-
数据在内存中的存储
一、数据类型
数据类型有7种:
char 字符型 short 短整型 int 整型 long 长整型 long long 更长整型 float 单精度浮点数 double 双精度浮点数- 1
- 2
- 3
- 4
- 5
- 6
- 7
二、原码,反码,补码
计算机中的整数有三种2进制表示方法,即原码、反码和补码。
三种表示方法均有符号位和数值位两部分,符号位都是用0表示’正”,用1表示"负”,而数值位正数的原、反、补码都相同。
负整数的三种表示方法各不相同.
原码:是直接将数值按照正负数的形式翻译成二进制得到原码。
反码:原码的符号位不变,其他位依次按位取反得到反码。
补码:反码加1,得到补码。
计算例子:如图
计算a+b:
a是正数,原码等于补码:00000000 00000000 00000000 00000111
b是负数,原码:10000000 00000000 00000000 00001010
反码:111111111 11111111 11111111 11110101
补码:11111111 11111111 11111111 11110110
a+b的补码分别相加得到:11111111 11111111 11111111 11111101
而打印的是%d即有符号整型,要把它转化为原码,减一取反的到原码:
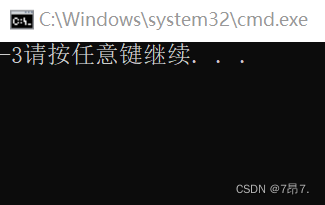
10000000 00000000 00000000 00000011 再化为10进制就是-3
看下运行结果:
三、大小端
数据在内存中有两种存储方式一个是大端模式一个是小端模式。
在计算机系统中,以字节为单位的,每个地址单元对应着一个字节,一个字节为8bit。但在C语言中除了8 bit的char之外,还有16 bit的short型,32bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于奇存器宽度大于一个字节,那么心然存在着一个如何将多个字节安排的问题。这导致了大端存储模式和小端存储模式。
我们如何判断当前机器的字节顺序:#includeint is_sys() { int a = 1; return (*(char *)&a); } int main() { int ret = is_sys(); if (ret == 1) { printf("小端\n"); } else { printf("大端\n"); } return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
取一个整型数1,补码:0000000 0000000 00000000 00000001,要判断它哪种存储模式,只需要拿出第一个字节,因为低位放在高地址处时是大端,低位放在低地址处时小端,取地址先转化为字符型指针保证拿出一个字节 ,再解引用取出内容,如果是1就是小端,反之是大端。
整型提升
C的整型算术运算总是至少以缺省整型类型的精度来进行的。为了获得这个精度,表达式中的字符和短整型操作数在使用之前被转换为普通整型,这种转换称为整型。
我们用字符类型存储数据会发生截断,因为一个数是四个字节,字符型只能存储一个字节,截断之后看当前符号位:
对于有符号类型,如果是1就把1之前的位补全1进行整型提升,如果是0就把0之前的位补全0进行整型提升。
对于无符号类型,直接补全0.
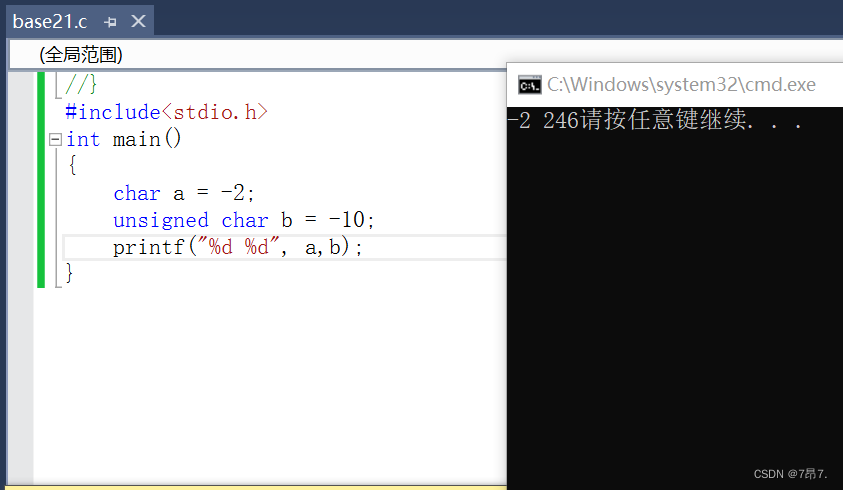
(1)我们看如下例子就能很好理解:#includeint main() { char a = -2; unsigned char b = -10; printf("%d %d", a,b); } - 1
- 2
- 3
- 4
- 5
- 6
- 7
a=-2,原码:10000000 0000000 00000000 00000010
反码: 11111111 11111111 11111111 11111101
补码: 11111111 11111111 11111111 11111110
但是a是字符型只能存一个字节,会发生截断只取低位的一个字节即:11111110
而我们打印的是有符号整型%d,会发生整型提升,因为它是负的,所以在前面补1
11111111 11111111 11111111 11111110,而打印的是原码,所以再转换为原码。减一取反:10000000 00000000 00000000 00000010 结果是-2
b=-10,原码:10000000 00000000 00000000 00001010
反码: 11111111 11111111 11111111 11110101
补码 :11111111 11111111 11111111 11110110
同上截断之后:11110110 因为他是无符号整型在前面补0:
00000000 00000000 00000000 11110110.直接是原码打印结果是246.
