-
pytorch调整模型学习率
1.定义衰减函数
定义learning rate衰减方式:
L R e p o c h = L R 0 × 0. 8 e p o c h + 1 10 LR_{epoch}=LR_{0}\times 0.8^{\frac{epoch+1}{10}} LRepoch=LR0×0.810epoch+1import matplotlib.pyplot as plt from torch import nn import math from torch import optim class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.net = nn.Linear(10,10) def forward(self, input): out = self.net(input) return out learning_rate = 1e-3 L2_DECAY = 5e-4 MOMENTUM = 0.9 def step_decay(epoch, learning_rate): """ Schedule step decay of learning rate with epochs. """ initial_learning_rate = learning_rate drop = 0.8 epochs_drop = 10.0 learning_rate = initial_learning_rate * math.pow(drop, math.floor((1 + epoch) / epochs_drop)) return learning_rate model = Net() LR = 0.01 lr_list = [] for epoch in range(100): current_lr = step_decay(epoch, learning_rate) optimizer = torch.optim.SGD(model.parameters(), lr=current_lr) lr_list.append(current_lr) plt.plot(range(100), lr_list, color = 'r') plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
绘出的lr更新曲线如下所示:
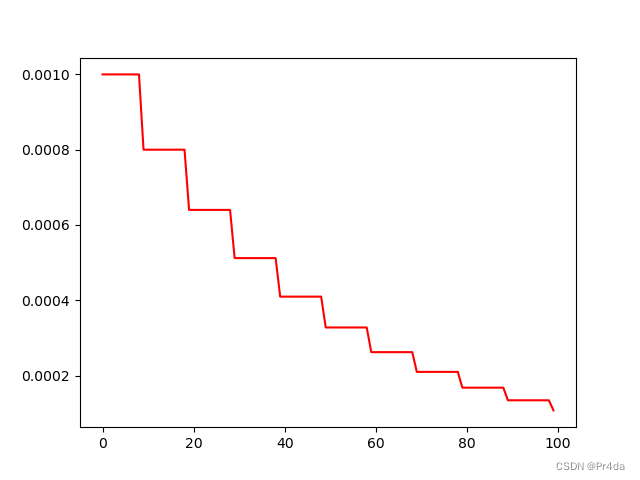
2. 手动修改optinmizer中的lr
import matplotlib.pyplot as plt from torch import nn import torch class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.net = nn.Linear(10,10) def forward(self, input): out = self.net(input) return out model = Net() LR = 0.01 optimizer = torch.optim.Adam(model.parameters(), lr = LR) lr_list = [] for epoch in range(100): if epoch % 5 == 0: for p in optimizer.param_groups: p['lr'] *= 0.9 # 学习率调整为原来的0.9 lr_list.append(optimizer.state_dict()['param_groups'][0]['lr']) plt.plot(range(100), lr_list, color = 'r') plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
学习率每个epoch变为原来的0.9,衰减曲线如下图所示:

Pytorch中给了很多学习率衰减的函数,我们不需要自己定义也可以动态调整学习率。
3. lr_scheduler.LambdaLR
如何在pytorch中调整lr具体请参考Pytorch文档How to adjust learning rate
CLASS torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=- 1, verbose=False)- 1
import numpy as np import torch from torch import nn import matplotlib.pyplot as plt class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.net = nn.Linear(10,10) def forward(self, input): out = self.net(input) return out model = Net() lr_list = [] LR = 0.01 optimizer = torch.optim.Adam(model.parameters(), lr = LR) lambda1 = lambda epoch: 0.95 ** epoch scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer,lr_lambda = lambda1) for epoch in range(100): optimizer.zero_grad() # clear previous gradients optimizer.step() # performs updates using calculated gradients scheduler.step() # update lr lr_list.append(optimizer.state_dict()['param_groups'][0]['lr']) plt.plot(range(100),lr_list,color = 'r') plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
学习率衰减如图所示:

