-
机器学习算法——聚类1(性能度量——外部指标Jaccard系统,FM指数,Rand指数;内部指标:DB指数,Dunn指数)
1.聚类简介
在“无监督学习”中,训练样本的标记信息是未知的,目标是通过对无标记训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础。此类学习任务中研究最多、应用最广的是“聚类”。
聚类将数据集中的样本划分为若干个通常不相交的子集,每个子集称为一个“簇”(类别)。聚类过程仅能自动形成簇结构,簇所对应的概念语义需由使用者来把握和命名。
形式化表达如下:
假定样本集
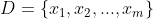 包含m个无标记的样本,每个样本
包含m个无标记的样本,每个样本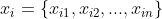 是一个n维特征向量,则聚类算法将样本集D划分为k个不相交的簇
是一个n维特征向量,则聚类算法将样本集D划分为k个不相交的簇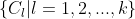 ,其中
,其中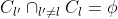 且
且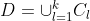
相应地,用
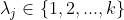 表示样本
表示样本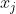 的“簇标记”,即
的“簇标记”,即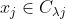
则,聚类的结果可用包含m个元素的簇标记向量
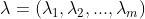 表示。
表示。聚类既能作为一个单独过程,用于寻找数据内在的分布结构,也可作为分类等其他学习任务的前驱过程。
2. 聚类的性能度量
聚类性能度量亦称聚类“有效性指标”。对聚类结果,我们需通过某种性能度量来评估其好坏;另一方面,若明确了最终将要使用的性能度量,则可直接将其作为聚类过程的优化目标,从而更好地得到符合要求的聚类结果。
什么样的聚类结果比较好呢?我们希望物以类聚,即同一簇的样本尽可能彼此相似,不同簇的样本尽可能不同。换言之,聚类结果的“簇内相似度高”且“簇间相似度低”。
聚类性能指标大致有两类:一类是将聚类结果与某个“参考模型”进行比较,称为“外部指标”。
另一类是直接考察聚类结果而不利用任何参考模型,称为“内部指标”。
对数据集
,假定通过聚类给出的簇划分为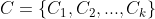 ,参考模型给出的簇划分为
,参考模型给出的簇划分为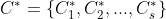 。相应地,令
。相应地,令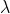 与
与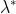 分别表示与C和
分别表示与C和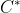 对应的簇标记向量。我们将样本两两配对考虑,定义
对应的簇标记向量。我们将样本两两配对考虑,定义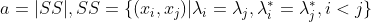
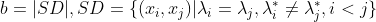
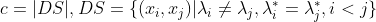
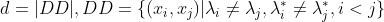
其中
集合SS包含了C中隶属于相同簇且在
中也隶属于相同簇的样本对集合SD包含了C中隶属于相同簇但在
中隶属于不同簇的样本对由于每个样本对
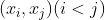 仅能出现在一个集合中,因此有
仅能出现在一个集合中,因此有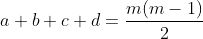
基于上述式子,可导出下面这些常用的聚类性能度量外部指标:
- Jaccard系数(简称JC,用于比较有限样本集之间的相似性与差异性,JC系数越大,样本相似度越高):
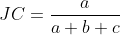
- FM指数(简称FMI)
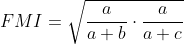
- Rand指数(简称RI)
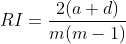
显然,上述性能度量的结果值均在[0,1]区间,值越大越好。
考虑聚类结果的簇划分
,定义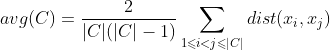
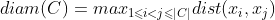
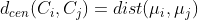
其中,dist(.,.)用于计算两个样本之间的距离;
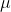 代表簇C的中心点
代表簇C的中心点 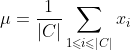
avg(C)对应于簇C内样本间的平均距离
diam(C)对应于簇C内样本间的最远距离
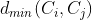 对应于簇
对应于簇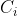 与簇
与簇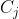 最近样本间距离
最近样本间距离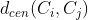 对应于簇与簇中心点间的距离
对应于簇与簇中心点间的距离基于上式可导出常用的聚类性能度量内部指标:
- DB指数(简称DBI)
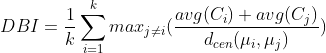
- Dunn指数(简称DI)
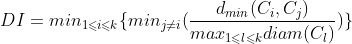
显然DBI的值越小越好, DI的值越大越好。‘;
-
相关阅读:
Element-UI框架下拉选择框el-select选择全部时,回显的是数字-1
2023年中国高性能材料手模市场发展趋势分析:替代效应将逐步显现[图]
python+vue驾校驾驶理论考试模拟系统
【无标题】一种超级终端防火墙
APP测试面试题汇总(基础篇、进阶篇)
曝 15 寸 iPad 或将变身 Mac?谷歌:大屏设备应具备智能手机体验
鸿蒙Harmony应用开发—ArkTS声明式开发(组件可见区域变化事件)
C语言中的函数openlog
Linux的命令行
最详细的CompletableFuture使用详解,附上代码示例
- 原文地址:https://blog.csdn.net/Vicky_xiduoduo/article/details/126235309