-
redis 面试整理
redis
1 AOF 和 RDB 持久化
- RDB 是以快照的形式把内存里的数据生成一个 RDB 格式备份文件,定时保存。保存的是数据的压缩过数据结构
- 有两个命令 SAVE、BGSAVE 可以生成 RDB 文件,SAVE 会阻塞主服务进程,直到 RDB 文件创建完毕。BGSAVE 则是派生一个子进程去执行 RDB 的生成
- RDB 会在 redis 启动时被加载,没有特殊加载命令
- 适合冷备份。对于灾难恢复而言,RDB 是非常不错的选择。RDB 是经过压缩的数据,体积小
- 恢复更快。相比于 AOF 机制,RDB 的恢复速度更更快,更适合恢复数据,特别是在数据集非常大的情况
- AOF 的实现可以分为三个步骤:命令追加(append)、文件写入、文件同步(sync)
- redis 执行一个写命令时,会以协议格式将命令追加到 aof_buf 的缓冲区末尾
- 在 redis 的事件循环执行周期,处理文件事件时,则会考虑是否将 aof_buf 缓冲区的数据写入到 AOF 文件。这其中有三种策略:
- 1-always aof_buf 数据全部同步到 AOF 文件
- 2-everysec 每秒同步一次
- 3-no 不同步
- 默认是 everysec 策略
- 如果 AOF 日志过大,redis 会启用 rewrite 机制。在 rewrite log 时,会对其中的指令进行压缩,创建出一份需要恢复数据的最小日志出来。可使用 BGREWRITEAOF 命令 fork 子进程单独处理,不会影响 redis 主进程
- AOF 的同步频率比 RDB 的同步频率高,如果同时开启 AOF 和 RDB,redis 优先选择 AOF 同步文件
2 redis 的 acid 特性
- redis 的事务需要先划分出三个阶段
- 事务开启,使用 MULTI 可以标志着执行该命令的客户端从非事务状态切换至事务状态
redis> MULTI - 命令入队,MULTI开启事务之后,非 WATCH、EXEC、DISCARD、MULTI 等特殊命令;客户端的命令不会被立即执行,而是放入一个事务队列
- 执行事务或者丢弃。如果收到 EXEC 的命令,事务队列里的命令将会被执行。如果是 DISCARD 则事务被丢弃
- 事务开启,使用 MULTI 可以标志着执行该命令的客户端从非事务状态切换至事务状态
redis> WATCH "name" OK redis> MULTI ### 此时name已被其他客户端的命令修改 OK redis> SET "name" "lwl" QUEUED redis> EXEC (nil)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 原子性: 事务的异常会发生在EXEC命令执行前、后
- EXEC命令执行前:在命令入队时就报错,(如内存不足,命令名称错误),redis 就会报错并且记录下这个错误。此时,客户还能继续提交命令操作;等到执行
EXEC时,redis 就会拒绝执行所有提交的命令操作,返回事务失败的结果 nil - EXEC命令执行后:命令和操作的数据类型不匹配,但 redis 实例没有检查出错误。在执行完 EXEC 命令以后,redis 实际执行这些指令,就会报错。此时事务是不会回滚的,但事务队列的命令还是继续被执行。事务的原子性无法保证
- EXEC执行时,发生故障:如果 redis 开启了 AOF 日志,那么,只会有部分的事务操作被记录到 AOF 日志中。需要使用 redis-check-aof 工具检查 AOF 日志文件,这个工具可以把未完成的事务操作从 AOF 文件中去除。事务的原子性得到保证
- EXEC命令执行前:在命令入队时就报错,(如内存不足,命令名称错误),redis 就会报错并且记录下这个错误。此时,客户还能继续提交命令操作;等到执行
- 持久性
- 如果 redis 没有使用 RDB 或 AOF,事务的持久化是不存在的
