-
【Kafka消息队列】生产者发送消息流程
如何描述一条消息?
如何描述一条消息,就是在问这条消息的数据结构是什么?
public class ProducerRecord- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
一条消息被抽象成ProducerRecord对象,其中topic表示主题,可以理解为一级目录。partition表示分区,属于主题下的二级目录。key表示路由的键,如果指定了key就相当于指定了分区。value表示消息体,最终的消息就是存在value中。
如何描述生产者?
Properties properties = new Properties(); properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,“xxx:8080”); //broker的地址 //指定序列化器 properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); //指定过滤器 可配置多个用逗号隔开 properties.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,"org.apache.kafka.clients.producer.SzzProducerInterceptorsTest"); //指定分区器(默认) properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"o.a.k.clients.producer.internals.DefaultPartitioner"); //构造 KafkaProducer KafkaProducer producer = new KafkaProducer(properties);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Properties 是一个map对象,只需要将配置放进propeties。KafkaProducer构造函数通过解析producer.propeties文件里面的属性来构造自己。例如 :分区器、Key和Value序列化器、拦截器、RecordAccumulator消息累加器 、元信息更新器、启动发送请求的后台线程。
消息是怎么发送的?

拦截器
拦截器的执行在序列化和分区之前。

拦截器需要在Properties进行配置,配置后才能起到拦截作用。序列化器
Producer需要将消息对象序列化成二进制数组,然后才能通过网络传输至Broker,消费者通过反序列化,将消息转换成消息对象。

