-
【深度学习21天学习挑战赛】4、初尝循环神经网络(RNN)——股票预测
活动地址:CSDN21天学习挑战赛
- 本文为🔗365天深度学习训练营 中的学习记录博客
- 参考文章地址: 🔗深度学习100例-循环神经网络(RNN)实现股票预测 | 第9天
循环神经网络是为了刻画一个序列当前的输出与之前信息的关系。从网络结构上,循环神经网络会记忆之前的信息,并利用之前的信息影响后面结点的输出。
即:循环神经网络的隐藏层之间的结点是有连接的,隐藏层的输入不仅包括输入层的输出,还包括上一时刻隐藏层的输出。
很荣幸通过CSDN21天学习挑战赛学习k同学啊老师的教程,开启自己第一次接触RNN循环神经网络,笔记如下:
完整源码附后
1、简单理解循环神经网络(RNN)
1.1 循环神经网络的基本结构
循环神经网络的基本结构非常简单,就是将网络的输出保存在一个记忆单元中,这个记忆单元和下一次的输入一起进入神经网络中。使用一个简单的两层网络作为示范,在它的基础上扩充为循环神经网络的结构,我们用下图简单表示:

- x是一个向量,它表示输入层的值(这里面没有画出来表示神经元节点的圆圈)
- s是一个向量,它表示隐藏层的值(这里隐藏层面画了一个节点,你也可以想象这一层其实是多个节点,节点数与向量s的维度相同)
- U是输入层到隐藏层的权重矩阵
- o也是一个向量,它表示输出层的值
- V是隐藏层到输出层的权重矩阵
- 权重矩阵W就是隐藏层上一次的值作为这一次的输入的权重
如果我们把上面的图展开,循环神经网络也可以画成下面这个样子:
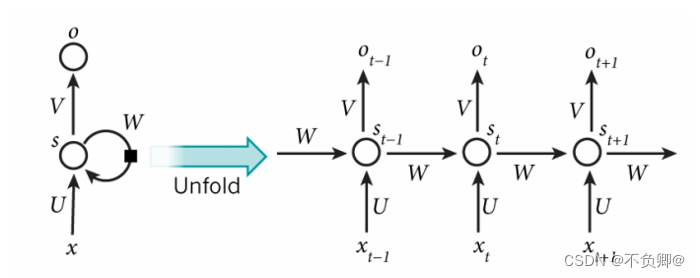
这样看起来就更清楚了:
网络在t时刻接收到输入xt之后,隐藏层的值是st,输出是ot
关键的一点是:st的取值,不仅取决于xt,还取决于st-1
可以用下面公式表示计算方法:

-
式1是输出层的计算公式,输出层是一个全连接层,也就是它的每个节点都和隐藏层的每个节点相连。V是输出层的权重矩阵,g是激活函数。
-
式2是隐藏层的计算公式,它是循环层。U是输入x的权重矩阵,W是上一次的值作为这一次的输入的权重矩阵,f是激活函数。从上面的公式我们可以看出,循环层和全连接层的区别就是循环层多了一个权重矩阵W。
可以看到网络在输入的时候会联合记忆单元s一起作为输入,网络不仅输出结果,还会将结果保存到记忆单元中。当输入序列的顺序发生改变,网络的输出结果就会变化,这是因为记忆单元的存在,使得两个序列在顺序改变之后记忆单元中的元素也改变了,所以会影响最后的输出结果。
1.2 循环层的训练
针对循环层的训练,使用的是BPTT算法,它的基本原理和BP算法是一样的,也包含同样的三个步骤:
- 前向计算每个神经元的输出值;
- 反向计算每个神经元的误差项值,它是误差函数E对神经元j的加权输入的偏导数;
- 计算每个权重的梯度。
最后再用随机梯度下降算法更新权重。具体推导可见:https://zybuluo.com/hanbingtao/note/541458
2、加载数据
加载老师提供的数据
import os,math from tensorflow.keras.layers import Dropout, Dense, SimpleRNN from sklearn.preprocessing import MinMaxScaler from sklearn import metrics import numpy as np import pandas as pd import tensorflow as tf import matplotlib.pyplot as plt # plt支持中文 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 data = pd.read_csv('./SH600519.csv') # 使用pandas的read_csv方法读取股票数据- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