- 使用 RDB 模式,那么在一个事务执行后,而下一次的 RDB 快照还未执行前,如果发生了实例宕机,数据丢失,这种情况下,事务修改的数据也是不能保证持久化
- AOF 模式,因为 AOF 模式的三种配置选项 no、everysec 和 always 都会存在数据丢失的情况。所以,事务的持久性属性也还是得不到保证
- 一致性
- EXEC命令执行前:入队报错事务会被放弃执行,具有一致性
- EXEC命令执行后:实际执行时报错,错误的执行不会执行,正确的指令可以正常执行,一致性可以保证
- EXEC执行时,发生故障:RDB 模式,RDB 快照不会在事务执行时执行,事务结果不会保存在RDB;AOF 模式,可以使用 redis-check-aof 工具检查 AOF 日志文件,把未完成的事务操作从 AOF 文件中去除。可以保证一致性
- 隔离性
- EXEC 命令前执行,隔离性需要通过 WATCH 机制保证。因为 EXEC 命令执行前,其他客户端命令可以被执行,相关变量会被修改;但可以使用 WATCH 机制监控相关变量。一旦相关变量被修改,则 EXEC 后则事务失败返回;具有隔离性
- EXEC 命令之后,隔离性可以保证。因为 redis 是单线程执行,事务队列里的命令和其他客户端的命令只能二选一被顺序执行,因此具有隔离性
- redis 的事务机制可以保证一致性和隔离性;但是无法保证持久性;具备了一定的原子性,但不支持回滚
3 redis 为啥这么快,为啥是单线程
- 采用单线程,避免了不必要的上下文切换和竞争条件;不存在多线程导致的切换而消耗CPU
- 不用考虑各种锁的问题,不存在加锁和释放锁的的操作,没有因为可能出现的死锁而导致的性能消耗
- 简单可维护,多线程模式会使得程序的编写更加复杂和麻烦,单线程实现易实现
- 纯内存访问,所有数据都在内存中,所有的运算都是内存级别的运算,内存响应时间的时间为纳秒级别。因此 redis 进程的 cpu 基本不存在磁盘 I/O 等待时间、内存读写性能问题,CPU 不是 redis 的瓶颈(内存大小和网络I/O 才是 redis 的瓶颈,也就是客户端和服务端之间的网络传输延迟)
- 采用单线程模型,单线程实现简单。避免了多线程频繁上下文切换,以及同步机制如锁带来的开销
- 简单高效的基础数据结构:动态字符串(SDS),链表,字典,跳跃链表,整数集合和压缩列表。然后 redis 在这个基础上去实现用户能操作的对象:字符串,列表,哈希,集合,有序集合等对象
- reactor 模式的网络事件处理器。它使用了 I/O 多路复用去同时监控多个套接字,这是一种高效的I/O模型。
4 网络模型和事件机制
- redis 处理快,不单单因为它是个单线程纯内存系统,还有它采用了 Reactor 模型,使用 I/O 多路复用来实现对外部请求的处理,减少网络连接、读写等待时间。
- 使其在网络 I/O 操作中能并发处理大量的客户端请求,实现高吞吐率,高并发
5 redis 的主从同步
- 全量同步
- 主从库间建立连接、协商同步。从库向主库发送 psync 命令,告诉它要进行数据同步。主库收到 psync 命令后,响应 FULLRESYNC 命令(它表示第一次复制采用的是全量复制),并带上主库当前的 runid 和主库目前的复制进度 offset
- 主库根据 判断需要全量同步,执行 bgsave 命令,生成 RDB 文件,接着将文件发给从库。从库接收到 RDB 文件后,会先清空当前数据库,然后加载 RDB 文件
- 如果从库请求命令是
PSYNC ? -1则进行全量同步 - 如果是runid和主节点的runid不一致则进行全量同步
- 如果runid和主节点runid 一致,但是offset不在复制积压缓存区(repl_backlog_buffer)范围内,则进行全量同步
- 如果从库请求命令是
- 主库把数据同步到从库的过程中,新来的写操作,会记录到 replication buffer
