-
数据库分库分表<====>分布式事务
什么是分库分表
分库分表方案是对关系型数据库数据存储和访问机制的一种补充。
分库:将一个库的数据拆分到多个相同的库中,访问的时候访问一个库
分表:把一个表的数据放到多个表中,操作对应的某个表就行分库分表
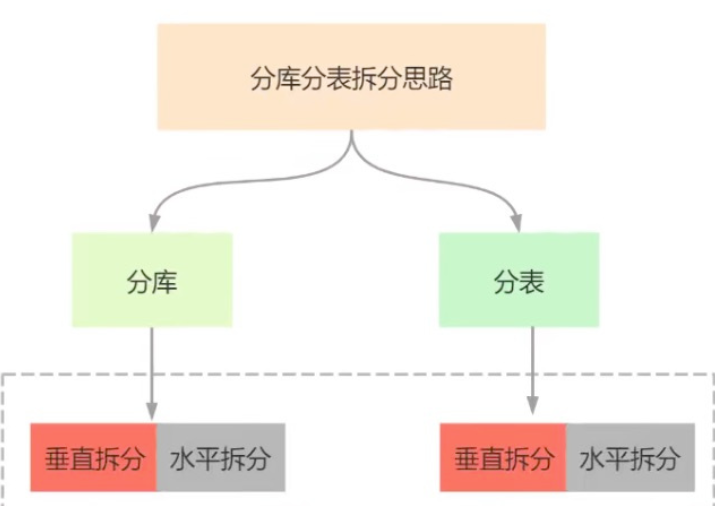
1、水平分库
概念:以字段为依据,按照一定策略(hash、range等),将一个库中的数据拆分到多个库中。结果:
- 每个库的结构都一样;
- 每个库的数据都不一样,没有交集;
- 所有库的并集是全量数据;
场景:系统绝对并发量上来了,分表难以根本上解决问题,并且还没有明显的业务归属来垂直分库。分析:库多了,io和cpu的压力自然可以成倍缓解。
2、水平分表
概念:以字段为依据,按照一定策略(hash、range等),将一个表中的数据拆分到多个表中。
结果:- 每个表的结构都一样;
- 每个表的数据都不一样,没有交集;
- 所有表的并集是全量数据;
场景:系统绝对并发量并没有上来,只是单表的数据量太多,影响了SQL效率,加重了CPU负担,以至于成为瓶颈。分析:表的数据量少了,单次SQL执行效率高,自然减轻了CPU的负担。
3、垂直分库
概念:以表为依据,按照业务归属不同,将不同的表拆分到不同的库中。结果:
- 每个库的结构都不一样;
- 每个库的数据也不一样,没有交集;
- 所有库的并集是全量数据;
场景:系统绝对并发量上来了,并且可以抽象出单独的业务模块。分析:到这一步,基本上就可以服务化了。例如,随着业务的发展一些公用的配置表、字典表等越来越多,这时可以将这些表拆到单独的库中,甚至可以服务化。再有,随着业务的发展孵化出了一套业务模式,这时可以将相关的表拆到单独的库中,甚至可以服务化。
4、垂直分表
概念:以字段为依据,按照字段的活跃性,将表中字段拆到不同的表(主表和扩展表)中。
结果:- 每个表的结构都不一样;
- 每个表的数据也不一样,一般来说,每个表的字段至少有一列交集,一般是主键,用于关联数据;
- 所有表的并集是全量数据;
场景:系统绝对并发量并没有上来,表的记录并不多,但是字段多,并且热点数据和非热点数据在一起,单行数据所需的存储空间较大。以至于数据库缓存的数据行减少,查询时会去读磁盘数据产生大量的随机读IO,产生IO瓶颈。分析:可以用列表页和详情页来帮助理解。垂直分表的拆分原则是将热点数据(可能会冗余经常一起查询的数据)放在一起作为主表,非热点数据放在一起作为扩展表。这样更多的热点数据就能被缓存下来,进而减少了随机读IO。拆了之后,要想获得全部数据就需要关联两个表来取数据。但记住,千万别用join,因为join不仅会增加CPU负担并且会讲两个表耦合在一起(必须在一个数据库实例上)。关联数据,应该在业务Service层做文章,分别获取主表和扩展表数据然后用关联字段关联得到全部数据。
分库分表问题
- 分布式事务
- 跨库join查询
- 分布式全局唯一id
- 开发成本 对程序员要求高
1、非partition key的查询问题
基于水平分库分表,拆分策略为常用的hash法。端上除了partition key只有一个非partition key作为条件查询
映射法、基因法、冗余法
后台除了partition key还有各种非partition key组合条件查询
