-
MXNet对含隐藏状态的循环神经网络(RNN)的实现
循环神经网络(RNN)跟前面介绍的卷积神经网络区别很大,卷积神经网络主要是处理空间信息,每层提取不同的特征,而RNN是处理时序信息的,时序信息就是说将一段文字或者声音等看作是一段离散的时间序列,按照时间进行输出的一种模型,本节主要介绍如何处理自然语言(Natural Language Processing NLP)。
比如一段语音的识别,“老板,来包福贵”,那可能会输出“老板,来包富贵”,因为fugui读音一样,这个时候就需要语言模型去判断两者的概率,输出大的即可,而语言模型如下:
把一段长度为T的文本里的词依次表示为W1,W2,W3,...,WT,那么在离散的时间序列中,Wt(1<=t<=T)看作在时间步t的输出或标签,该语言模型计算该序列的概率是P(W1,W2,W3,...,WT),计算公式是:
P(W1,W2,W3,...,WT)=∏P(Wt|W1,...,Wt-1),也就是该词出现的概率连乘前面每个词出现的条件概率。比如4个词文本序列的概率:P(W1,W2,W3,W4)=P(W1)*P(W2|W1)*P(W3|W1,W2)*P(W4|W1,W2,W3),那么这个词的概率可以通过该词的词频与训练数据集的总词数之比来计算。而条件概率比如P(W3|W1,W2)可以通过P(W1,W2,W3)这3个词的相邻频率与P(W1,W2)这2个相邻频率之比来获得。1.n元语法
如果序列很长,计算和存储这些概率的复杂度会呈现指数级的增加,这里使用n元语法通过马尔科夫假设来简化语言模型计算,也就是说一个词的出现只跟前面n个词有关(n阶马尔科夫链),当n分别是1、2、3时,我们将其分别称作一元语法、二元语法、三元语法,比如长度是4的序列W1,W2,W3,W4在一元、二元、三元语法中的概率分别是:
P(W1,W2,W3,W4)=P(W1)P(W2)P(W3)P(W4)
P(W1,W2,W3,W4)=P(W1)P(W2|W1)P(W3|W2)P(W4|W3)
P(W1,W2,W3,W4)=P(W1)P(W2|W1)P(W3|W1,W2)P(W4|W2,W3)当n较小时,n元语法往往并不准确,比如一元语法:“你走先”和“你先走”概率是一样的;然而当n较大时,n元语法又需要计算并存储大量的词频和多词相邻频率。于是平衡这两种方式的策略的RNN就出现了。
2.循环神经网络
我们可以先来看一张图,个人比较喜欢画图来直观表示流程和公式的展示。
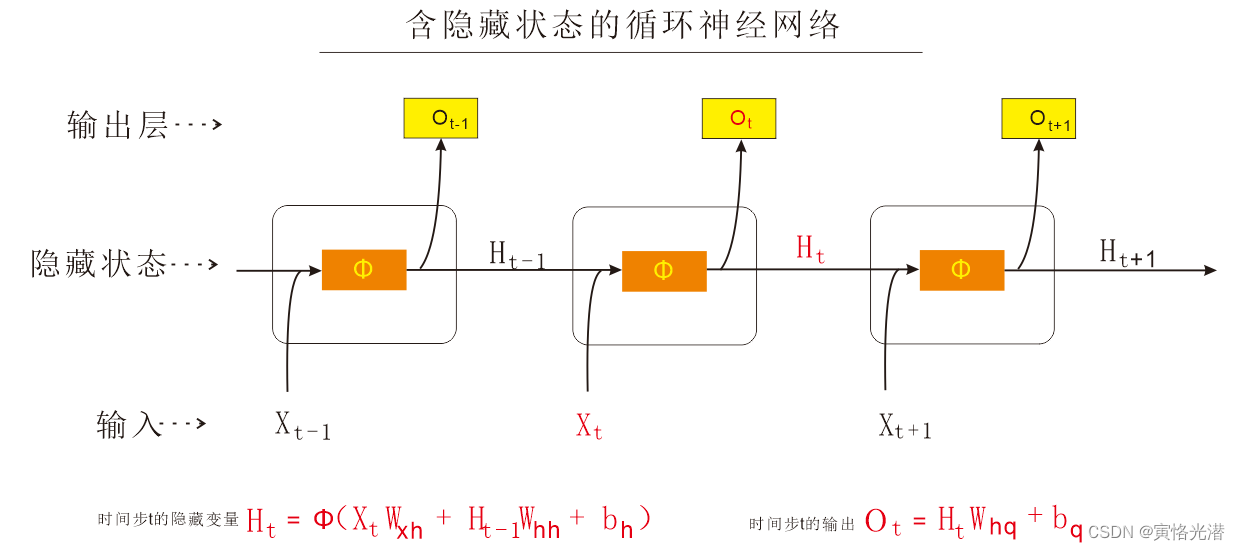
通过图我们可以看到,中间层是隐藏状态(隐藏变量),它的作用其实就是用来存储之前时间步的信息的,也就是可以将历史信息保留并传播下去,每个时间步都使用了上一时间步的隐藏状态,而这样的计算是循环的,所以叫做循环神经网络(Recurrent Neural Network)。
图中的公式还可以换一种等价的公式,就是将Xt与Ht-1连结后的矩阵乘以Wxh与Whh连结后的矩阵,举例验证下:- X,W_xh=nd.random.normal(shape=(3,1)),nd.random.normal(shape=(1,4))
- H,W_hh=nd.random.normal(shape=(3,4)),nd.random.normal(shape=(4,4))
- print(nd.dot(X,W_xh) + nd.dot(H,W_hh))
- print(nd.dot(nd.concat(X,H,dim=1),nd.concat(W_xh,W_hh,dim=0)))
- '''
- [[ 0.03172791 -0.40466753 -0.5573117 0.39783114]
- [ 3.3352664 2.2760866 1.135608 0.32824945]