- 主库完成 RDB 发送后,会把replication buffer中的修改操作发给从库,从库再重新执行这些操作
- 增量同步:
- 如果从库 psync命令中的 runid 和主库 runid 一致,且 offset 在 repl_backlog_buffer 复制积压缓存区找得到,进行增量同步。把数据从复制积压缓冲区同步到从节点
- 复制积压缓冲区一个主节点只有一个,即是是多个从节点也只有一个,而且只有存在从节点的时候才会创建复制积压缓冲区
- 命令同步
- 当主节点收到命令的时候,会把命令在复制积压缓冲区 repl_backlog_buffer 缓存一份,以便部分同步使用
6 有哪几种基础数据结构
- 底层数据 SDS、字典、跳跃链表、整数集合、压缩链表、链表
- string
- 内部编码有3种,int(8字节长整型)/embstr(小于等于39字节字符串)/raw(大于39个字节字符串)
- set
- intset(整数集合)、hashtable(哈希表)
- zset
- ziplist(压缩列表)、skiplist(跳跃表)
- list
- ziplist(压缩列表)、linkedlist(链表)
- hash
- 内部编码:ziplist(压缩列表) 、hashtable(哈希表)
7 使用场景
- 缓存: 合理的利用缓存,比如缓存热点数据,不仅可以提升网站的访问速度,还可以降低数据库DB的压力
- 排行榜: Redis提供的zset数据类型能够实现这些复杂的排行榜。
- 计数器: int类型,incr方法。例如:文章的阅读量、微博点赞数、允许一定的延迟,先写入Redis再定时同步到数据库
- 共享Session: Redis 是分布式的独立服务,可以在多个应用之间共享 session
- 分布式锁: setnx 和 set ex | px nx
- 消息队列: List提供了两个阻塞的弹出操作:blpop/brpop
- 位操作: bitmap
- 全局ID:int类型,incrby,利用原子性
8 淘汰策略
- no-eviction:redis 不再继续提供写请求 (DEL 请求可以,读请求也可以)。这可以保证不会丢失数据,但是会让线上的业务不能持续进行,这是默认的淘汰策略
- volatile-lru:尝试淘汰设置了过期时间的 key,最近最少使用的 key 优先被淘汰。没有设置过期时间的 key 不会被淘汰,这样可以保证需要持久化的数据不会突然丢失(使用最多)
- volatile-ttl:跟上面一样,只是优先淘汰剩余过期时间 ttl 的最小的 key,ttl 越小越先被淘汰
- volatile-lfu:从所有配置了过期时间的 key 中淘汰使用频率最少的键
- volatile-random:从设置了过期时间的 key 中淘汰数据
- allkeys-lru:区别于 volatile-lru,这个策略要淘汰的 key 对象是全体的 key 集合,而不只是过期的 key 集合
- allkeys-random:从所有键中随机淘汰 key
- allkeys-lfu:从所有键中淘汰使用频率最少的键
9 DB 和 缓存的数据一致性问题
- 数据库和缓存中间关于数据的更新问题:一是先更新缓存呢,还是删除缓存?二是先操作缓存还是 DB ? 两个问题组合起来就有四种方案了
- 方案1 先更新缓存后更新DB:这个方案基本不可能会被采用的。因为更新DB失败,缓存里数据就是异常数据
- 方案2 先更新 DB 后更新缓存
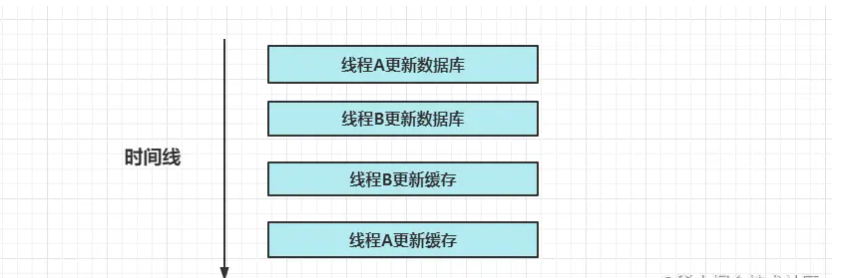
- 网络问题可能会导致线程B更新缓存比线程A更快,而在第四步完成之后,缓存失效之前,缓存和数据库就会存在不一致性问题。需要等待缓存失效才行
- 方案3 先删缓存后更新DB
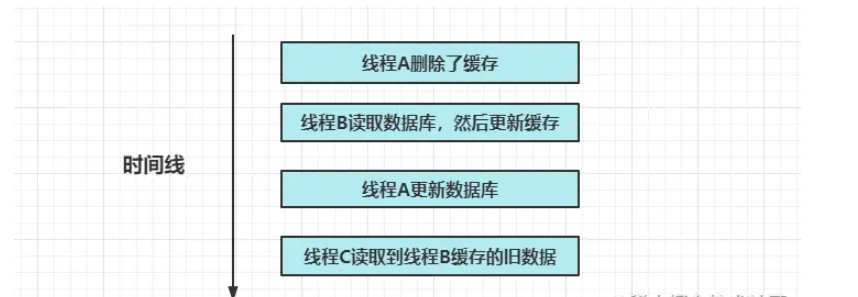
- 和 方案二的效果一样,存在短暂的不一致行
