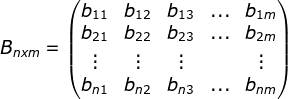-
Chapter 15 HMM模型
1.1 定义
隐马尔科夫模型:可用于标注问题,在语音识别、NLP、生物信息、模式识别等领域被实践证明是有效的算法。
HMM是关于时序的概率模型,描述由一个隐藏的马尔科夫链生成不可观测的状态随机序列,再由各个状态生成观测随机序列的过程。(生成模型)
隐马尔科夫模型随机生成的状态随机序列,称为状态序列;每个状态生成一个观测,由此产生的观测随机序列,称为观测序列。
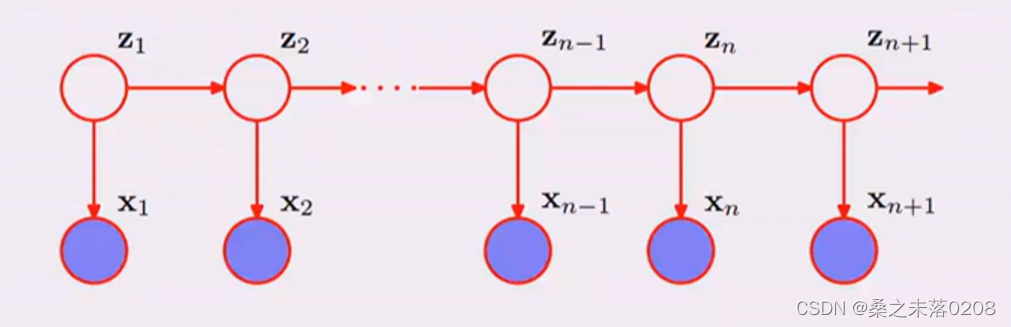
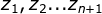 是主题,我们需要通过词来确定的对象。
是主题,我们需要通过词来确定的对象。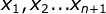 是词,我们所观察的对象。
是词,我们所观察的对象。在
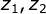 不可观察的前提下,
不可观察的前提下,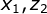 独立。如下图,将右侧部分看作一个整体,作为X’。因此就可以当作贝叶斯网络。当
独立。如下图,将右侧部分看作一个整体,作为X’。因此就可以当作贝叶斯网络。当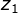 不可观察时,
不可观察时,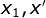 相互独立。
相互独立。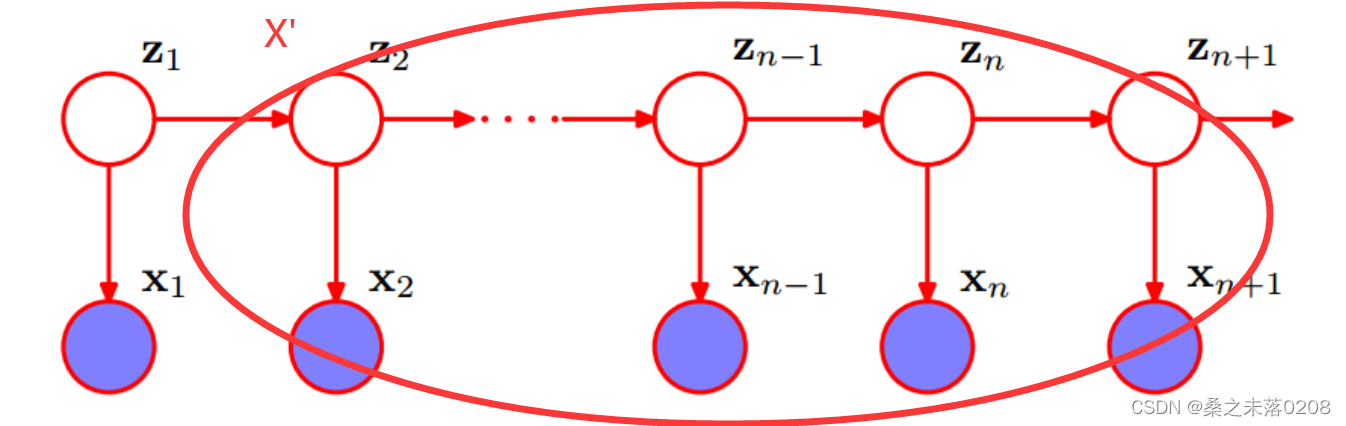
1.2 HMM模型的确定
HMM由初始概率分布
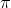 、状态转移概率分布A以及观测概率分布B确定。
、状态转移概率分布A以及观测概率分布B确定。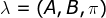
Q是所有可能的状态的集合;N是可能的状态数
V是所有可能的观测的集合;M是可能的观测数
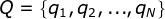
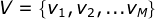
参数分析:
- I是长度为T的状态序列,O是对应的观测序列:
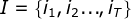 ,
,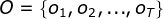
- 隐状态:
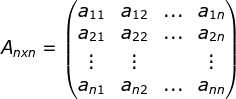 ,其中
,其中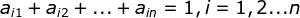
其中
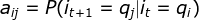 是在时刻t处于状态
是在时刻t处于状态 的条件下时刻t+1转移到状态的概率。
的条件下时刻t+1转移到状态的概率。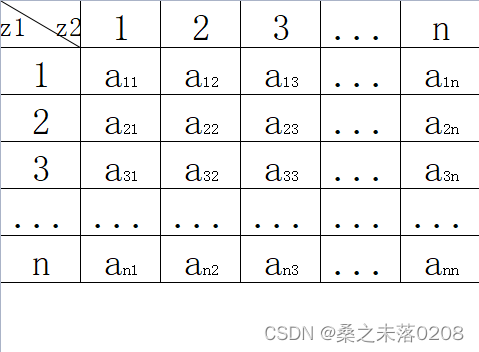
ps: 隐状态必须是离散的。
可观测序列,值是连续或者离散的都可以。
n——隐状态的个数 m——可观测的个数
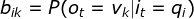 是在时刻t处于状态的条件下生成观测
是在时刻t处于状态的条件下生成观测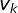 的概率。
的概率。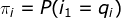 是时刻t=1处于状态的概率。
