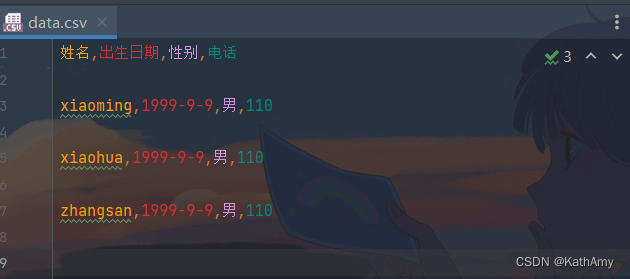
writer = csv.DictWriter(f, ['姓名', '出生日期', '性别', '电话']) # 写入文件头(将字典的键写入到文件开头) writer.writeheader() # 一次写入一行内容 writer.writerow({'姓名': 'xiaoming', '出生日期': '1999-9-9', '电话': '110', '性别': '男'}) # 一次写入多行内容 writer.writerows([ {'姓名': 'xiaohua', '出生日期': '1999-9-9', '电话': '110', '性别': '男'}, {'姓名': 'zhangsan', '出生日期': '1999-9-9', '电话': '110', '性别': '男'} ])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
3. 虚拟环境
3.1 系统环境
安装Python就可以为计算机提供一个Python的系统环境
3.2 虚拟环境
