-
[论文阅读] Diverse Image-to-Image Translation via Disentangled Representations
Abstract
图像到图像的翻译旨在学习两个视觉领域之间的映射。对于许多应用来说,有两个主要的挑战:(1)缺乏对齐的训练对;(2)从单一的输入图像中获得多种可能的输出。在这项工作中,我们提出了一种基于分离表示的方法,在没有配对训练图像的情况下产生不同的输出。为了实现多样性,我们建议将图像嵌入两个空间:一个是捕捉跨领域共享信息的领域不变的内容空间,一个是特定领域的属性空间。使用分解后的特征作为输入,大大减少了模式崩溃。为了处理不配对的训练数据,我们引入了一个新的跨周期一致性损失。定性结果表明,我们的模型可以在广泛的任务中产生多样化和现实的图像。我们通过广泛的评估验证了我们方法的有效性。
Method
本文与MUNIT类似,核心思想是解耦。不同的是,MUNIT是解耦成风格(style)和内容(content),而本文DRIT解耦的是两个域不同的属性(attribute)与两个域共同的内容(content),方法流程如下:
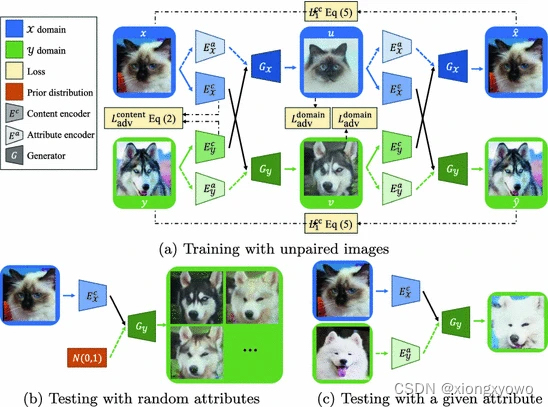
具体损失函数如下:
Disentangle Loss 思路其实挺暴力的,既然两个domain内容应该是共享的,那么仅凭内容向量是无法区分某个图像的domain的,因此单独设计了一个判别器,来促使Encoder编码出判别器无法区分的东西,即"内容": L a d v c o n t e n t ( E X c , E Y c , D c ) = E x [ 1 2 log D c ( E X c ( x ) ) + 1 2 log ( 1 − D c ( E X c ( x ) ) ) ] + E y [ 1 2 log D c ( E Y c ( y ) ) + 1 2 log ( 1 − D c ( E Y c ( y ) ) ) ] L_{\mathrm{adv}}^{\mathrm{content}}(E^c_\mathcal{X},E^c_\mathcal{Y}, D^c) = \mathbb{E}_{x}[\frac{1}{2}\log{D^c(E^c_\mathcal{X}(x))}+\frac{1}{2}\log{(1-D^c(E^c_\mathcal{X}(x)))]} + \mathbb{E}_{y}[\frac{1}{2}\log{D^c(E^c_\mathcal{Y}(y))}+\frac{1}{2}\log{(1-D^c(E^c_\mathcal{Y}(y)))}] Ladvcontent(EXc,EYc,Dc)=Ex[21logDc(EXc(x))+21log(1−Dc(EXc(x)))]+Ey[21logDc(EYc(y))+21log(1−Dc(EYc(y)))]Cross-Cycle Consistency Loss 其实就是CycleGAN中的loss,图像从X->Y->X应保持一致,从而促使X->Y的这一过程保留原有的内容: L 1 c c ( G X , G Y , E X c , E Y c , E X a , E Y a ) = E x , y [ ∥ G X ( E Y c ( v ) , E X a ( u ) ) − x ∥ 1 + ∥ G Y ( E X c ( u ) , E Y a ( v ) ) − y ∥ 1 ] L_1^{\mathrm{cc}}(G_\mathcal{X},G_\mathcal{Y},E_\mathcal{X}^c,E_\mathcal{Y}^c,E_\mathcal{X}^a,E_\mathcal{Y}^a) = \mathbb{E}_{x,y}[\lVert G_\mathcal{X}(E_\mathcal{Y}^c(v),E_\mathcal{X}^a(u) )-x \lVert_{1} + \lVert G_\mathcal{Y}(E_\mathcal{X}^c(u),E_\mathcal{Y}^a(v) )-y \lVert_{1}] L1cc(GX,GY,EXc,EYc,EXa,EYa)=Ex,y[∥GX(EYc(v),EXa(u))−x∥1+∥GY(EXc(u),EYa(v))−y∥1]