NoSQL法、冗余法
2、非partition key跨库跨表分页查询问题
基于水平分库分表,拆分策略为常用的hash法。
注:用NoSQL法解决(ES等)。
分布式事务
分布式事务指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的分布式系统的不同节点之上,且属于不同的应用,分布式事务需要保证这些操作要么全部成功,要么全部失败。本质上来说,分布式事务就是为了保证不同数据库的数据一致性。
分布式事务应用架构
1 单一服务分布式事务
2 多服务分布式事务
3 多服务多数据源分布式事务
柔性事务
在电商领域等互联网场景下,传统的事务在数据库性能和处理能力上都暴露出了瓶颈。在分布式领域基于CAP理论以及BASE理论,有人就提出了柔性事务的概念。
CAP(一致性、可用性、分区容忍性)
一致性(Consistency)
一致性,意思是在一个分区进行写操作后,所有分区的数据都要保持一致的读操作。
可用性(Availability)
可用性,意思是只要收到请求,系统就必须给出响应。
分布式系统有多个分区,即使有少数分区的服务崩溃了,还能继续提供服务,这就是服务的可用性。
分区容错(Partition tolerance)
分区容错,意思是允许分区之间的通信失败。分布式系统要允许分区之间通信的失败,也就是CAP中的P总是成立的,但是剩下的 C 和 A 是无法同时做到的。
一致性和可用性不能同时做到的原因是:出现了分区容错,也就是可能通信失败。
如上例子,如果要保证B区的一致性,那么在A区进行写操作时,必须给B区的数据加上读写锁,在锁定期间,客户端不能读写该数据。只有数据同步后,才释放掉锁,B区才重新开放读写。这样,保证了一致性,但是没有了可用性。
如果要保证B区的可用性,就不能对B区加上读写锁,这样又缺少了一致性。
因此,一致性和可用性是不能同时做到的。在设计分布式系统时,如果追求一致性,那么无法保证所有分区的可用性;如果追求所有分区的可用性,那么就没法做到一致性。
【应该尽量满足AP或者CP】
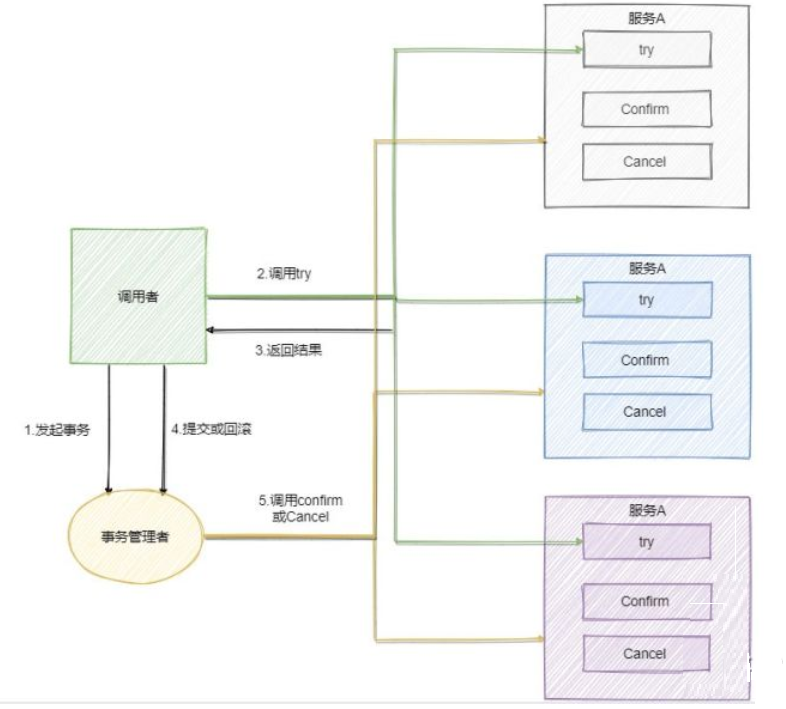
TCC模型
TCC 是业务层面的分布式事务
TCC 指的是
Try - Confirm - Cancel。- Try 指的是预留,即资源的预留和锁定,注意是预留。
- Confirm 指的是确认操作,这一步其实就是真正的执行了。
- Cancel 指的是撤销操作,可以理解为把预留阶段的动作撤销了。
-
相关阅读:
redisson使用全解——redisson官方文档+注释(下篇)
详细学习Mybatis(1)
剑指 Offer 04. 二维数组中的查找 :Java
Python:函数和代码复用
JAVA IDEA 下载
java计算机毕业设计婴幼儿玩具共享租售平台源程序+mysql+系统+lw文档+远程调试
Matlab|含多微网租赁共享储能的配电网博弈优化调度
java计算机毕业设计基于springboo+vue的健身房课程预约平台
用DIV+CSS技术设计的体育篮球主题 校园体育网页与实现制作(web前端网页制作课作业)
JAVA学习实战(十二)分库分表学习
- 原文地址:https://blog.csdn.net/qq_51074048/article/details/126225013