程序员根据需要自己创建的python环境
能够创建虚拟环境的前提,存在系统环境
3.3 环境的作用
1)提供python解释器
2)提供第三方库虚拟环境的存在可以让第三方库根据类别或者项目分开管理
3.4 创建虚拟环境的建议
1)工作的时候:一个项目一个虚拟环境,并且直接将其放在项目中
2)学习的时候:一类项目一个虚拟环境,不同类别的虚拟环境全部放在一个地方(项目以外)3.5 怎么创建虚拟环境
1)使用Pycharm创建
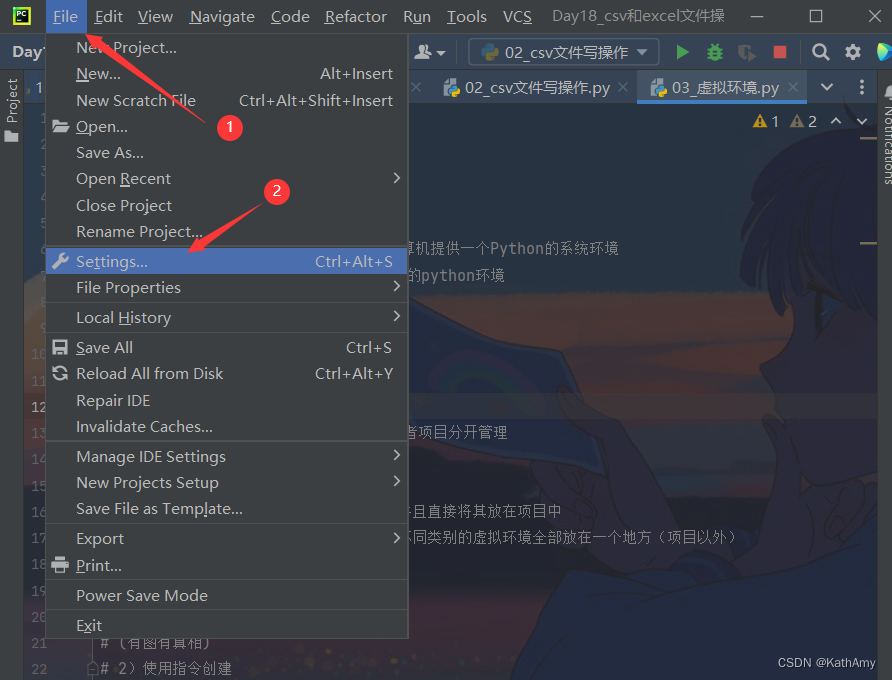
