-
一站制造项目及Spark核心面试 ,220808,,,


 RANGE BETWEEN
RANGE BETWEENrow BETWEEN
用到了默认的windowframe

比率求值,




直接用where datediff( nlogindate-logindate)=n-1来判断也ok吧?
set开启本地模式,dg,
每个用户最大连续登陆次数






 ,
,多看多练,规律sql题,,经验积累,,
把主讲的项目,写到最新日期吗?
对的,
项目时间 逆序放,
RDD设计类似于Hive中表



返回值是不是一个RDD

reduce 触发
reduceByKey 转换


日志下载,放在hdfs,historyserver下,映射,,

driver只会在,客户端/从节点
每个stage中最后一个rdd的分区数
Stage中最后一个或者最小RDD分区数

1-Spark不是纯内存式计算,Shuffle过程依旧是使用磁盘的
2-只要是计算,都是基于内存计算
3-Spark积极使用内存,窄依赖都在内存中完成、允许内存中缓存RDD,相比MR,大部分的中间结果都是在内存中直接传递的
Wordcount代码是唯一一个面试中写的代码
Wordcount SQL,DSL,RDD算子代码,怎么写????

举例子,设计个程序,spark资源管理???




reduceByKey、foldByKey,map端聚合,


设计谓词下推例子???

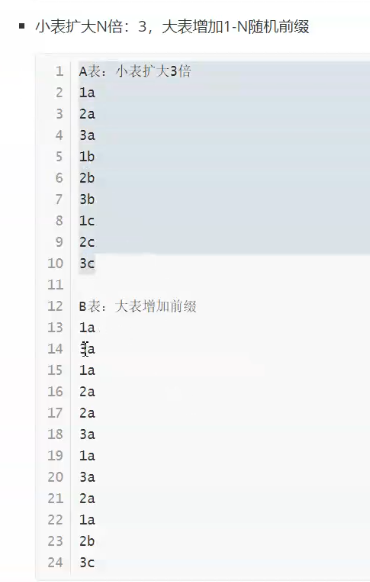

重新写代码,要么原有的上面修改,,
两年前:构建平台、平台产出价值
新需求:更好的管理,挖掘更多价值


RANGE BETWEEN???
row BETWEEN???

Wordcount SQL,DSL,RDD算子代码,怎么写????
设计谓词下推例子???
产品表(100万),商品详情表名称(10万),
SET hive.optimize.ppd=true,先过滤再join
(明天问老师??) spark set开启本地模式属性,dg,
-
相关阅读:
Python - 小玩意 - html 转 pdf
JAVA毕设项目商品供应管理系统(java+VUE+Mybatis+Maven+Mysql)
STL排序、拷贝和替换算法
CLIP改进工作串讲(上)
1024程序员节 | 电脑软件:SmartSystemMenu(窗口置顶工具)介绍
Debian 开机自动挂载磁盘
顶级架构师编写,《DDD领域驱动设计笔记》,看到内容后才明白啥叫顶级,一分钱一分货
Spring Boot 文件上传与下载
U3d力扣基础刷题-2
蓝链带货怎么玩?B站横屏、竖屏恰饭竟增长1200w播放!
- 原文地址:https://blog.csdn.net/m0_48941160/article/details/126221215