数据:2426行 8列training_set = data.iloc[0:2426 - 300, 2:3].values # 前(2426-300=2126)天的开盘价作为训练集 test_set = data.iloc[2426 - 300:, 2:3].values # 后300天的开盘价作为测试集- 1
- 2
3、数据预处理
3.1 归一化
sc = MinMaxScaler(feature_range=(0, 1)) training_set = sc.fit_transform(training_set) test_set = sc.transform(test_set)- 1
- 2
- 3
MinMaxScaler使用方法:
导包:from sklearn.preprocessing import MinMaxScaler
参数:feature_range:tuple (min, max), default=(0, 1)- feature_range: 归一化后的数据范围,默认将数据转化至[0,1]区间
- copy:拷贝数据,默认为True, 如果输入数据是numpy array格式,设置false,可不复制数据。
fit_transform和transform的区别: - fit_transform():用自己的最小值和最大值进行归一化
- transform() : 在对测试集上的数据进行归一化时,使用的是训练集的最小值和最大值
3.2 设置训练集和测试集
x_train = [] y_train = [] x_test = [] y_test = [] """ 使用前60天的开盘价作为输入特征x_train 第61天的开盘价作为输入标签y_train for循环共构建2426-300-60=2066组训练数据。 共构建300-60=260组测试数据 """ for i in range(60, len(training_set)): x_train.append(training_set[i - 60:i, 0]) y_train.append(training_set[i, 0]) for i in range(60, len(test_set)): x_test.append(test_set[i - 60:i, 0]) y_test.append(test_set[i, 0]) # 对训练集进行打乱 np.random.seed(7) np.random.shuffle(x_train) np.random.seed(7) np.random.shuffle(y_train) tf.random.set_seed(7)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
4、构建模型
model = tf.keras.Sequential([ SimpleRNN(100, return_sequences=True), #布尔值。是返回输出序列中的最后一个输出,还是全部序列。 Dropout(0.1), #防止过拟合 SimpleRNN(100), Dropout(0.1), Dense(1) ])- 1
- 2
- 3
- 4
- 5
- 6
- 7
5、配置模型
# 该应用只观测loss数值,不观测准确率,所以删去metrics选项,一会在每个epoch迭代显示时只显示loss值 model.compile(optimizer=tf.keras.optimizers.Adam(0.001), loss='mean_squared_error') # 损失函数用均方误差- 1
- 2
- 3
6、训练模型
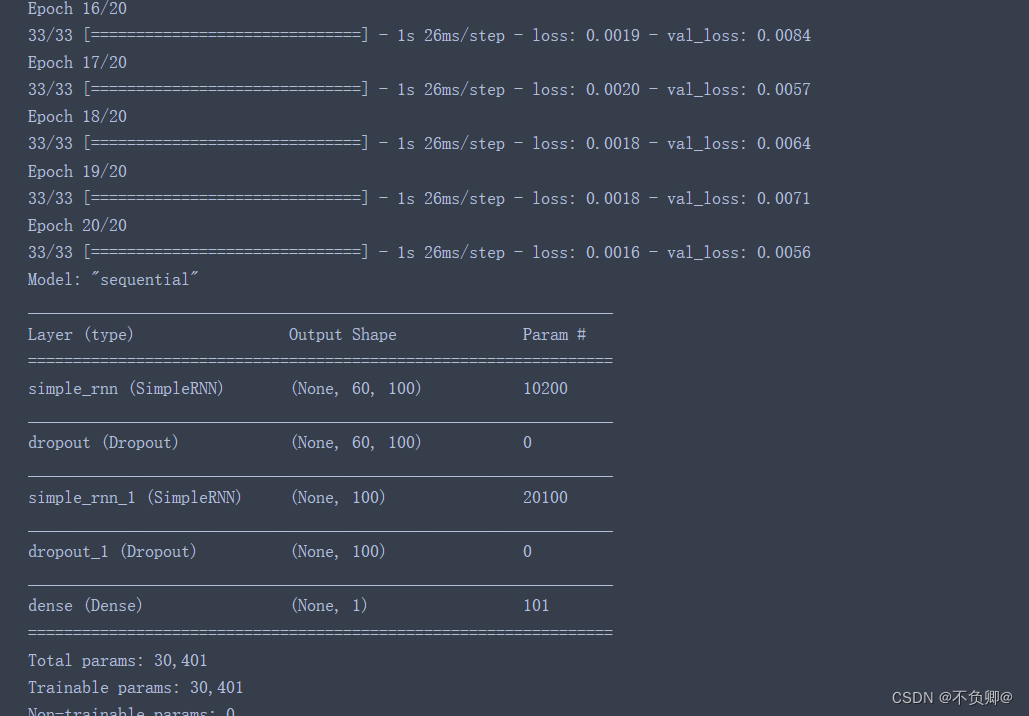
history = model.fit(x_train, y_train, batch_size=64, epochs=20, validation_data=(x_test, y_test), validation_freq=1) #测试的epoch间隔数 model.summary()- 1
- 2
- 3
- 4
- 5
- 6
- 7
训练报错解决