第一步:打开设置
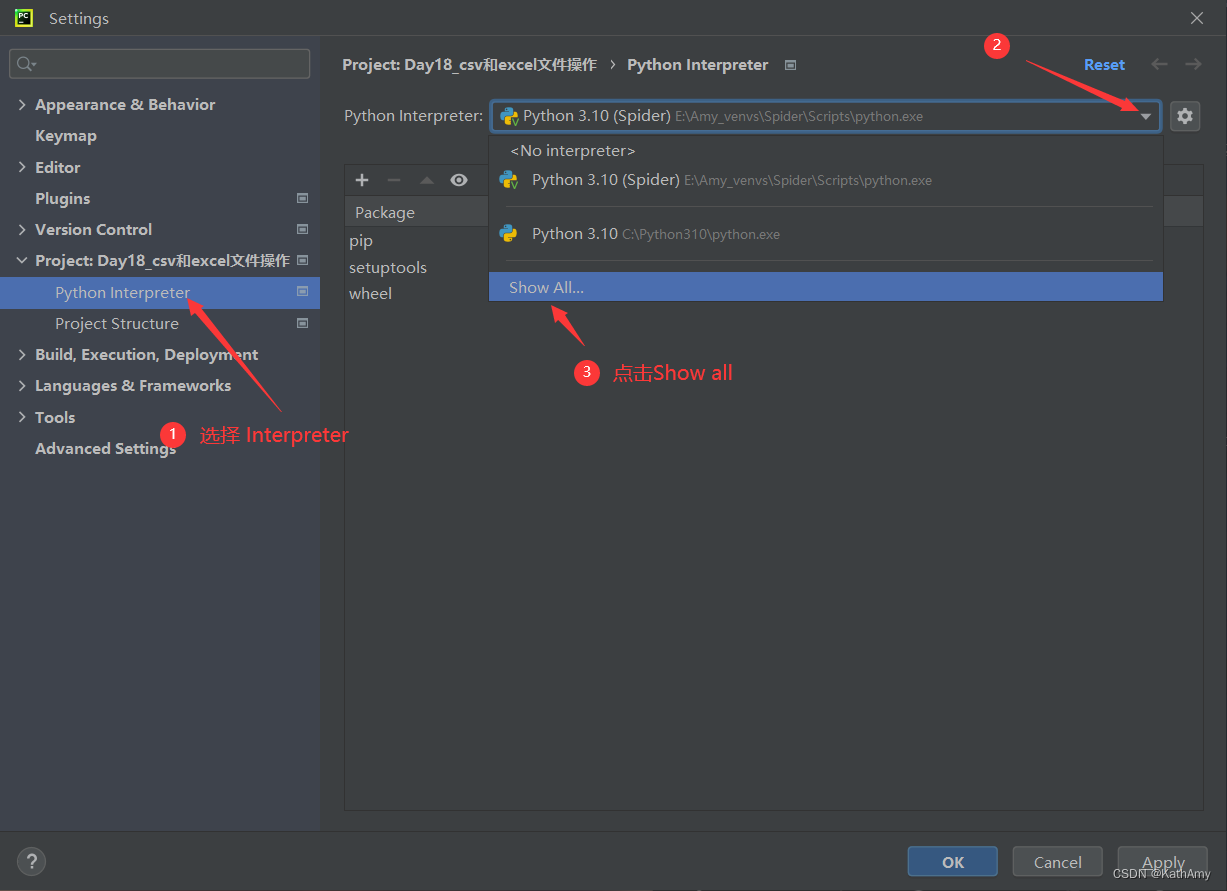
第二步:
第三步:点击+号
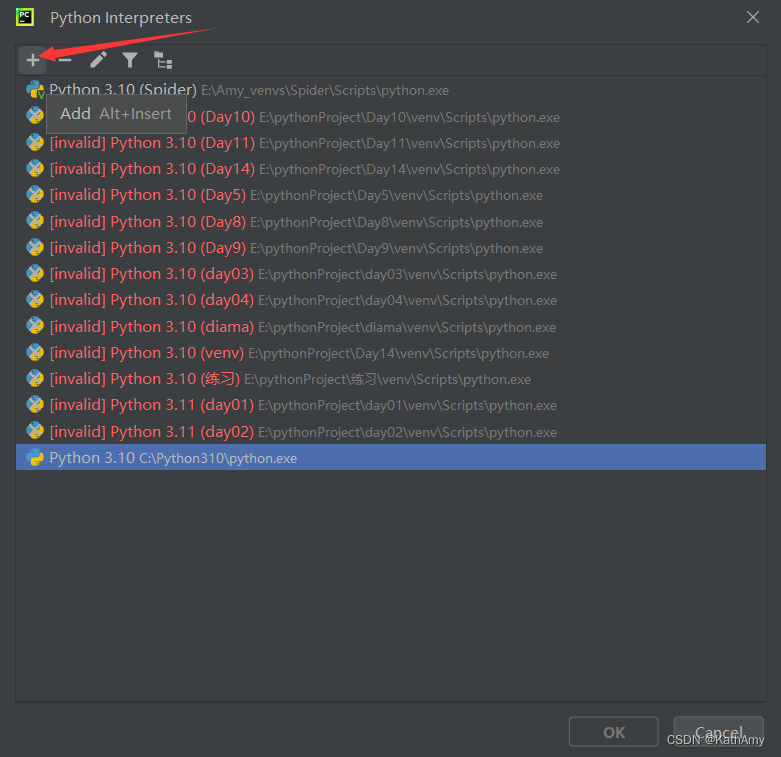
第四步:创建虚拟环境需要先建一个普通文件夹,放里面即可,文件夹可同时接纳多个虚拟环境,统一管理。
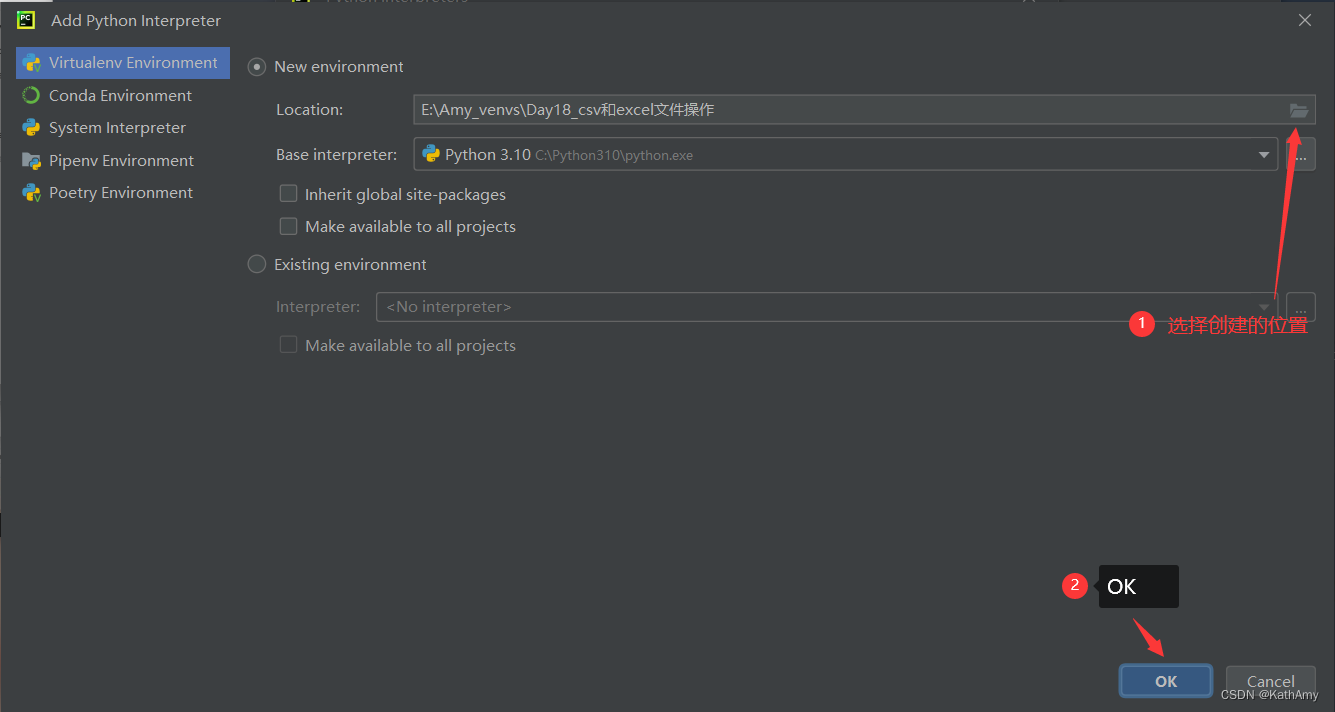
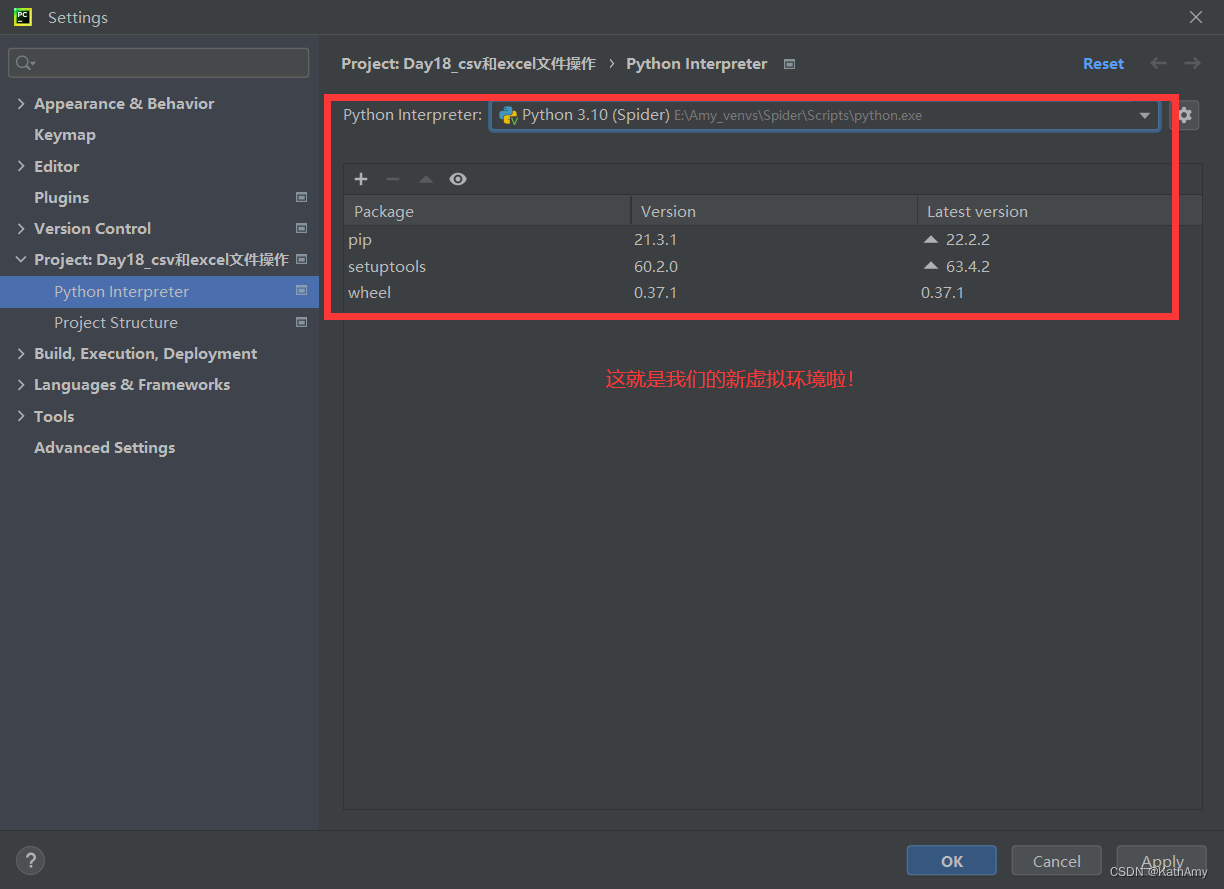
第五步:完成!