4. lr_scheduler.StepLR
CLASS torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1, verbose=False)- 1
- step_size: lr的衰减步长
- gamma: lr衰减的乘法因子
每隔step_size个epoch,学习率变为原来的gamma,例如,step_size设置为30,初始学习率设置为0.05,学习率变化如下所示:
>>> # Assuming optimizer uses lr = 0.05 for all groups >>> # lr = 0.05 if epoch < 30 >>> # lr = 0.005 if 30 <= epoch < 60 >>> # lr = 0.0005 if 60 <= epoch < 90 >>> # ... >>> scheduler = StepLR(optimizer, step_size=30, gamma=0.1) >>> for epoch in range(100): >>> train(...) >>> validate(...) >>> scheduler.step()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
import numpy as np import torch from torch import nn import matplotlib.pyplot as plt class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.net = nn.Linear(10,10) def forward(self, input): out = self.net(input) return out model = Net() lr_list = [] LR = 0.01 optimizer = torch.optim.Adam(model.parameters(), lr = LR) lambda1 = lambda epoch: 0.95 ** epoch scheduler = torch.optim.lr_scheduler.StepLR(optimizer,step_size=5,gamma = 0.8) for epoch in range(100): optimizer.zero_grad() # clear previous gradients optimizer.step() # performs updates using calculated gradients scheduler.step() # update lr lr_list.append(optimizer.state_dict()['param_groups'][0]['lr']) plt.plot(range(100),lr_list,color = 'r') plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
学习率衰减曲线如下所示:
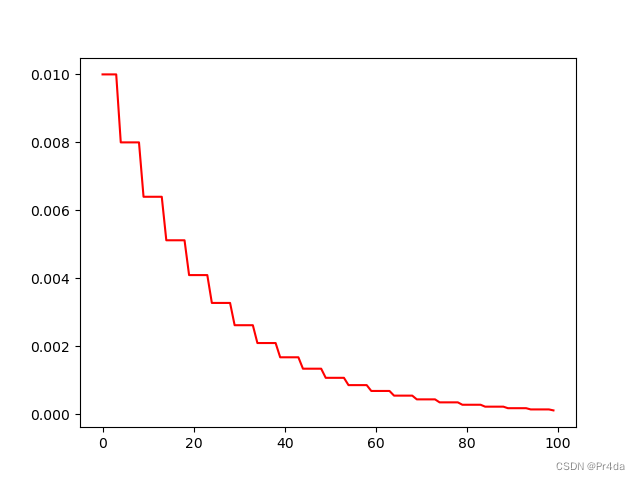
5. lr_scheduler.ExponentialLR
CLASStorch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=- 1, verbose=False)- 1
- gamma: 学习率衰减乘数因子
import numpy as np import torch from torch import nn import matplotlib.pyplot as plt class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.net = nn.Linear(10,10) def forward(self, input): out = self.net(input) return out model = Net() lr_list = [] LR = 0.01 optimizer = torch.optim.Adam(model.parameters(), lr = LR) lambda1 = lambda epoch: 0.95 ** epoch scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer,gamma = 0.8) for epoch in range(100): optimizer.zero_grad() # clear previous gradients optimizer.step() # performs updates using calculated gradients scheduler.step() # update lr lr_list.append(optimizer.state_dict()['param_groups'][0]['lr']) plt.plot(range(100),lr_list,color = 'r') plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
学习率曲线如下图所示:

注意,如果相打印每一个epoch的当前学习率,官网中说的方法是调用
print_Lr(),但实际上pytorch中并没有该方法,我们需要使用get_last_lr()方法才能打印每一个epoch的学习率。更多学习率调整方法的介绍可以参考文档.
References:
[1] https://github.com/agrija9/Deep-Unsupervised-Domain-Adaptation/tree/master/DDC
[2] Pytorch学习率lr衰减(decay)(scheduler) -
相关阅读:
阿里面试题:强、软、弱、虚引用的特点及应用场景
数据传输功能单元——DID参数定义
BasicAuth认证实现
linux设置宽带
DSPE-PEG-DBCO,DBCO-PEG-DSPE,磷脂-聚乙二醇-二苯并环辛炔科研试剂
Vue 使用原生 js 实现锚点定位到指定位置
(转)什么是数据匿名化
(附源码)ssm人才市场招聘信息系统 毕业设计 271621
js基础知识整理之 —— 字符串
Docker Golang 开发环境搭建指南
- 原文地址:https://blog.csdn.net/qq_40210586/article/details/126242252
