论文信息
论文标题:DropEdge: Towards Deep Graph Convolutional Networks on Node Classification
论文作者:Yu Rong, Wenbing Huang, Tingyang Xu, Junzhou Huang
论文来源:2020, ICLR
论文地址:download
论文代码:download
1 Introduction
由于 2022 年的论文看不懂,找了一篇 2020 的论文缓解一下心情,我太难了。
提出一种可以缓解过拟合、过平滑的策略,并且和 其他 backbone 模型组合将得到更好的性能。
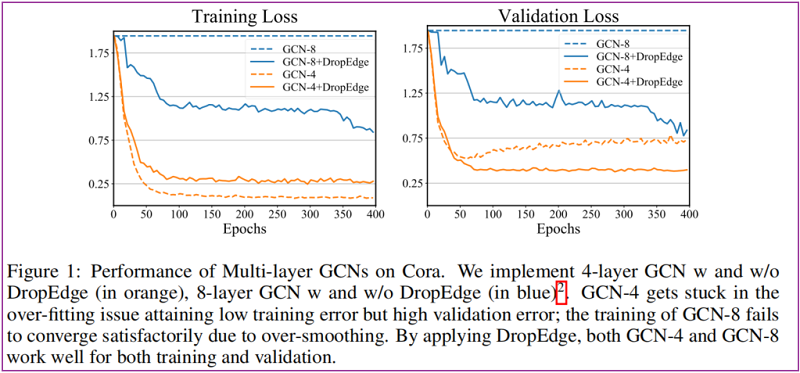
验证小图上容易出现过平滑现象:参见 Figure 1 Cora 数据集上使用 8 层 GCN 的结果。
DropEdge 主要思想是:在每次训练时,随机删除掉原始图中固定比例的边。
在GCN训练过程中应用DropEdge有许多好处:
- DropEdge 可以看成是数据增强技术。在训练过程中对原始图中的边进行不同的随机删除,也就增强了输入数据的随机性和多样性,可以缓解过拟合的问题。
- DropEdge 还可以看成是一个消息传递减少器。GCNs中,邻接节点间的消息传递是通过连边实现的,随机删除掉一些边就可以让节点连接更加稀疏,在一定程度上避免了GCN层数加深引起的过平滑问题。
2 Preliminary
GCN
前向传播层为:
H(l+1)=σ(ˆAH(l)W(l))(1)
其中,ˆA=ˆD−1/2(A+I)ˆD−1/2
3 Method
3.1 Methodlogy
在每个训练 epoch,DropEdge 技术随机删除输入图的一定边。形式上,它随机地强制邻接矩阵 A 的 Vp 非零元素为零,其中 V 是边的总数,p 是丢弃率。如果我们将得到的邻接矩阵表示为 Adrop,那么它与 A 的关系就变成了
Adrop=A−A′(2)
其中 A′ 是原始图中删除的边集,然后对 Adrop 进行 re-normalization 得到 ˆAdrop ,替换 Eq.1 中的 ˆA。
DropEdge 对图中的连接带来了扰动,它对输入数据产生了不同的随机变形,可以看成是数据增强。
GCNs 的核心思想是对每个节点的邻居特征进行加权求和,实现对邻居信息的聚合。那么 DropEdge 可以看成在 GNN 训练时使用的是随机的邻居子集进行聚合,而没有使用所有的邻居。若 DropEdge 删边率为 p,对邻居聚合的期望是由 p 改变的,在对权重进行归一化后就不会再使用 p。
上述所说的是每个 epoch ,GNN 各层共享一个 Adrop 但每层也可以单独进行 DropEdge,为数据带来更多的随机性。
Note:同样,类似的还有可以为每层单独计算 KNN graph。
下文将阐述 DropEdge 如何缓解过平滑问题,并且假设使用的所有层将共用一个 Adrop 。
3.2 Preventing over-smoothing
过平滑原始定义:平滑现象意味着随着网络深度的增加,节点特征将收敛到一个固定的点。这种不必要的收敛限制了深度GCNs的输出只与图的拓扑相关,但与输入节点特征无关,这会损害 GCNs 的表达能力。
通过考虑非线性和卷积滤波器的思想,可以将过平滑解释为收敛到子空间,而不是收敛到不动点,本文将使用子空间概念来更具普遍性。
首先给出如下定义:

根据 Oono & Suzuki 的结论,足够深的GCN在一些条件下,对于任意小的 ϵ 值,都会有 ϵ−smoothing 问题。他们只是提出了深度 GCN 中存在 ϵ−smoothing,但是没有提出对应的解决方法。
-
- 降低节点之间的连接,可以降低过平滑的收敛速度;
- 原始空间和子空间的维度之差衡量了信息的损失量;
即:

