-
redis介绍&命令&性能数据及监控&缓存穿透
上一章:
linux安装部署redis&配置远程连接_傲娇的喵酱的博客-CSDN博客
一、redis介绍
Redis是C语言写的,官方提供的数据为100000+的QPS(每秒查询率)
Redis是基于内存操作,Redis的数据在内存中,是非持久化的。
CPU不是Redis性能瓶颈,Redis的瓶颈是根据机器的内存和网络带宽。
redis速度快原因:
1、Redis是基于内存操作,内存的存取速度远高于硬盘的存取速度。redis是将所有的数据全部放在内存中的。
2、redis是单线程操作,(多线程会涉及到CPU上下文会切换,上下文切换会消耗性能),对于内存系统来说,如果没有上下文切换,单线程效率就是最高的。
Redis 与其他 key - value 缓存产品有以下三个特点:
Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
Redis支持数据的备份,即master-slave模式的数据备份。
二、redis连接
1.1 redis-cli 客户端连接redis
本地:
./redis-cli远程连接:
redis-cli -h host -p port -a password三、常用命令
redis有16个数据库, 默认使用的是第0个,使用select切换数据库。
我们连接redis成功后,默认使用的是第0个库,想要切换库,使用select切换,比如切换第2个库
select 2查看当前库下,所有的key
keys *
注意: 由于redis是单线程的,因此在redis key数量很多的时候禁用该命令,否则容易引起生产应用夯机现象
如果一定要使用,除非能确定数据量不大,或者在一个没有被使用的集群节点上使用新增数据
set key value
例如:set name zhangsan读取数据
get key例如:
get name模糊搜索
模糊搜索包含关键字的所有key
-匹配数据库中所有 key
keys *-?匹配
keys h?llo匹配 hello , hallo 和 hxllo
-*匹配
keys h*llo匹配 hllo 和 heeello 等。
删除单个key
del key删除当前数据库中的所有Key (慎用删除啊)flushdb删除所有数据库中的key (慎用删除啊)
flushall检查key是否存在
exists key返回key数据类型
type key设置过期时间
设置失效时间1:
- expire key seconds
- 如:
- expire name 5
设置失效时间2:
- setex key seconds value
- 如:
- setex sex 5 boy
- setex myname 600 zhangsanhahah
seconds 失效时间,单位秒
查看key的剩余失效时间:
语法:
ttl key的名字返回值:
-
1、不存在的key:返回
-2 -
2、key存在,但没有设置剩余生存时间:返回
-1 -
3、有剩余生存时间的key:
返回key的剩余时间(以秒为单位)
举例:
key myname剩余失效时间为232秒。
四、key的五大数据类型
Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
4.1 String类型
String 是 redis 最基本的类型,一个 key 对应一个 value。
String 类型是二进制安全的,redis 的 string 可以包含任何数据。
String 类型是 Redis 最基本的数据类型,string 类型的值最大能存储 512MB。
4.2 List(列表)
Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)
LPUSH key value [value ...]
从队列的左边入队一个或者多个元素
如,key name_list 作为一个list,插入zhangsan 与 lisi 这两个元素

RPUSH key value [value ...]
从队列的右边入队一个或者多个元素
- 127.0.0.1:6379> RPUSH name_list xiaoming xiaohong
- (integer) 4
查询元素 LRANGE key start stop
返回存储在key的列表里指定范围内的元素。list的下标从0开始。
-1 表示列表的第一个元素,-2表示列表的第二个元素。
举例:
查询 key list的前2个元素
- 127.0.0.1:6379> LRANGE name_list 0 1
- 1) "lisi"
- 2) "zhangsan"
查询key list 的倒数2个元素
- 127.0.0.1:6379> LRANGE name_list -2 -1
- 1) "xiaoming"
- 2) "xiaohong"
LINDEX key index,通过索引查询元素
查询列表的第一个元素
- 127.0.0.1:6379> LINDEX name_list 1
- "zhangsan"
LLEN key,查询列表的长度
- 127.0.0.1:6379> LLEN name_list
- (integer) 4
4.3 Set
Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。
Redis 中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
SADD key member [member ...]