Producer的序列化器和Consumer的反序列化器必须一致。否则解析会出问题。分区器
分区器将消息进行路由,进而存储在相同topic下的不同分区,相同分区的消息是有序的,分区是实现负载均衡的一种策略,如下图所示。
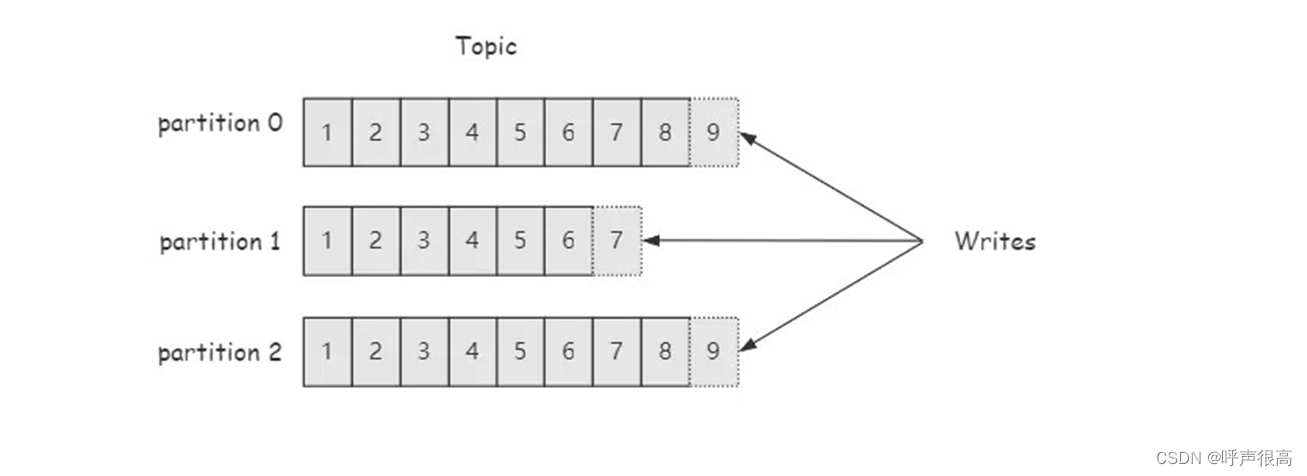
分区策略
在消息对象数据结构中,有一个属性是partition,一旦指定了partition(也就是指定了分区),那么消息会不经过分区器直接将消息塞进指定的partition。
如果未指定partition,则按照key将消息路由至某个分区。至于是哪个分区,则要看使用的什么路由策略,常见的路由策略是轮询或者哈希。如果key为null,则路由策略为轮询,将消息轮询至某个分区。如果key不为null,则路由策略为哈希,通过对key取哈希值,然后对partition的总数取模(该topic下的partition总数),取模后的值即是消息的要塞进的分区。
消息缓冲池
经过拦截器、分区器、序列化器以后的二进制消息并不是直接发送到broker,而是暂时放入消息缓冲池(recordAccumulator)中,
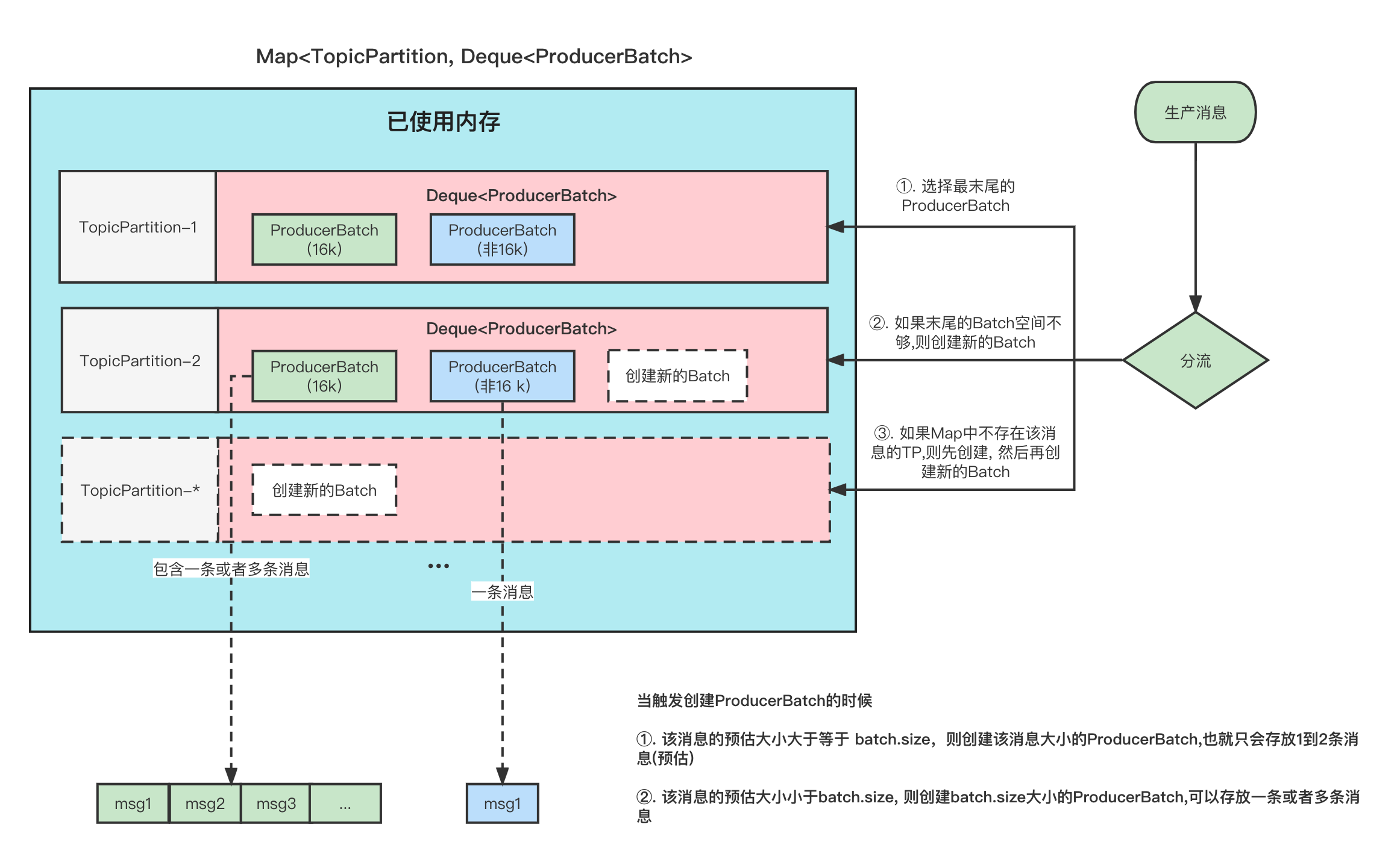
按照TopicPartition维度,创建队列(Deque),同理topic和Partition会被放在同一个队列里。
ProducerBatch 是队列中的元素结构,表示同一个批次发送的消息,大小为16k,能够存储一条或多条消息。
消息分流进缓冲池的流程
当一个消息进入缓冲池中,首先按照消息的TopicPartition找到指定的队列, 然后取队列中的最后一个元素(ProducerBatch),ProducerBatch的剩余内存能够塞下,则塞下这条消息,如果不能,则创建一个新的ProducerBatch。Sender线程启动

sender是一个异步的IO线程,在获取Metadata时就已经唤醒。sender线程会循环轮询查看缓冲池中每个队列中ProducerBatch是否满足发送条件。sender将ProducerBatch发送后等待broker的response,然后调用回调函数。
-
相关阅读:
自动化发布npm包小记
【Verilog基础】“与/或/非”门级电路实现“2选1MUX”、“4选1MUX”、“8选1MUX”、“异或门”、“半加器”
十年架构五年生活-04第一个工作转折点
OpenCV14-图像平滑:线性滤波和非线性滤波
MySQL - 权限表
Java BufferedWriter.write()具有什么功能呢?
超详细介绍如何使用 OpenCV 和 BGS 库进行背景扣除
Mind2Web: Towards a Generalist Agent for the Web 论文解读
医学YOLOv8 | 脑肿瘤检测 Accuracy 99%
C++之AVL树
- 原文地址:https://blog.csdn.net/hu2535357585/article/details/126238904