再验证下结果:
(2)另外%u是打印无符号整型。也是被截断之后看原来的数是否有符号,如果有符号不补1或补0,无符号直接补0.然后补完之后直接当做原码打印
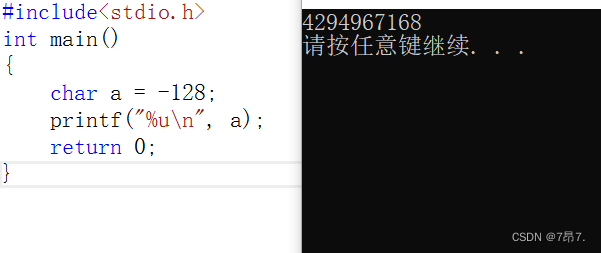
例如 char=-128
原码:10000000 00000000 00000000 10000000
反码: 11111111 11111111 11111111 01111111
补码: 11111111 11111111 11111111 10000000
因为是字符型拿低位的一个字节 1000000,又因为他是负数补1:
11111111 11111111 11111111 10000000,直接当原码打印 因数太大直接看结果:
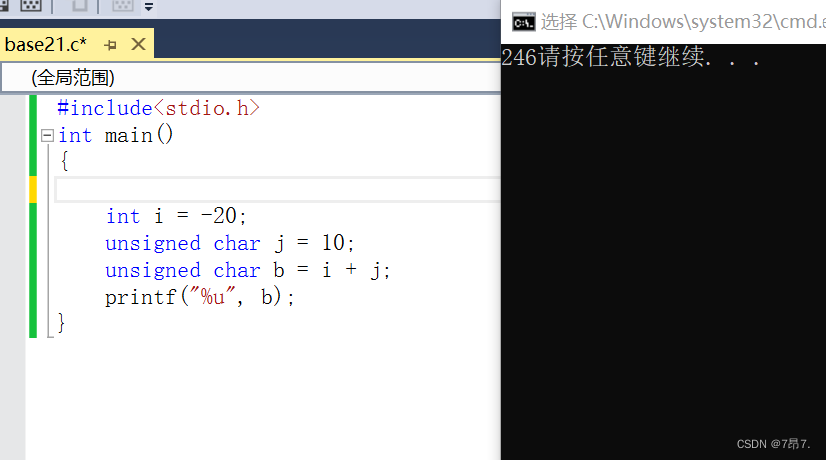
(3)再来分析一个:#includeint main() { int i = -20; unsigned char j = 10; unsigned char b = i + j; printf("%u", b); } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
i的原码:10000000 00000000 00000000 00010100;
反码: 11111111 1111111 11111111 11101011
补码: 11111111 11111111 11111111 11101100
而j是无整形且字符型值 因为它是正数,原码等于补码:
00000000 00000000 00000000 00001010
两者相加是:11111111 11111111 11111111 11110110
而又存在一个无符号字符型,发生截断:11110110
而打印的是%u直接整型提升补0 补码等于原码 :
00000000 00000000 00000000 11110110结果是246
看结果:
-
相关阅读:
【编程题】【Scratch四级】2019.12 太空大战
怎么把heic改成jpg?方法大全在这里
java MINio 操作工具类
【遗留】等待谁来帮助一下,webSocket的messagingTemplate跨域问题
文献解读|植物对低温胁迫的反应:低温胁迫改变了大白菜的抗氧化代谢能力
商城项目环境准备 — docker安装kinaba和配置ik中文分词器
计算机网络数据链路层知识总结
基于javaweb的嘟嘟网上商城系统(java+jdbc+jsp+mysql+ajax)
一文学会如何使用建造者模式
mysql锁机制
- 原文地址:https://blog.csdn.net/m0_59292239/article/details/126253968