是时刻t=1处于状态的概率。- 总结:HMM由初始概率分布(向量)、状态转移概率分布A(矩阵)以及观测概率分布B(矩阵)确定。和A决定状态序列,B决定观测序列。因此,HMM可以用三元符号表示,称为HMM的三要素:
1.3 HMM的两个基本性质
(1)齐次假设:
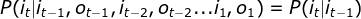
(2)观测独立性假设:
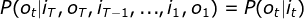
1.4 HMM的实例

问题:求解最终得到{红、白、红}的概率?
设置各个参数如下:
状态集合:Q={盒子1,盒子2,盒子3}观测集合:V={红,白}
状态序列和观测序列的长度为:T=3+2=5
初始概率分布:
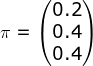
状态转移概率分布:
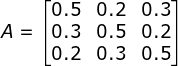
观测概率分布:

求解:见1.6
1.5 HMM的3个基本问题
- 概率计算问题(重点):前向-后向算法——动态规划
给定模型
和观测序列,计算模型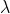 下观测序列O出现的概率
下观测序列O出现的概率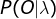 。
。- 学习问题:Baum-Welch算法(状态未知)——EM
已知观测序列
,估计模型的参数,使得在该模型下观测序列最大。- 预测问题:Viterbi算法——动态规划
解码问题:已知模型
和观测序列,求给定观测序列条件概率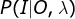 最大的状态序列
最大的状态序列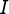 。
。1.6 概率计算问题
- 直接计算(暴力算法)
按照概率公式,列举所有可能的长度为T的状态序列
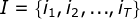 ,\,求各个状态序列I和观测序列
,\,求各个状态序列I和观测序列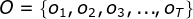 的联合概率
的联合概率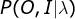 ,然后对所有可能的状态序列求和,从而得到。
,然后对所有可能的状态序列求和,从而得到。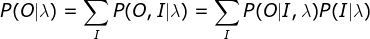


- 前向算法
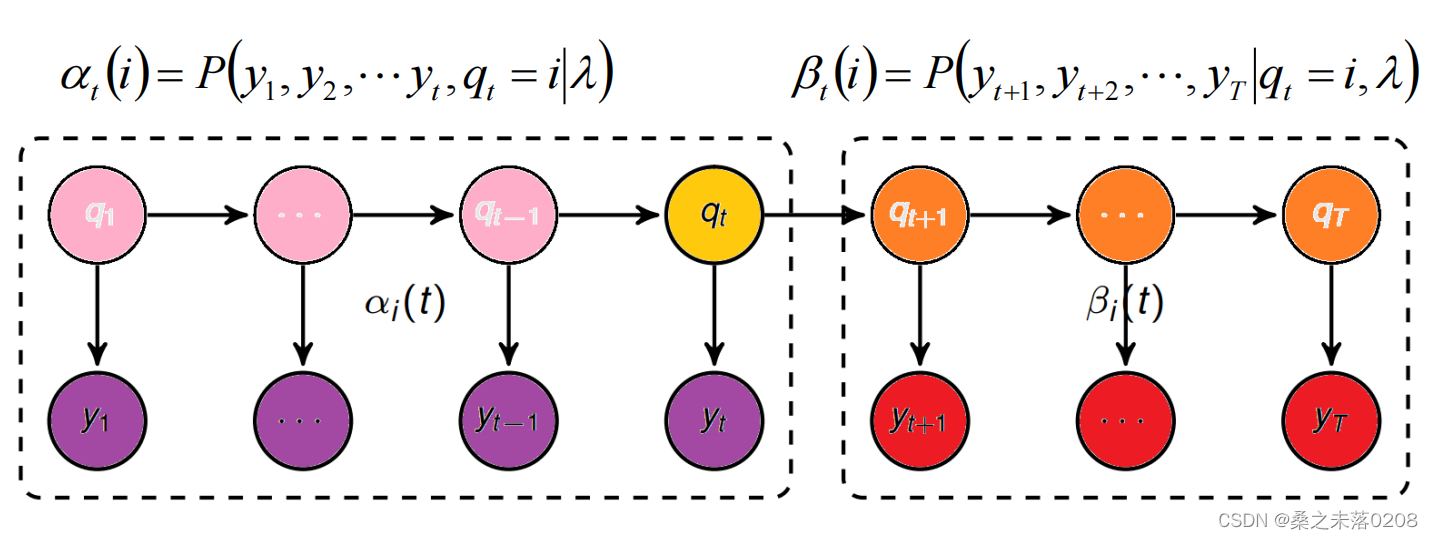
前向算法的定义:给定
,定义到时刻t部分观测序列为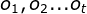 ,且状态为的概率称为前向概率,记作:
,且状态为的概率称为前向概率,记作: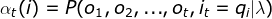
计算观测序列概率
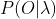 :
:(1)初值:
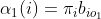
(2)递推:对于
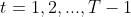 ,
,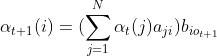
(3)最终:
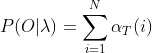
时间复杂度是
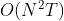
1.4实例可以通过前向算法求解:

(1)计算初值
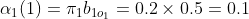
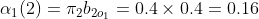