报错如下:NotImplementedError: Cannot convert a symbolic Tensor (sequential_10/simple_rnn_20/strided_slice:0) to a numpy array. This error may indicate that you're trying to pass a Tensor to a NumPy call, which is not supported- 1

解决:
将numpy版本降一下,就可以了,我这里是降到:1.18.5

7、结果可视化
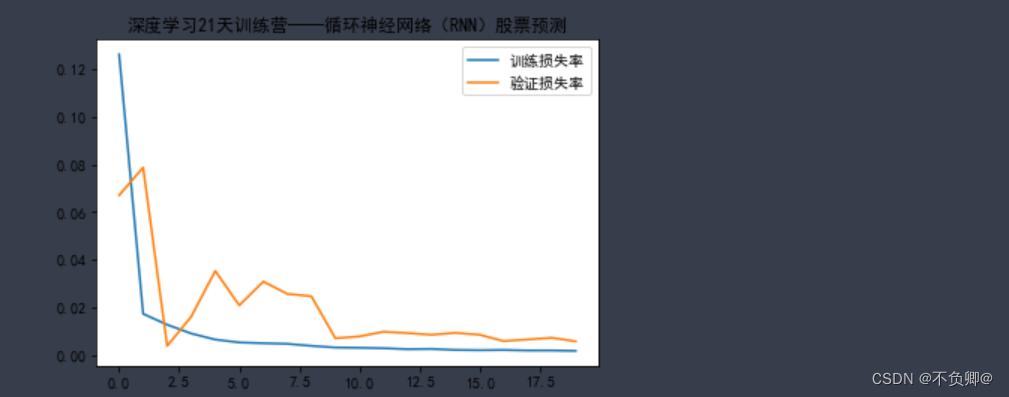
plt.plot(history.history['loss'] , label='训练损失率') plt.plot(history.history['val_loss'], label='验证损失率') plt.title('深度学习21天训练营——循环神经网络(RNN)股票预测') plt.legend() plt.show()- 1
- 2
- 3
- 4
- 5
8、预测
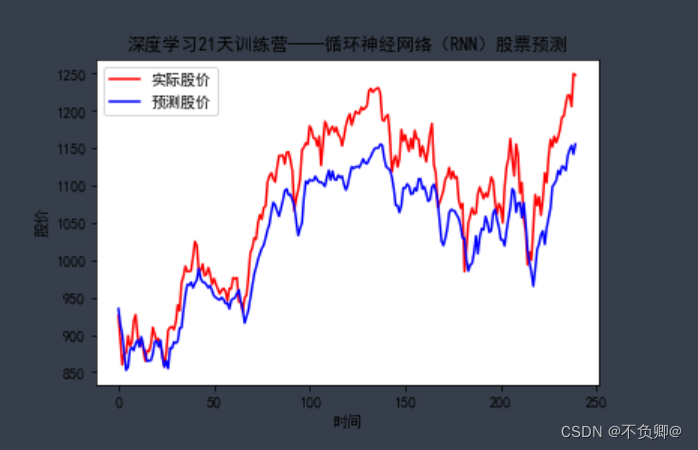
predicted_stock_price = model.predict(x_test) # 测试集输入模型进行预测 predicted_stock_price = sc.inverse_transform(predicted_stock_price) # 对预测数据还原---从(0,1)反归一化到原始范围 real_stock_price = sc.inverse_transform(test_set[60:]) # 对真实数据还原---从(0,1)反归一化到原始范围 # 画出真实数据和预测数据的对比曲线 plt.plot(real_stock_price, color='red', label='实际股价') plt.plot(predicted_stock_price, color='blue', label='预测股价') plt.title('深度学习21天训练营——循环神经网络(RNN)股票预测') plt.xlabel('时间') plt.ylabel('股价') plt.legend() plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
9、评估
""" MSE :均方误差 -----> 预测值减真实值求平方后求均值 RMSE :均方根误差 -----> 对均方误差开方 MAE :平均绝对误差-----> 预测值减真实值求绝对值后求均值 R2 :决定系数,可以简单理解为反映模型拟合优度的重要的统计量 详细介绍可以参考文章:https://blog.csdn.net/qq_38251616/article/details/107997435 """ MSE = metrics.mean_squared_error(predicted_stock_price, real_stock_price) RMSE = metrics.mean_squared_error(predicted_stock_price, real_stock_price)**0.5 MAE = metrics.mean_absolute_error(predicted_stock_price, real_stock_price) R2 = metrics.r2_score(predicted_stock_price, real_stock_price) print('均方误差: %.5f' % MSE) print('均方根误差: %.5f' % RMSE) print('平均绝对误差: %.5f' % MAE) print('R2: %.5f' % R2)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17

完整源码