添加一个或者多个元素到set集合里
在set集合CARD_ID里添加三个元素
- 127.0.0.1:6379> SADD CARD_ID id1 id2 id3
- (integer) 3
SMEMBERS key
获取集合里所有的元素
- 127.0.0.1:6379> SMEMBERS CARD_ID
- 1) "id3"
- 2) "id1"
- 3) "id2"
SISMEMBER key member
判断某个值是否在集合里
- 127.0.0.1:6379> SISMEMBER CARD_ID id1
- (integer) 1
- 127.0.0.1:6379> SISMEMBER CARD_ID id4
- (integer) 0
SCARD key
获取集合元素的数量
SREM key member [member ...]
从集合里,删除一个或者多个元素
4.4 Hash
Redis hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表,hash 特别适合用于存储对象。
添加元素
HSET key field value
举例,在一个名为person的hash key里添加元素。
添加name 等于 zhangsan
- 127.0.0.1:6379> HSET person name zhangsan
- (integer) 1
在person里继续添加元素,address beijing
- 127.0.0.1:6379> HSET person address beijing
- (integer) 1
HGET key field
根据field读取元素
读取key中filed为name的元素
- 127.0.0.1:6379> HGET person name
- "zhangsan"
4.5 ZSet
Redis 有序集合和集合一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
有序集合的成员是唯一的,但分数(score)却可以重复。
ZADD key [NX|XX] [CH] [INCR] score member [score member ...]
添加到有序set的一个或者多个成员(如果已存在,则更新分数)
- 127.0.0.1:6379> ZADD MyZSET 88.8 zhangsan 90 lisi 66 xiaohong 3 xiaoming
- (integer) 4
ZRANGE key start stop [WITHSCORES]
通过以分数的排序,来查询数据
分数越低,排的越靠前
如,查询第0个与第1个之间的数据
- 127.0.0.1:6379> ZRANGE MyZSET 0 1
- 1) "xiaoming"
- 2) "xiaohong"
五、redis缓存服务器应用场景
一般把redis用作缓存服务器,将一些常用的数据放到redis上。
其他也有把redis当做数据库来用,mysql定时将数据推送到redis上。
5.1 短信验证码---用作缓存服务器
比如一个手机验证码登录业务,把这个验证码的数据存到了redis上,然后设置一个失效时间。
超时之后,数据消失,这个验证码就不能登录了。
5.2
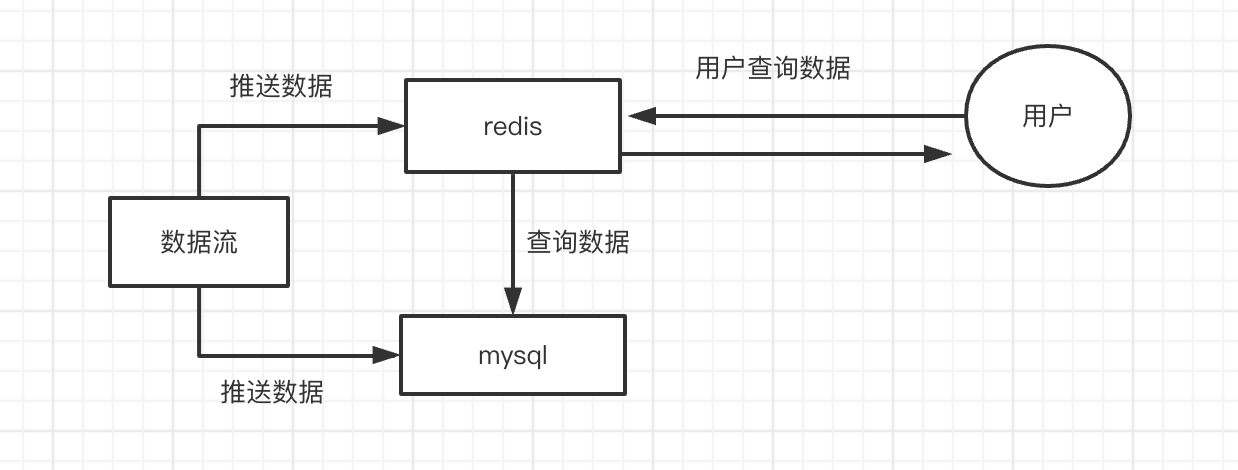
我们将数据同时推到redis 和mysql。 用户查询数据时,去redis查询数据,如果能查询到数据,就直接返回了,如果在redis查询不到数据,则去mysql查询数据。
5.3 mysql定时将数据推送到redis
