-
自学Python 52 多线程开发(二)使用Lock和RLock 对象
Python 使用Lock和 RLock 对象
活动地址:CSDN21天学习挑战赛
本篇在Python 多线程开发(一)的基础上,继续讲解Python多线程开发的相关内容。
一、使用Lock和 RLock 对象
如果多个线程共同对某个数据进行修改,则可能出现不可预料的结果。为了保证数据的正确性,需要对多个数据进行同步操作。在Python程序中,使用对象Lock 和 RLock可以实现简单的线程同步功能,这两个对象都有acquire方法和release方法,对于那些需要每次只允许一个线程操作的数据,可以将其操作放到acquire和 release方法之间。多线程的优势在于可以同时运行多个任务(至少感觉起来是这样),但是当线程需要共享数据时,可能存在数据不同步的问题。
读者考虑一个问题,有没有这样一种情况:一个列表里所有元素都是0,线程“set”从后向前把所有元素改成1,而线程“print”负责从前往后读取列表并打印。那么,可能当线程“set”开始改的时候,线程“print”便来打印列表了,输出就变成了一半0一半1,这就造成了数据的不同步。
为了避免这种情况,引入了锁的概念。锁有两种状态,分别是锁定和未锁定。每当一个线程比如“set”要访问共享数据时,必须先获得锁定;如果已经有别的线程比如“print”获得锁定了,那么就让线程“set”暂停,也就是同步阻塞;等到线程“print”访问完毕,释放锁以后,再让线程“set”继续。经过上述过程的处理,打印列表时要么全部输出0,要么全部输出1,不会再出现一半0一半1的尴尬场面。由此可见,使用 threading模块中的对象 Lock和 RLock(可重入锁),可以实现简单的线程同步功能。对于同一时刻只允许一个线程操作的数据对象,可以把操作过程放在Lock和 RLock 的acquire方法和 release方法之间。RLock可以在同一调用链中多次请求而不会锁死,Lock则会锁死。
例如在下面的实例中,演示了使用RLock 实现线程同步的过程。import threading #导入模块threading import time #导入模块time class mt(threading.Thread): #定义继承于线程类的子类mt def run(self): #定义重载函数run global x #定义全局变量x lock.acquire() #在操作变量之前锁定资源 for i in range (5): #遍历操作 x += 10 #设置变量x值加10 time.sleep (1) #休眠1秒钟 print (x) #打印输出×的值 lock.release() #释放锁资源 x = 0 #设置x值为 lock = threading.RLock() #实例化可重入锁类 def main(): thrs = [] #初始化一个空列表 for item in range(8): thrs.append(mt()) #实例化线程 for item in thrs: item.start() if __name__ == '__main__': #启动线程 main()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
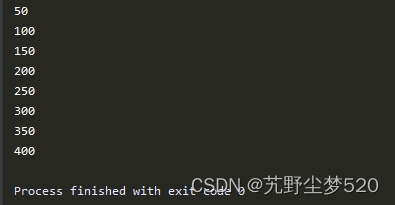
在上述实例代码中,自定义了一个带锁访问全局变量x的线程类mt,在主函数main()中初始化了8个线程来修改变量x,在同一个时刻只能由一个线程对x进行操作。执行后会输出:
-
相关阅读:
万应低代码CTO胡艳平:浅谈低代码在中大型企业数字化转型中的应用
arm push/pop/b/bl汇编指令
ps2021没法用神经元滤镜,ps2021神经滤镜不能下载
java计算机毕业设计翔隆生鲜超市进货管理系统源程序+mysql+系统+lw文档+远程调试
Linux:深入文件系统
【第三篇】商城系统-基础业务-实现类别管理
Rancher 2.6 全新 Logging 快速入门(2)
HTTP简介
数据库-MySQL
java毕业设计基于的测试项目管理平台Mybatis+系统+数据库+调试部署
- 原文地址:https://blog.csdn.net/weixin_46066007/article/details/126257443