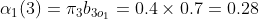
(2)递推
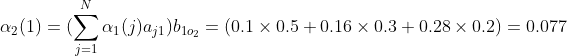
同理:
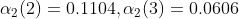
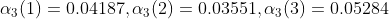
(3)最终
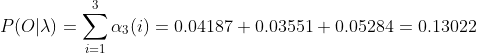
- 后向算法
给定
,定义到时刻t状态为qi的前提下,从t+1到T的部分观测时序为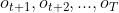 的概率为后向概率,记作:
的概率为后向概率,记作: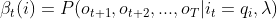
计算观测序列概率
:(1) 初值
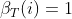
(2)递推,对于t=T-1,T-2,...,1,
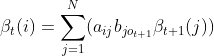
(4)最终:
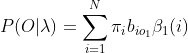
- 前向概率、后向概率的关系
1.7 单个状态的概率
求给定模型
和观测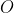 ,在时刻t处于状态qi的概率:
,在时刻t处于状态qi的概率:记作:
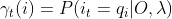
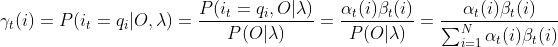
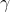 的意义为:在每个时刻t选择在该时刻最有可能出现的状态
的意义为:在每个时刻t选择在该时刻最有可能出现的状态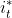 ,从而得到一个状态序列
,从而得到一个状态序列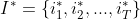 将它作为预测的结果。
将它作为预测的结果。例如:对于一句话“今天我吃了一个火龙果”,划分词是可能出现的状态有(begin,mid,end,single)
若这么划分词:今天|我|吃|了|一个|火龙果。
则:
begin:“今”,“一”、“火”
mid:“龙”
end:“天”、“个”
single:“我”、“吃”、“了”
期望:在观测O下状态i出现的期望:
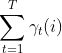
1.8 两个状态的联合概率
求给定模型
和观测,在时刻t处于状态qi的概率并且时刻t+1处于状态qi的概率: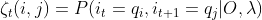
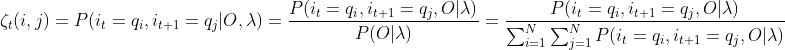
其中:
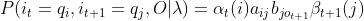
期望:在观测O下状态i转移到状态j的期望:
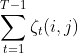
1.9 学习算法
若训练数据包括观测序列和状态序列,则HMM的学习非常简单,是监督学习;
若训练数据只有观测序列,则HMM的学习需要使用EM算法,是非监督学习。
(1)监督学习
假设已经给定训练数据包括S个长度相同的观测序列和对应的状态序列
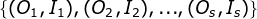 ,那么可以直接利用Bernoulli大数定理的结论“频率的极限是概率”,给定HMM的参数估计。
,那么可以直接利用Bernoulli大数定理的结论“频率的极限是概率”,给定HMM的参数估计。初始概率
