-
动手学深度学习_全卷积网络 FCN
全卷积网络 (fully convolutional network,FCN),顾名思义,网络中完全使用卷积而不再使用全联接网络。全卷积网络之所以能把输入图片经过卷积后在进行尺寸上的还原,就是利用转置卷积实现的。 因此,输出的类别预测与输入图像在像素级别上具有一一对应关系:通道维的输出即该位置对应像素的类别预测。
全卷积网络先使用卷积神经网络抽取图像特征,然后通过 1 × 1 卷积层将通道数变换为类别个数,最后转置卷积层将特征图的高和宽变换为输入图像的尺寸。 因此,模型输出与输入图像的高和宽相同,且最终输出通道包含了该空间位置像素的类别预测。
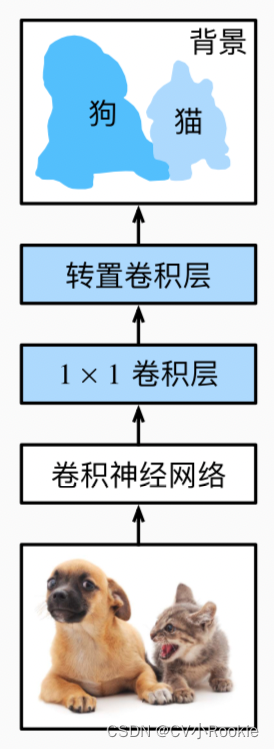
白色方框部分的卷积神经网络使用 ResNet-18 来进行提取特征(去掉 ResNet-18 最后的全局池化层和全联接层)
- pretrained_net = torchvision.models.resnet18(pretrained=True)
- # 采用输入大小是(3,320,480)
- net = nn.Sequential(*list(pretrained_net.children())[:-2])
- # VOC数据集20类+背景类=21
- num_classes = 21
- # ResNet-18最后一层卷积输出维度是512
- # 这里是为了减少计算,所以直接调整维度到21
- net.add_module('final_conv', nn.Conv2d(512, num_classes, kernel_size=1))
- # 采用转置卷积,恢复图像尺寸
- net.add_module('transpose_conv',
- nn.ConvTranspose2d(num_classes, num_classes,
- kernel_size=64, padding=16, stride=32))
这里我们没有采用随机初始化转置卷积,而是利用双线性插值(bilinear interpolation)对转置卷积的权重进行初始化,因为转置卷积做的是上采样操作,双线性插值就是对图片放大,那么其参数应该对转置卷积有利。
- # 双线性插值实现
- def bilinear_kernel(in_channels, out_channels, kernel_size):
- factor = (kernel_size + 1) // 2
- if kernel_size % 2 == 1:
- center = factor - 1
- else:
- center = factor - 0.5
- og = (torch.arange(kernel_size).reshape(-1, 1),
- torch.arange(kernel_size).reshape(1, -1))
- filt = (1 - torch.abs(og[0] - center) / factor) * \
- (1 - torch.abs(og[1] - center) / factor)
- weight = torch.zeros((in_channels, out_channels,
- kernel_size, kernel_size))
- weight[range(in_channels), range(out_channels), :, :] = filt
- return weight
对转置卷积使用双线性插值初始化,1 x 1 卷积使用 Xavier 初始化
- nn.init.xavier_uniform_(self.final_conv.weight, gain=1)
- W = bilinear_kernel(num_classes, num_classes, 64)
- net.transpose_conv.weight.data.copy_(W);
读取数据集,定义损失函数,训练
- batch_size, crop_size = 32, (320, 480)
- train_iter, test_iter = d2l.load_data_voc(batch_size, crop_size)
- def loss(inputs, targets):
- return F.cross_entropy(inputs, targets, reduction='none').mean(1).mean(1)
- num_epochs, lr, wd, devices = 5, 0.001, 1e-3, d2l.try_all_gpus()
- trainer = torch.optim.SGD(net.parameters(), lr=lr, weight_decay=wd)
- d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs, devices)
注意这里的损失函数,和之前一样都是使用的交叉熵损失,但是由于我们使用转置卷积的通道来预测像素类别,所以需要在损失函数里计算指定通道维。

-
相关阅读:
mysql作业(牛客60-80)
Java实现计算两个日期之间的工作日天数
前端基础:防抖与节流
Android kotlin在实战过程问题总结与开发技巧详解
论文解读(IGSD)《Iterative Graph Self-Distillation》
MySQL的三种日志文件
nginx
(C++17) optional的使用
Docker:rabbitmq启动镜像后访问15672端口无法显示管理界面问题解决
SpringBoot-基础配置
- 原文地址:https://blog.csdn.net/like_jmo/article/details/126241997
