-
【论文解读】Co-attention network with label embedding for text classification
🍥关键词:文本分类、多分类、多标签、标签嵌入
🍥发表期刊:Neurocomputing 2022 A2
华南理工出了一篇有意思的文章,将标签和文本的序列信息进行深度融合,最终形成文本增强的标签表示和标签增强的文本表示。让我们来看看这篇文章吧。
一、Introduction
在本文中,我们试图通过进一步构造具有文本到标签注意的文本参与标签表示来利用标签信息。为此,我们提出了一种带有标签嵌入的协同注意网络(CNLE),该网络将文本和标签联合编码到它们相互参与的表示中。通过这种方式,该模型能够兼顾两者的相关部分。实验表明,我们的方法在7个多类分类基准和2个多标签分类基准上取得了与以前最先进的方法相比较不错的结果。
Paper中设计了一个网络模型,其包括Text-Lable Co-attentive Encoder(TLCE)和Adaptive Label Decoder(ALD)
 二、Model
二、Model2.1 TLCE
假设文本x包含m个词和标签序列l包含c个标签
使用预训练词向量GloVe模型对单词进行嵌入,使用随机初始化对标签进行嵌入,随后使用两个独立的线性投影层进行投影,得到
 ,
,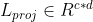
为了捕获文本序列中的上下文信息和标签序列中的相关性,使用BiLSTM来进行特征提取
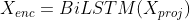
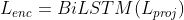
为了获得文本参与的标签表示和标签参与的文本表示,使用改编的MultiHead Self-Attention

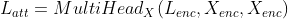


为了进一步利用标签连接文本编码的上下文信息和文本连接标签编码的相关性,使用两个独立的BiLSTM来传播文本序列和标签序列
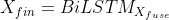
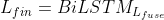
到这里为止,编码工作就完成了
2.2 ALD
随后需要进行解码工作,主要使用了两个步骤
1)使用使用LSTM解码器获得隐藏状态、单元状态和循环上下文状态
2)通过自适应分类器计算每个类的概率
使用标准LSTMCell来生成标签序列进行解码操作,
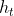 是隐藏层状态,
是隐藏层状态,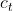 是cell状态,
是cell状态,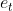 是标签表示,
是标签表示, 是文本表示。
是文本表示。![h_{t},c_{t}=LSTMCell([e_{t-1};r_{t-1}]],h_{t-1},c_{t-1})](https://1000bd.com/contentImg/2022/08/13/044248300.gif)
获得隐藏层状态之后,加上文本序列来计算注意力权重
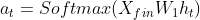
那么,当前状态的上文表示为
![r_{t}=Tanh(W_{2}[X_{fin}^{T}a_{t};h_{t}])](https://1000bd.com/contentImg/2022/08/13/044250034.gif)
获得了隐藏层状态后与标签序列一起来生成自适应分类器
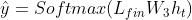
损失函数的定义为
![\wp =-\sum_{t=1}^{T}\sum_{i\in \varphi }^{}1[y_{t}=i]log(\hat{y}_{t})](https://1000bd.com/contentImg/2022/08/13/044252356.gif)
这里的损失函数既可以用于单标签也可以用于多标签
三、Experiment
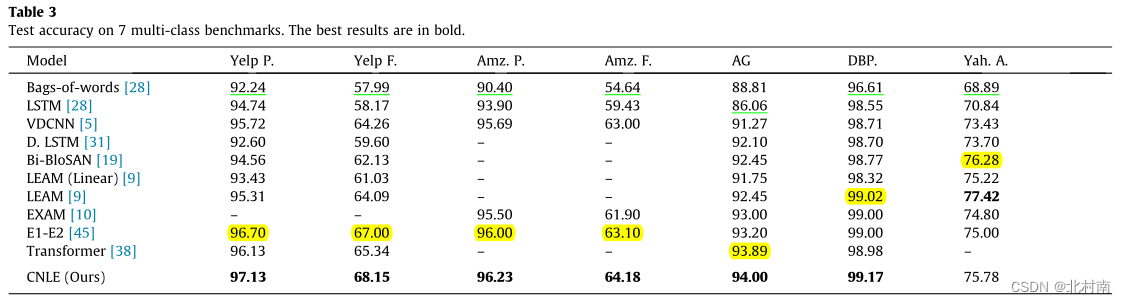
数据集包括了7个多类分类数据集和2个多标签分类数据集,均为经典数据集

准确率
micro-F1


消融实验


对比实验

共享权重策略实验

共享参数对分类的效果没有多大影响,因为这样的模型使得标签和文本在语义空间上已经有高度的相似性。
四、Conclusion
这样的注意力机制还是蛮有意思的,将标签信息与文本信息进行融合,获得标签参与的文本表示和文本参与的标签表示。在多标签和低资源文本分类问题上可以进行借鉴。
-
相关阅读:
深入探究Spring自动配置原理及SPI机制:实现灵活的插件化开发
C++ 之 queue、stack、dueque队列
2023/9/20 -- C++/QT
C++十种排序算法实现
二叉树经典OJ题——【数据结构】
百度智能云千帆 ModelBuilder 技术实践系列:通过 SDK 快速构建并发布垂域模型
[附源码]Python计算机毕业设计Django水果管理系统
RHEL、CentOS和Fedora之间的区别!
PHP遇见错误了看不懂?这些错误提示你必须搞懂
C# 第五章『面向对象』◆第9节:抽象类和密封类
- 原文地址:https://blog.csdn.net/ccaoshangfei/article/details/126085984