- 方案4 先更新DB后删缓存

- 该方案也是不能完美解决不了数据的不一致性,但是数据不一致的概率会小很多
- 实际场景会使用方案4 + 延迟删除的操作,来降低DB和缓存的不一致性

- 延迟删除失败,怎么补救。删除失败可以加入消息队列进行重试
10 缓存穿透、缓存雪崩、缓存击穿
- 缓存穿透:缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求
- 采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被 这个bitmap拦截掉,从而避免了对底层存储系统的查询压力
- 从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒
- 缓存击穿:缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),此时并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据
- 设置热点数据永远不过期
- 加跟新互斥锁
- 缓存雪崩:大面积的缓存失效,无法命中
- 设置热点数据永远不过期
- 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生
- 如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中
- 加锁或者队列的方式保证缓存的单线 程(进程)写,从而避免失效时大量的并发请求落到底层存储系统上
11 redis 实现分布式锁的几种方式
- 方案一 setnx + expire
- 失效时间可能会设置失败
- 存在锁过期,业务还在执行
- 方案二 setnx + value 值是过期时间
- 过期时间是客户端自己生成的,分布式环境下,每个客户端的时间必须同步
- 没有保存持有者的唯一标识,可能被别的客户端释放/解锁
- 存在锁过期,业务还在执行
- 拓展命令
set key value [expiration EX seconds|PX milliseconds] [NX|XX]- EX seconds:将键的过期时间设置为 seconds 秒。
- PX millisecounds:将键的过期时间设置为 milliseconds 毫秒。
- NX:只在键不存在的时候,才对键进行设置操作。
- XX:只在键已经存在的时候,才对键进行设置操作
- 方案三 set的扩展命令(set ex|px nx)
- 缺点:锁过期释放了,业务还没执行完
- 锁被别的线程误删
- 方案四 set ex | px nx + 校验唯一随机值 value,再删除
- 缺点:锁过期释放了,业务还没执行完
- 方案五 redission
- Redisson 可以解决 锁过期释放,业务没执行完的问题
- 只要线程一加锁成功,就会启动一个watch dog看门狗,它是一个后台线程,会每隔10秒检查一下,如果线程1还持有锁,那么就会不断的延长锁key的生存时间。因此,Redisson就是使用Redisson解决了锁过期释放,业务没执行完问题
- 方案六 Redlock
- redis 如果是单 master 的,线程 A 在Redis的master节点上拿到了锁,但是加锁的key还没同步到slave节点。恰好这时,master节点发生故障,一个slave节点就会升级为master节点。线程 B 就可以获取同个key的锁啦,但线程 A 也已经拿到锁了,锁的安全性就没了
- 多个Redis master部署,以保证它们不会同时宕掉。并且这些master节点是完全相互独立的,相互之间不存在数据同步
- 然后在多台 Redis master 同时请求加锁,但加锁 redis 机器超过一半。并且加锁使用的时间小于锁的有效期,则加锁成功。
12 哨兵模式
- 哨兵其实是一个运行在特殊模式下的 Redis 进程。它有三个作用,分别是:监 控、自动选主切换(简称选主)、通知