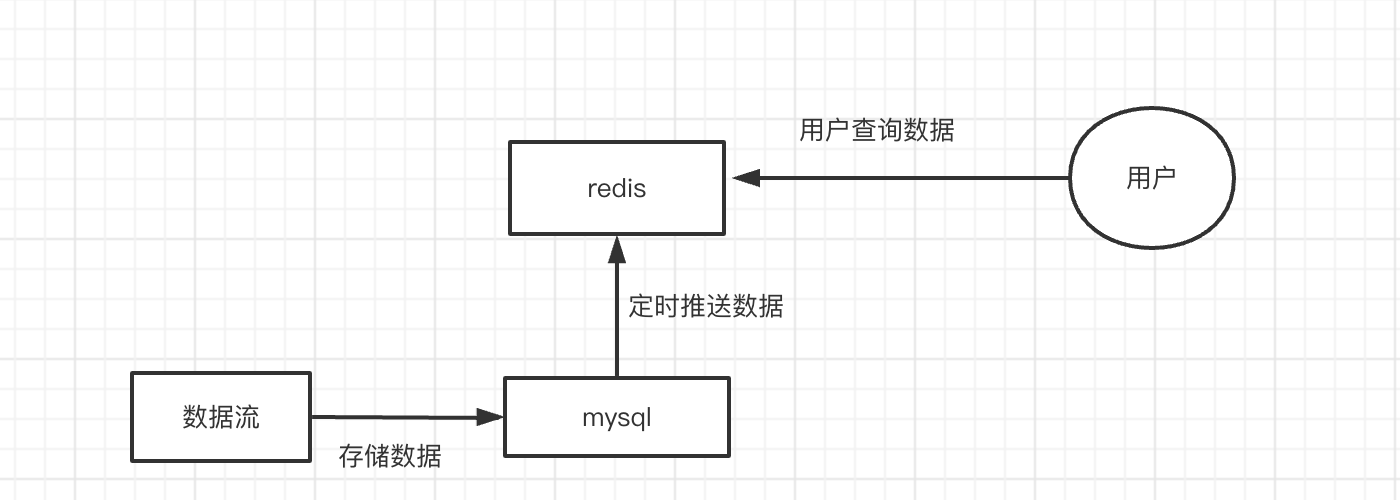
比如我们在一个拉新活动中,有一个榜单模块,展示拉新人数最多的前10名用户。
这个榜单每隔10分钟刷新一次数据。我们将用户拉新数据存在了mysql里,然后设置redis榜单数据失效时间为10分中,每隔10分钟,mysql向redis推送一下数据。
六、缓存穿透与缓存击穿场景:
举个例子,就类似于百度这种搜索场景。 如果每天大量的人搜索数据,然后去mysql等这种数据库的磁盘中,查询数据。在磁盘中读取数据,比较慢,会对数据库造成很大压力。所以 将一些很多人访问的数据(称为热点数据),缓存到redis中。 用户进行搜索的时候,是先去redis 查询数据,如果有数据,则直接返回,如果在redis中查不到数据,然后再去查mysql这种数据库。(这样是比较消耗性能的)
热点数据就是某一段时间内,用户大量访问数据。比如设置某条数据如果十分钟被访问超过5次,则称为热点数据,存在redis中。某条热点数据,在十分钟内被访问没有超过5次,则会被释放掉。
redis缓存穿透:
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求。由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。先查redis缓存,查不到,再去查存储层 这样是非常消耗性能的。
在流量大时,可能DB就挂掉了,要是有人利用不存在的key频繁攻击我们的应用,这就是漏洞。
缓存击穿:
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。利用缓存击穿攻击:
还是举搜索的例子,redis存的是热点数据。普通用户进行搜索时,先读取redis缓存,如果读不到,才去mysql数据中读。当别人攻击时,它会利用大量的生僻词去进行搜索,这些数据在redis里没有,会去读取mysql磁盘,消耗大量的性能。 并且使用 这些生僻的词变成热点数据,存贮在redis缓存中。
此时,正常用户,再去访问时,在redis缓存中,存贮的都是生僻的词,查不到他们的数据,则会再次去mysql中查询数据。造成性能的消耗。
七、redis性能数据及监控
影响redis的性能,包括内存的大小。
key的命中次数,和未命中次数。
7.1 使用info命令查看数据
在命令行,输入info
info主要有以下几项,因版本不同可能略有差别
Server:有关redis服务器的常规信息
Clients:客户端连接部分
Memory:内存消耗相关信息
Persistence:RDB和AOF相关信息
Stats:一般统计
Replication:主从同步信息
CPU:CPU消耗统计
Cluster:集群部分
Keyspace:数据库相关统计server段一般是配置以及系统项不用特别的关注。
Server部分记录了Redis服务器的信息:
- redis_version : 2.8.19 # Redis服务器版本
- redis_git_sha1:00000000 #Git SHA1
- redis_git_dirty: 0 #Git dirty flag
- os: Linux 3.2.0-23-generic x86_64 #Redis服务器的宿主操作系统
- arch_bits: 64 #服务器系统架构(32位或64位)
- multiplexing_api: epoll #Redis使用的事件处理机制
- gcc_version:4.6.3 #编译Redis时所使用的GCC版本
- process_id:7573 #Redis服务的进程PID
