-
独立机器连接cdh的spark集群,远程提交任务(绝对可以成功,亲测了n遍)
我有4台机器 其中hadoop1-hadoop3是cdh集群,而hadoop4是一台普通的机器。我通过一台不属于cdh集群的机器,通过远程的方式,让cdh集群进行运算,而我本机不参与运算。
进行操作的流程如下:

要想理解远程提交,我们从2个方面去学习
1.了解原理和思路
2.进行操作了解原理思路
首先,我们来了解spatk基础常识
spark提交有4种
local ,standalone,yarn,memos
其中除了local模式外,其它的都能远程提交
local就是用本地spark执行,除了测试以外基本不会用,而且如果使用yarn模式或者其他模式,在代码中使用了local,还会导致spark-submit提交时,spark不知道以yarn模式运行还是以local模式执行,导致报错。因此local,我们只在idea测试代码使用,想打jar包,在用submit使用时需调度yarn模式或者其他模式的时候,会在idea代码内把master这行删除后,再进行打包。
standalone就是不依赖外部插件,纯靠spark集群进行任务 ,我们通过,master=spark://sparkmaster节点:7077
方式进行远程提交。在代码中通过,号进行分隔。
这种情况下,spark集群的启动模式,必须有master和work进程,否则无法连接到这个节点。而cdh默认是yarn模式 你需要自行启动 master和work 也就是spark集群的主从架构。
yarn模式 cdh的模式 ,也是国内最多的模式。好处就是yarn自动去分配资源和内存,当然,你也可以自己分配资源。
yarn又分为两种,client模式,cluster模式
这2种其实都是分配给集群去运行,而yarn默认的是client模式 可以通过设置yarn-mode进行更改。
client模式 是由当前节点启动driver,将任务提交给集群去执行,可以在当前节点,看到日志cluster模式 由当前节点提交到集群,又yarn随机分配一台机器,作为driver,再由driver提交任务交给集群去执行,当前机器看不到日志,只能在yarn服务的看到日志
这2种模式在生产环境其实都可以。
memos模式,听他们说效率也很高,对远程执行的操作更加友好(方便),但是很遗憾在国内,资料非常少。这里我也没找到他的相关学习资料,没有进行实验,这里不进行详细说明。
进行操作
这里,我们使用的是一台机器,我给他装了spark和hadoop,力求和cdh版本一样,所以我下的是spark2.4和hadoop3.0,因为cdh6.3.2也是这个版本。

当然你要先安装jdk,hadoop依赖java。
流程是这样:
spark-submit yarn提交任务,他会去读取HADOOP_HOME目录下yarn-site.xml以及其他配置,然后,通过driver去连接配置所对应的工作节点(集群上的节点),然后执行任务,将日志同步给本节点。
远程处理思路是这样:
将cdh的hadoop相关配置文件复制到本地hadoop的目录下,进行替换。由于本地hadoop目录下,没有自己节点的配置,所以提交集群后,他计算不会分到本地机器进行计算。但由于driver驱动在本地,所以可以获得到集群的处理日志信息。
正式操作:
1.首先上传和解压这2个文件,到/hadoop目录下
2.去cdh集群任意一台机器的/etc/hadoop目录拷贝下来(这个是cdh的hadoop配置目录)

3.在本地创建etc目录,将集群的/etc/hadoop目录放进去,做成和集群一样的目录
4.将/etc/hadoop(现在的这个就是cdh的配置文件),复制到本地hadoop软件的/etc目录下,进行覆盖hadoop,先将原来的进行备份。橙色部分为本地,安装的hadoop。只能用cp不能mv,因为cdh默认的配置会去找/etc/hadoop目录下的其他配置
cp -r /etc/hadoop/ /software/hadoop-3.0.0/etc/
5.环境变量配置
export JAVA_HOME=/software/jdk1.8.0_251
export PATH=$PATH:${JAVA_HOME}/bin
export HADOOP_HOME=/software/hadoop-3.0.0
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop/conf
export SPARK_HOME=/software/spark-2.4.0-bin-hadoop2.7
export PATH=$PATH:${SPARK_HOME}/bin
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
source /etc/profile
记得要配置hosts (所有节点),然后要关闭防火墙

6.测试
首先代表我没有骗你,我这里没有hadoop4

然后hadoop4 (104节点)

当然你也可以将jar包丢到hdfs上
spark-submit --class demo.test2_hive --master yarn hdfs://hadoop1/test/WordCount.jar
你看全是,hadoop2和hadoop3在作为内存节点
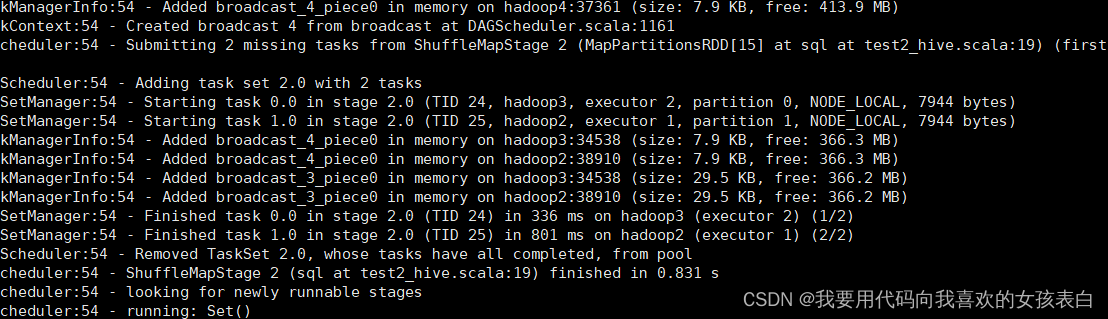
执行成功

-
相关阅读:
28.1.1 开启查询日志
SpringBoot异常处理
Linux Mint 的更新管理器现在支持 Flatpak
Python多任务编程
【仿牛客网笔记】Spring Boot实践,开发社区登录模块-账号设置,检查登录
加密货币为什么有价值?
Android 9.0 设备蓝牙、位置、WIFI、NFC功能默认关闭
java-php-net-python-四六级考试报名系统计算机毕业设计程序
Redis五大数据类型的底层设计
实现SSE的textevent-stream是什么?和applicationoctet-stream有什么区别?
- 原文地址:https://blog.csdn.net/qq_38403590/article/details/126222851