- 监控 master和slave 不断的检查master和slave是否正常运行,master存活检测、master与slave运行情况检测
- 当被监控的服务器出现问题时,向其他哨兵、Redis服务器发送通知
- 断开宕机的master与slave的连接,选取一个slave作为master,将其他slave连接新的master,并告知客户端新的服务器地址
- 监控
- 哨兵进程向主库、从库发送 PING 命令,如果主库或者从库没有在规定的时间内响 应 PING 命令,哨兵就把它标记为主观下线。
- 如果是主库被标记为主观下线,则正在监视这个主库的所有哨兵要以每秒一次的频 率,以确认主库是否真的进入了主观下线。 当有多数的哨兵(一般少数服从多数, 由 Redis 管理员自行设定的一个值)在指定的时间范围内确认主库的确进入了主观下线状态,则主库会被标记为客观下线。这样做的目的就是避免对主库的误判, 以减少没有必要的主从切换,减少不必要的开销
- 如果一个实例节点距离最后一次有效回复 PING 命令的时间超过
down-after-milliseconds选项所指定的值, 则这个实例会被哨兵标记为主观下线 - 当有足够数量的哨兵(大于等于配置文件指定的值)在指定的时间范围内确认主库的确进入了主观下线状态, 则主库会被标记为客观下线
- 哨兵选主
- 由哪个哨兵执行主从切换呢
- 主库会被标记 为客观下线。标记主库客观下线的这个哨兵,紧接着向其他哨兵发送命令,再发起投票,希 望它可以来执行主从切换。这个投票过程称为 Leader 选举。因为最终执行主从切换的哨兵称为 Leader,投票过程就是确定 Leader。一个哨兵想成为Leader 需要满足两个条件:
- 需要拿到 num(sentinels)/2+1 的赞成票
- 并且拿到的票数需要大于等于哨兵配置文件中的 quorum 值
- 故障转移
- 哨兵在服务器列表中挑选备选 master 的原则:先排除,后选择
- 不在线的OUT
- 响应慢的OUT
- 与原master断开时间久的OUT
- 排除结束,开始进行选择
- 优先级高的获选
- offset较大的获选(比较大说明同步原来master的数据最多)
- 若还没有选出,则最后根据 runid 选出
- 选出新的master之后,哨兵发送指令给服务器:
- 向新的master发送
slaveof no one指令 - 向其他slave发送 slaveof 新 masterIP 端口指令
- 向新的master发送
- 同时还要告诉其他的哨兵新master是谁
- 哨兵在服务器列表中挑选备选 master 的原则:先排除,后选择
13 Redis 哈希槽的概念
- 一个切片集群被分为16384个slot(槽),每个进入Redis的键值对,根据key进行散列,分配到这16384插槽中的一个。使用的哈希映射也比较简单,用CRC16算法计算出一个16bit的值,再对16384取模。数据库中的每个键都属于这16384个槽的其中一个
- 集群中的每个节点负责一部分的哈希槽,假设当前集群有A、B、C3个节点,每个节点上负责的哈希槽数 =16384/3,那么可能存在的一种分配:
- 节点A负责0~5460号哈希槽
- 节点B负责5461~10922号哈希槽
- 节点C负责10923~16383号哈希槽
14 redis 集群方案 codis 、redis cluster
- Redis Cluster方案采用哈希槽(Hash Slot),来处理数据和实例之间的映射关系。哨兵模式基于主从模式,而Redis Cluster是分布式集群,不同的节点储存不同的数据。Redis Cluster 功能 : 负载均衡,故障切换,主从复制
- MOVED 重定向机制。客户端给一个 Redis 实例发送数据读写操作时,如果计算出来的槽不是在该节点上,这时候它会返回 MOVED 重定向错误,MOVED 重定向错误中,会将哈希槽所在的新实例的 IP 和 port 端口带回