2)使用指令创建
import openpyxl- 1
4. Excel文件读操作
4.1 认识Excel文件
- 工作簿:一个Excel文件就是一个工作簿
- 工作表:一个工作簿中可以有多个工作表(至少一个)
- 单元格:保存数据的基本单位
- 行号和列号:可以确定单元格的位置
4.2 获取Excel文件内容
引入模块
import openpyxl- 1
4.2.1 打开Excel文件,创建工作簿对象
方法1:openpyxl.open(Excel文件路径)
方法2:openpyx.load_workbook(Excel文件路径)
workbook = openpyxl.open('三国人物数据.xlsx') # 获取工作簿中所有的工作表的表名 result = workbook.sheetnames print(result)- 1
- 2
- 3
- 4
- 5
4.2.2 获取工作表对象
方法1:工作簿对象.active —— 获取的是活跃表(被打开,正在编辑的表)
方法2:工作簿对象[工作表名称] —— 获取指定名字对应的工作表
sheet1 = workbook.active print(sheet1) sheet2 = workbook['三国武将数据'] print(sheet2)- 1
- 2
- 3
- 4
4.2.3 获取单元格
工作表对象.cell(行号, 列号)
cell = sheet2.cell(8, 1) print(cell)- 1
- 2
4.2.4 获取单元格的值
单元格.value
print(cell.value)- 1
4.2.5 获取最大行号和列号
注意:获取的是文件保存数据部分的最大行列号
行号:工作表对象.max_row
列号:工作表对象.max_column获取第一列所有数据(遍历)
column1 = [] for row in range(1, sheet2.max_row+1): cell = sheet2.cell(row, 1) column1.append(cell.value) print(column1)- 1
- 2
- 3
- 4
- 5
- 6
获取第1列到第3列所有的数据
for col in range(1, 4): column = [] for row in range(1, sheet2.max_row+1): cell = sheet2.cell(row, col) column.append(cell.value) print(column)- 1
- 2
- 3
- 4
- 5
- 6
5. Excel文件写操作
引入模块
import openpyxl- 1
注意:不管是以什么样的方式对Excel文件进行写操作,操作完成后必须保存
5.1 新建工作簿
5.1.1 新建工作簿对象
workbook = openpyxl.Workbook()- 1
5.1.2 保存
方法1:工作簿对象.save(文件路径)
方法2:workbook.save(‘保存的Excel.xlsx’)实际中新建工作簿的时候需要先判断工作簿对应的文件是否已经存在,存在就不需要新建,不存在才新建
方法一:try: workbook = openpyxl.open('students.xlsx') except FileNotFoundError: workbook = openpyxl.Workbook() workbook.save('students.xlsx')- 1
- 2
- 3
- 4
- 5
方法二:
import os # os.path.exists(文件路径) - 判断指定文件是否存在,存在返回True,不存在返回False if os.path.exists('students.xlsx'): workbook = openpyxl.open('students.xlsx') else: workbook = openpyxl.Workbook() workbook.save('files/student2.xlsx')- 1
- 2
- 3
- 4
- 5
- 6
- 7
5.2 工作表的写操作
5.2.1 新建工作表
工作簿对象.create_sheet(表名, 下标)
workbook.create_sheet() workbook.create_sheet('Python') workbook.create_sheet('Java', 0) workbook.save('students.xlsx')- 1
- 2
- 3
- 4
实际中的新建表:没有的时候才新建,有的时候直接打开
if 'Python' in workbook.sheetnames: sheet = workbook['Python'] else: sheet = workbook.create_sheet('Python') workbook.save('files/student2.xlsx')- 1
- 2
- 3
- 4
- 5
5.2.2 删除工作表
工作簿对象.remove(工作表对象)
workbook.remove(workbook['Sheet1']) workbook.save('files/student2.xlsx')- 1
- 2
实际中删除表:存在的时候才能删
if 'Sheet1' in workbook.sheetnames: workbook.remove(workbook['Sheet1']) workbook.save('files/student2.xlsx')- 1
- 2
- 3
5.3 单元格的写操作
单元格对象.value = 数据
java_sheet = workbook['Java'] java_sheet.cell(1, 3).value = '电话' java_sheet.cell(2, 1).value = None java_sheet.cell(4, 2).value = 'stu003' workbook.save('students.xlsx')- 1
- 2
- 3
- 4
- 5
- 6
-
相关阅读:
【计算机网络】TCP 的三次握手与四次挥手
Java 设计模式之工厂模式与单例模式
Seal库官方示例(二):encoders.cpp解析
掌握面向对象测试与传统测试模式的区别
Electron+Vue开源软件:洛雪音乐助手V2.8畅享海量免费歌曲
考研算法题练习2022.11.16
强化学习(DQN)教程
maven父工程
【Java牛客刷题】入门篇(03)
数据结构系列-堆排序当中的T-TOK问题
- 原文地址:https://blog.csdn.net/qq_67780151/article/details/126272544