- run_id:f1c233c4194cba88616c5bfff2d97fc3074865c1 #Redis服务器的随机标识符(用于Sentinel和集群)
- tcp_port:6379 #Redis服务监听的TCP端口
- uptime_in_seconds:7976 #自Redis服务器启动以来,经过的秒数
- uptime_in_days:0 #自Redis服务器启动以来,经过的天数. 这里还不到1天,故显示为0
- hz:10 # Redis调用内部函数来执行许多后台任务的频率为每秒10次
- lru_clock:1133773 #以分钟为单位进行自增的时钟,用于LRU管理
- config_file:/data/redis_6379/redis.conf #redis.conf配置文件所在路径
Clients部分记录了已连接客户端的信息:
- connected_clients:2 #已连接客户端的数量(不包括通过从服务器连接的客户端)
- client_longest_output_list:0 #当前的客户端连接中,最长的输出列表
- client_biggest_input_buf:0 #当前连接的客户端中,最大的输入缓存
- blocked_clients:0 #正在等待阻塞命令(BLOP、BRPOP、BRPOPLPUSH)的客户端的数量
因为Redis是单线程模型(只能使用单核),来处理所有客户端的请求, 但由于客户端连接数的增长,处理请求的线程资源开始降低分配给单个客户端连接的处理时间,这时每个客户端需要花费更多的时间去等待Redis共享服务的响应。
因为Redis是单线程模型(只能使用单核),来处理所有客户端的请求,且Redis默认允许客户端连接的最大数量是10000。若是看到连接数超过5000以上,那可能会影响Redis的性能。因此监控客户端连接数是非常重要的,因为客户端创建连接数的数量可能超出预期的数量,也可能是客户端端没有有效的释放连接。
相关配置项:
- maxclients 10000
- tcp-backlog 10240 #TCP 监听的最大容纳数量 默认511
Memory部分记录了服务器的内存信息:
- used_memory:894216 #Redis分配器分配给Redis的内存。例如,当Redis增加了存储数据时,需要的内存直接从分配器分配给它的内存里面取就可以了,也就是直接从used_memory取。而Redis分配器分配给Redis的内存,是从操作系统分配给Redis的内存里面取的(单位是字节)
- used_memory_human:873.26K #以人类可读格式显示Redis消耗的内存
- used_memory_rss:2691072 #操作系统分配给Redis的内存。也就是Redis占用的内存大小。这个值和top指令输出的RES列结果是一样的。RES列结果就表示Redis进程真正使用的物理内存(单位是字节)
- used_memory_peak:914160 #Redis的内存消耗峰值(单位是字节)
- used_memory_peak_human:892.73K #以人类可读的格式返回Redis的内存消耗峰值
- used_memory_lua:35840 #Lua引擎所使用的内存大小(单位是字节)
- mem_fragmentation_ratio:3.01 # used_memory_rss和used_memory之间的比率
- mem_allocator:jemalloc-3.6.0 #在编译时指定的,Redis所使用的内存分配器。可以是libc、jemalloc或者tcmalloc
- 理想情况下,used_memory_rss的值应该只比used_memory稍微高一点。