- ASK 重定向。Ask 重定向一般发生于集群伸缩的时候。集群伸缩会导致槽迁移,当我们去源 节点访问时,此时数据已经可能已经迁移到了目标节点,使用 Ask 重定向可以解决此种情况
- Redis Cluster 集群通过 Gossip 协议进行通信,节点之前不断交换信息,交换 的信息内容包括节点出现故障、新节点加入、主从节点变更信息、slot 信息等
- 主观下线和客观下线
- 主观下线: 某个节点认为另一个节点不可用,即下线状态,这个状态并不是最终的故障判定
- 客观下线: 指标记一个节点真正的下线,集群内多个节点都认为该节点不可用,从而达成共识的结果。如果是持有槽的主节点故障,需要为该节点进行故障转移
- 故障转移
- 故障发现后,如果下线节点的是主节点,则需要在它的从节点中选一个替换它,以保证集群的高可用
- 对 slaver 节点的资格进行检查,只有难过检查的从节点才可以开始进行故障恢复
- master的 slaver 节点收到 fail 消息后开始竞选成为 master。竞选的方式跟sentinel选主的方式类似,都是使用了raft协议,slave会从其他的master拉取选票,票数最多的slave被选为新的master,新master会马上给集群内的其他节点发送pong消息,告知自己角色的提升。其他slave接着开始复制新master
15 redis 写丢失的场景
- 前面有说redis是不能保证持久性,如果机器突然死机,写入的数据是不一定持久到磁盘的,此时存在写丢失
- 主从复制数据不一致,发生故障切换后,出现数据丢失
- 网络分区时,Redis集群或哨兵在判断故障切换的时间窗口,这段时间写入到原主库的数据
16 redis 集群如何选择数据库
- 只能选择 0 的数据库
17 Redisson 的 watch log 自动延长机制
- 如果拿到分布式锁的节点宕机,且这个锁正好处于锁住的状态时,会出现锁死的状态,为了避免这种情况的发生,锁都会设置一个过期时间。这样也存在一个问题,加入一个线程拿到了锁设置了30s超时,在30s后这个线程还没有执行完毕,锁超时释放了,就会导致问题
- Redisson 提供了一个监控锁的看门狗,它的作用是在Redisson实例被关闭前,不断的延长锁的有效期,也就是说,如果一个拿到锁的线程一直没有完成逻辑,那么看门狗会帮助线程不断的延长锁超时时间,锁不会因为超时而被释放。
- 默认情况下,看门狗的续期时间是30s,也可以通过修改Config.lockWatchdogTimeout来另行指定
18 redis 集群的哈希槽为啥是 16384 个
- 如果槽位是 65536,发送心跳信息的消息头达到 8K 。 65536 / 8 / 1024 = 8kb
- redis 集群节点一般不会超过1000,16384 够用了
- 槽位越小,节点少的情况下压缩率高。它所负责的哈希槽是通过一张bitmap的形式来保存的,在传输过程中,会对bitmap进行压缩
- RDB 是以快照的形式把内存里的数据生成一个 RDB 格式备份文件,定时保存。保存的是数据的压缩过数据结构
-
相关阅读:
从零开始的 dbt 入门教程 (dbt core 命令进阶篇)
连接到EC2,开启root登录
kubeflow核心功能
CTFHub-Web-密码口令-弱口令
【AI可视化---04】点亮数据之旅:发现Matplotlib的奇幻绘图世界!用Python挥洒数据音符的创意乐章——这四篇就够了!
《商业银行信息科技风险管理指引》
C语言--用二分法快速计算指定整数的整数平方根
[vmware]vmware虚拟机压缩空间清理空间
Windows与网络基础-18-注册表基础
对 JavaBean 的特点写法与实战心得详解
- 原文地址:https://blog.csdn.net/u013591094/article/details/126263717