-
MapReduce详细流程
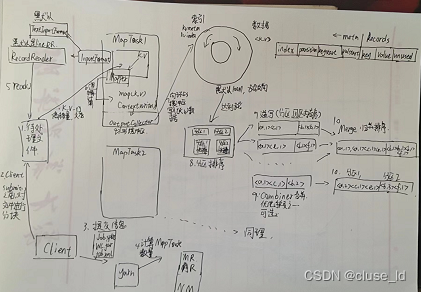
- 选择待处理文件
- client进行submit之前,client对待处理文件进行切片。
- client将任务提交到yarn集群中
- yarn计算MapTask的数量,然后选择一个NodeManager开启对应的MapReduceApplicationMaster,MRAM与yarn交互,完成节点的选择,然后MRAM与对应NM进行通信,在其上面开启MapTask。
- MapTask通过RecordReader的read方法读取待处理文件。
- 通过自定义逻辑对数据进行计算。
- 计算完成后将数据通过contextWriter写入outputCollector(环形缓冲区)中。环形缓冲区默认100M,数据加索引总大小达到80%之后,将数据溢写到磁盘。数据写入环形缓冲区的时候会记录分区。
- 在写入磁盘之前,会对数据进行分区,在对分区内进行排序(快速排序),使得区内有序。
- 将排完序的数据溢写到磁盘中。
- 对所有数据进行一次排序,由于区内有序,所以采用归并排序。 排完序后,MapTask阶段结束。

- MRAM检测到所以MapTask完成后,启动对应数量的ReduceTask。并告知各个ReduceTask处理那个分区的数据。
- ReduceTask将分配给自己的分区的数据从各Map端拉取到本地(先拉取到内存,内存不够了再存到磁盘)。
- 将拉取过来的不同Map端的数据(内存和磁盘)进行排序(归并)。
- Reduce对排完序的数据进行拉取,按照key分组,每一拉取一组数据。
- 通过RecordWriter的write方法将计算结果写出,流程结束。
-
相关阅读:
Seata之AT模式原理详解(三)
Harbor 简介
typora设置标题自动编号
java-php-net-python-代驾网站计算机毕业设计程序
消息中间件(MQ)
vue3下watch的使用
SpringBoot2基础篇(四)—— 基于SpringBoot的SSMP整合案例
ElasticSearch 进阶(一)
农牧行业全产业链20+业务用契约锁电子签,释放成本、提效90%
Docker笔记
- 原文地址:https://blog.csdn.net/Laoddaaa/article/details/126245115