Domain Adversarial Loss domain X的图像翻译至domain Y后应该看起来真实,这个是几乎绝大数GAN的基本loss: L a d v ( E c _ y , E a _ x , G x , D x ) = E x , y [ log D x ( x ) + log ( 1 − D x ( u ) ) ] L_{adv}(E_{c\_y},E_{a\_x}, G_x, D_x) = \mathbb{E}_{x,y}[\log{D_x(x)} +\log(1-{D_x(u)})] Ladv(Ec_y,Ea_x,Gx,Dx)=Ex,y[logDx(x)+log(1−Dx(u))]
Self-Reconstruction Loss domain X的图像在输入domain X的生成器后需要有能力生自己: L 1 ( G x , E c _ x , E a _ x ) = E x [ ∥ G x ( E c _ x ( x ) , E a _ x ( x ) ) − x ∥ 1 L_1(G_x,E_{c\_x},E_{a\_x}) = \mathbb{E}_{x}[\lVert G_x(E_{c\_x}(x),E_{a\_x}(x) )-x \lVert_{1} L1(Gx,Ec_x,Ea_x)=Ex[∥Gx(Ec_x(x),Ea_x(x))−x∥1
KL Loss 编码得到的属性向量应该尽可能满足先验高斯分布。因此在测试阶段的属性向量就是从先验高斯分布中采样得到的: L K L = E [ D K L ( ( z a ) ∥ N ( 0 , 1 ) ) ] L_{\mathrm{KL}}= \mathbb{E}[D_{\mathrm{KL}}((z_a)\|N(0,1))] LKL=E[DKL((za)∥N(0,1))] D K L ( p ∥ q ) = − ∫ p ( z ) log p ( z ) q ( z ) d z D_{\mathrm{KL}}(p\|q)=-\int{p(z)\log{\frac{p(z)}{q(z)}}\mathrm{d}z} DKL(p∥q)=−∫p(z)logq(z)p(z)dz
Latent Regression Loss 将内容向量 c x c_x cx与随机的属性向量z相结合,生成一张新图像后,将其重新使用属性编码器编码,仍能回到自身z。这一点也是保障成功解耦用的。
L l r ( G x , G y ) = E x [ ∥ G x ( E c _ x ( x ) , z ) − z ∥ 1 + E y [ ∥ G y ( E c _ y ( y ) , z ) − z ∥ 1 ] L_{lr}(G_x, G_y) = \mathbb{E}_{x}[\lVert G_x(E_{c\_x}(x),z)-z\lVert_{1} +\mathbb{E}_{y}[\lVert G_y(E_{c\_y}(y),z)-z\lVert_{1}] Llr(Gx,Gy)=Ex[∥Gx(Ec_x(x),z)−z∥1+Ey[∥Gy(Ec_y(y),z)−z∥1] -
相关阅读:
Java 断点下载(下载续传)服务端及客户端(Android)代码
朋友电脑密码忘了,我当场拔了她的电源,结果。。。
数据库管理变更工具
HCM 初学 ( 二 ) - 信息类型
ResponseBodyAdvice 获取参数
Python基本数据结构:深入探讨列表、元组、集合和字典
java ssm新鲜果汁厂进销存管理系统
功能上新 | Magic Data Annotator智能出行舱内舱外全场景标注
测试用例的编写(面试常问)
修改ZABBIX的logo,最终版方法,简单好用,适用于所有ZABBIX版本,一学即会!!!!!
- 原文地址:https://blog.csdn.net/qq_40714949/article/details/126235763