- 当rss >used,且两者的值相差较大时,表示存在(内部或者外部的)内存碎片。内存碎片的比率可以通过mem_fragmentation_ratio的值看出;
- 当used>rss时,表示Redis的部分内存被操作系统换出到交换空间,在这种情况下,操作可能会产生明显的延迟。
- used_memory #是你的Redis实例中所有key及其value占用的内存大小;
- used_memory_rss #是操作系统实际分配给Redis进程的内存。这个值一般是大于used_memory的,因为Redis的内存分配策略会产生内存碎片。
- used_fragmentation_ratio #就是内存碎片的比率,正常情况下是1左右,如果大于1比如1.8说明内存碎片很严重了
在使用redis经常会因为memory引发一些列的问题。像因为内存交换产生的性能问题以及延迟问题等。
1、使用Hash Redis在储存小于100个字段的Hash结构上,其存储效率是非常高的
2、设置key的过期时间
3、回收key
另外一定要配置/proc/sys/vm/min_free_kbytes 让系统及时回收内存
echo 102400 > /proc/sys/vm/min_free_kbytes 设置100m开始回收内存Persistence部分记录了RDB持久化和AOF持久化有关的信息:
- loading:0 #一个标志值,记录了服务器是否正在载入持久化文件
- rdb_changes_since_last_save:0 #距离最后一次成功创建持久化文件之后,改变了多少个键值
- rdb_bgsave_in_progress:0 #一个标志值,记录服务器是否正在创建RDB文件
- rdb_last_save_time:1427189587 #最近一次成功创建RDB文件的UNIX时间戳
- rdb_last_bgsave_status:ok #一个标志值,记录了最后一次创建RDB文件的结果是成功还是失败
- rdb_last_bgsave_time_sec:0 #记录最后一次创建RDB文件耗费的秒数
- rdb_current_bgsave_time_sec:-1 #如果服务器正在创建RDB文件,那么这个值记录的就是当前的创建RDB操作已经耗费了多长时间(单位为秒)
- aof_enabled:0 #一个标志值,记录了AOF是否处于打开状态
- aof_rewrite_in_progress:0 #一个标志值,记录了服务器是否正在创建AOF文件
- aof_rewrite_scheduled:0 #一个标志值,记录了RDB文件创建完之后,是否需要执行预约的AOF重写操作
- aof_last_rewrite_time_sec:-1 #记录了最后一次AOF重写操作的耗时
- aof_current_rewrite_time_sec:-1 #如果服务器正在进行AOF重写操作,那么这个值记录的就是当前重写操作已经耗费的时间(单位是秒)
- aof_last_bgrewrite_status:ok #一个标志值,记录了最后一次重写AOF文件的结果是成功还是失败
如果AOF持久化功能处于开启状态,那么在Persistence部分还会加上以下域:
- aof_current_size:14301 #AOF文件目前的大小
- aof_base_size:14301 #服务器启动时或者最近一次执行AOF重写之后,AOF文件的大小
- aof_pending_rewrite:0 #一个标志值,记录了是否有AOF重写操作在等待RDB文件创建完之后执行
- aof_buffer_length:0 # AOF缓冲区的大小