import os,math from tensorflow.keras.layers import Dropout, Dense, SimpleRNN from sklearn.preprocessing import MinMaxScaler from sklearn import metrics import numpy as np import pandas as pd import tensorflow as tf import matplotlib.pyplot as plt # 支持中文 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 data = pd.read_csv('./SH600519.csv') # 使用pandas的read_csv方法读取股票数据 training_set = data.iloc[0:2426 - 300, 2:3].values # 前(2426-300=2126)天的开盘价作为训练集 test_set = data.iloc[2426 - 300:, 2:3].values # 后300天的开盘价作为测试集 sc = MinMaxScaler(feature_range=(0, 1)) training_set = sc.fit_transform(training_set) test_set = sc.transform(test_set) # 定义四个列表变量 x_train = [] y_train = [] x_test = [] y_test = [] """ 使用前60天的开盘价作为输入特征x_train 第61天的开盘价作为输入标签y_train for循环共构建2426-300-60=2066组训练数据。 共构建300-60=260组测试数据 """ for i in range(60, len(training_set)): x_train.append(training_set[i - 60:i, 0]) y_train.append(training_set[i, 0]) for i in range(60, len(test_set)): x_test.append(test_set[i - 60:i, 0]) y_test.append(test_set[i, 0]) # 对训练集进行打乱 np.random.seed(7) np.random.shuffle(x_train) np.random.seed(7) np.random.shuffle(y_train) tf.random.set_seed(7) """ 将训练数据调整为数组(array) 调整后的形状: x_train:(2066, 60, 1) y_train:(2066,) x_test :(240, 60, 1) y_test :(240,) """ x_train, y_train = np.array(x_train), np.array(y_train) # x_train形状为:(2066, 60, 1) x_test, y_test = np.array(x_test), np.array(y_test) """ 输入要求:[送入样本数, 循环核时间展开步数, 每个时间步输入特征个数] """ x_train = np.reshape(x_train, (x_train.shape[0], 60, 1)) x_test = np.reshape(x_test, (x_test.shape[0], 60, 1)) model = tf.keras.Sequential([ SimpleRNN(100, return_sequences=True), #布尔值。是返回输出序列中的最后一个输出,还是全部序列。 