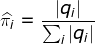
转移概率
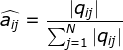
观测概率
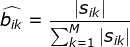
(2)非监督学习
Baum-Welch算法:
所有观测数据为
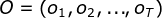 ,所有隐数据为
,所有隐数据为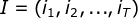 ,完全数据是
,完全数据是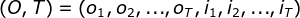 ,完全数据的对数似然函数为
,完全数据的对数似然函数为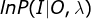 。
。假设
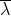 是HMM参数的当前估计值,为待求的参数。
是HMM参数的当前估计值,为待求的参数。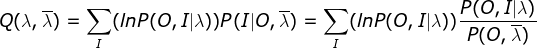
EM过程:
因为
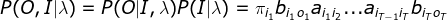
所以
拉格朗日乘子法:
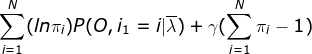 ,其中
,其中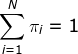
先对
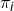 求偏导:
求偏导: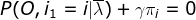
∴
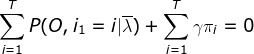
∴
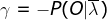
∴初始状态概率为
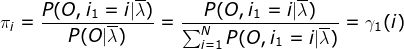
转移概率和观测概率:

1.10 Viterbi算法
Viterbi算法实际是用动态规划解HMM预测问题,用DP求概率最大的路径(最优路径),这是一条路径对应一个状态序列。
定义变量
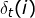 :在时刻t状态为i的所有路径中,概率的最大值。
:在时刻t状态为i的所有路径中,概率的最大值。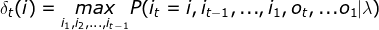
递推:
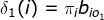
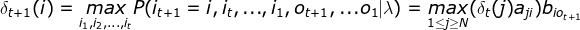
终止:
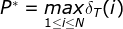
1.11 举例




-
相关阅读:
LeetCode_二分搜索_中等_2594.修车的最少时间
5.10.WebRTC接口宏
DETR纯代码分享(三)coco_panoptic.py
IB课程 EE怎么写?
C++ Reference: Standard C++ Library reference: Containers: list: list: ~list
CF1286E-Fedya the Potter Strikes Back【KMP,RMQ】
Java项目:SSM校园共享自行车出租管理系统
7.10 操作系统的启动
paddleocr关闭log日志打印输出
linux mysql5.7.25 主从复制_生产版本
- 原文地址:https://blog.csdn.net/qwertyuiop0208/article/details/126224190