4 Discussions
DropEdge vs. Dropout
Dropout 试图通过随机设置特征维数为零来干扰特征矩阵,可能会减少过拟合的影响,但对防止过平滑没有帮助,因为它不会对邻接矩阵做出任何改变;
DropEdge 可以看成 Dropout 向图数据的推广,将删除特征换成删除边,两者是互补关系;
DropNode 采样子图进行小批量训练,可被视为删除边的一种特定形式,因为连接到删除节点的边也被删除。然而,DropNode 对删除边的影响是面向节点的和间接的。
DropEdge 是面向边的,并且可以保留训练的所有节点特征,表现出更多的灵活性。
当前的 DropNode 方法中的采样策略通常是低效的,例如,GraphSAGE 的层大小呈指数增长,而 AS-GCN 需要逐层递归地进行采样。然而,DropEdge 既不随着深度的增长而增加图层的大小,也不要求递归进程,因为所有边的采样都是平行的。
DropEdge vs Graph-Sparsification
图稀疏化(1997) 的优化目标是去除图压缩的不必要的边,同时保留输入图的几乎所有信息。这和 DropEdge 的目的一样,但不同的是 DropEdge 不需要具体的优化目标,而图稀疏化则采用一种繁琐的优化方法来确定要删除哪些边,一旦这些边被丢弃,输出图将保持不变。
5 Experiment
数据集

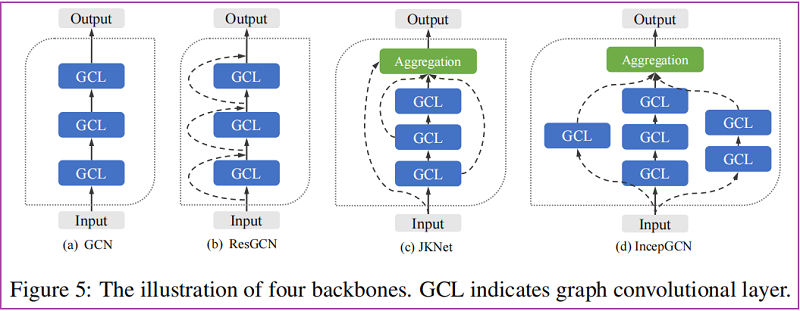
Backbones
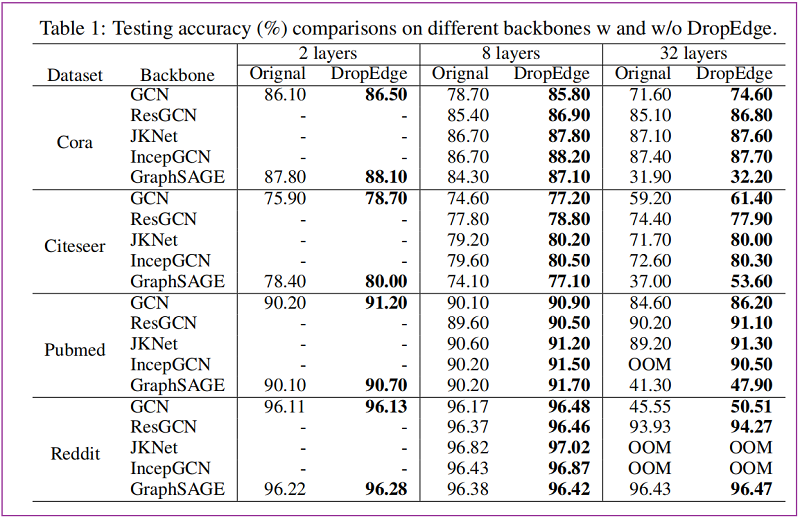
节点分类:(监督学习)
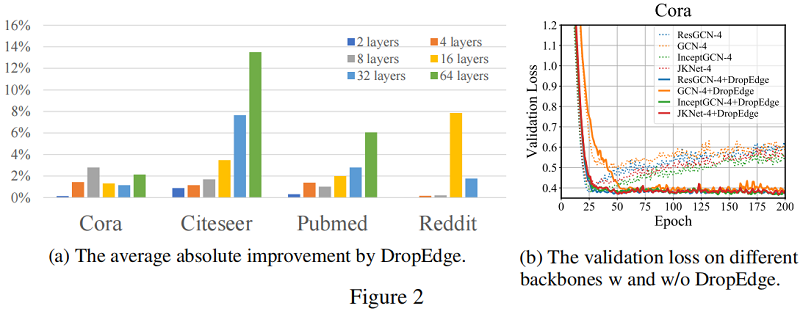
验证损失
标准化/传播模型

6 Conclusion
DropEdge 在输入数据中包含了更多的多样性,以防止过拟合,并减少了图卷积中的消息传递,以缓解过平滑。
__EOF__