- aof_rewrite_buffer_length:0 #AOF重写缓冲区的大小
- aof_pending_bio_fsync:0 #在后台I/0队列里面,等待执行的fsync数量
- aof_delayed_fsync:0 #被延迟执行的fsync数量
Stats部分记录了一般的统计信息:
- total_connections_received:8 #服务器已经接受的连接请求数量
- total_commands_processed:10673 #服务器已经执行的命令数量
- instantaneous_ops_per_sec:0 #服务器每秒中执行的命令数量
- rejected_connections:0 #因为最大客户端数量限制而被拒绝的连接请求数量
- expired_keys:0 #因为过期而被自动删除的数据库键数量
- evicted_keys:0 #因为最大内存容量限制而被驱逐(evict)的键数量
- keyspace_hits:1 #查找数据库键成功的次数
- keyspace_misses:0 #查找数据库键失败的次数
- pubsub_channels:0 #目前被订阅的频道数量
- pubsub_patterns:0 #目前被订阅的模式数量
- latest_fork_usec:159 #最近一次fork()操作耗费的时间(毫秒)
因为Redis是个单线程模型,客户端过来的命令是按照顺序执行的。因此网络问题、慢命令会造成阻塞导致redis性能下降。
如果发生命令阻塞就可以看到每秒命令处理数在明显下降。要分析解决这个性能问题,需要跟踪命令处理数的数量和延迟时间。
cpu部分记录了CPU的计算量统计信息:
- used_cpu_sys:75.46 #Redis服务器耗费的系统CPU
- used_cpu_user:90.12 #Redis服务器耗费的用户CPU
- used_cpu_sys_children:0.00 #Redis后台进程耗费的系统CPU
- used_cpu_user_children:0.00 #Redis后台进程耗费的用户CPU
Keyspace部分记录了数据库相关的统计信息
如数据库的键数量、数据库已经被删除的过期键数量。对于每个数据库,这个部分会添加一行以下格式的信息:
db0:keys=25,expires=0,avg_ttl=0 #0号数据库有25个键、已经被删除的过期键数量为0个7.2 使用工具lepus 监控redis
搭建 lepus 监控redis
lepus官网:发布主题 – 第53页 – Lepus天兔开源企业级数据库监控系统
参考:
Redis入门——Key、五大数据类型图文详解_Code皮皮虾的博客-CSDN博客_redis的key是什么类型
-
相关阅读:
Android7.1.1系统,Toast的Exception: android.view.WindowManager$BadTokenException解决
Vue-video-player下载失败(npm i 报错)
深度学习框架简介
golang开发:go并发的建议(完)
cloudwu/coroutine 源码分析
【Github】 Github修改仓库的基本信息
微服务环境搭建
【图像误差测量】测量 2 张图像之间的差异,并测量图像质量(Matlab代码实现)
Vue3修改Element-plus语言与项目国际化
黑莓手机时代落幕;阿里巴巴为 Linux 内核调度器提出新概念;清理 Linux 内核“依赖地狱” | 开源日报
- 原文地址:https://blog.csdn.net/qq_39208536/article/details/126225475