Dropout(0.1), #防止过拟合 SimpleRNN(100), Dropout(0.1), Dense(1) ]) # 该应用只观测loss数值,不观测准确率,所以删去metrics选项,一会在每个epoch迭代显示时只显示loss值 model.compile(optimizer=tf.keras.optimizers.Adam(0.001), loss='mean_squared_error') # 损失函数用均方误差 history = model.fit(x_train, y_train, batch_size=64, epochs=20, validation_data=(x_test, y_test), validation_freq=1) #测试的epoch间隔数 model.summary() plt.plot(history.history['loss'] , label='训练损失率') plt.plot(history.history['val_loss'], label='验证损失率') plt.title('深度学习21天训练营——循环神经网络(RNN)股票预测') plt.legend() plt.show() predicted_stock_price = model.predict(x_test) # 测试集输入模型进行预测 predicted_stock_price = sc.inverse_transform(predicted_stock_price) # 对预测数据还原---从(0,1)反归一化到原始范围 real_stock_price = sc.inverse_transform(test_set[60:]) # 对真实数据还原---从(0,1)反归一化到原始范围 # 画出真实数据和预测数据的对比曲线 plt.plot(real_stock_price, color='red', label='实际股价') plt.plot(predicted_stock_price, color='blue', label='预测股价') plt.title('深度学习21天训练营——循环神经网络(RNN)股票预测') plt.xlabel('时间') plt.ylabel('股价') plt.legend() plt.show() """ MSE :均方误差 -----> 预测值减真实值求平方后求均值 RMSE :均方根误差 -----> 对均方误差开方 MAE :平均绝对误差-----> 预测值减真实值求绝对值后求均值 R2 :决定系数,可以简单理解为反映模型拟合优度的重要的统计量 详细介绍可以参考文章:https://blog.csdn.net/qq_38251616/article/details/107997435 """ MSE = metrics.mean_squared_error(predicted_stock_price, real_stock_price) RMSE = metrics.mean_squared_error(predicted_stock_price, real_stock_price)**0.5 MAE = metrics.mean_absolute_error(predicted_stock_price, real_stock_price) R2 = metrics.r2_score(predicted_stock_price, real_stock_price) print('均方误差: %.5f' % MSE) print('均方根误差: %.5f' % RMSE) print('平均绝对误差: %.5f' % MAE) print('R2: %.5f' % R2)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
学习日记
1,学习收获
第一次尝试了循环神经网络
尝试思考和解决中途遇到的问题
尝试摸索学习LSTM2,学习遇到的问题
继续恶补基础
-
相关阅读:
云计算时代的运维: 职业发展方向与岗位选择
solidity部署和验证代理合约
网站如何应对网络流量攻击
VMware Workstation 15 安装教程
Jetson-AGX-Orin gstreamer+rtmp+http-flv 推拉流
Qt中的事件学习笔记
AC修炼计划(AtCoder Regular Contest 180) A~C
计算机网络安全隔离之网闸、光闸
2. Java变量
相机-景深
- 原文地址:https://blog.csdn.net/m0_48300767/article/details/126264861