- [ 4.352936 -1.3085628 -1.8609544 4.0762043 ]]
- [[ 0.03172791 -0.40466756 -0.5573117 0.39783114]
- [ 3.335266 2.2760866 1.1356078 0.32824934]
- [ 4.352936 -1.3085628 -1.8609543 4.0762043 ]]
- '''
2.1语言模型数据集
我们使用周杰伦歌词数据集来创作歌词jaychou_lyrics.txt.zip,下载之后是7z,解压之后是zip可以不解压成txt文档,直接通过zipfile模块来解压缩,下面下载的是解压后就是txt,那就直接读取即可,两种读取方式如下:
- import zipfile
- with zipfile.ZipFile('data/jaychou_lyrics.txt.zip') as zin:
- with zin.open('jaychou_lyrics.txt') as f:
- corpus_chars=f.read().decode('utf-8')
- with open('data/jaychou_lyrics.txt','rb') as f:
- corpus_chars=f.read().decode('utf-8')
然后需要对这些歌词做一本类似我们查词的“新华字典”,也就是对每个词建立一个对应的索引
- #建立字符索引
- #歌词总计有63282个(包括空格)去重之后有2582个字符
- corpus_chars=corpus_chars[:10000]#截取10000个字符来训练
- idx_to_char=list(set(corpus_chars))#去重之后是1027个,如:['桑', '拜', '拖', '心', '碎', '背', '的', '防', '白', '仔',...]
- char_to_idx=dict([(c,i) for i,c in enumerate(idx_to_char)])
- #print(char_to_idx['要'],char_to_idx)#349,{'桑': 0, '拜': 1, '拖': 2, '心': 3, '碎': 4, '背': 5, '的': 6, '防': 7,...}
- #训练数据集字符与索引的转换
- corpus_indices=[char_to_idx[c] for c in corpus_chars]
- print(corpus_indices[:10])
- print('字符:',''.join([idx_to_char[i] for i in corpus_indices])[:10])
- '''
- [789, 349, 390, 599, 18, 319, 413, 789, 349, 539]
- 字符: 想要有直升机 想要和
- '''
一本字典就做好了,我们在训练的时候,会每次随机读取小批量的样本和标签,此处的标签和以往不一样,因为是时序的数据,预测下一个字符,那么样本的标签序列就是这些字符分别在训练集中的下一个字符。另外需要注意的是,这个set每次去重之后的顺序是变化的。
我们有两种采样方式:2.2随机采样
每个样本都是在原始序列上面任意截取的一段序列,所以相邻的两个随机小批量在原始序列上的位置不一定相毗邻,我们也无法用一个小批量最终时间步的隐藏状态来初始化下一个小批量的隐藏状态,训练模型时每次随机采样前都需要重新初始化隐藏状态。
- #随机采样
- #batch_size:每个小批量的样本数,num_steps:每个样本的时间步数
- def data_iter_random(corpus_indices,batch_size,num_steps,ctx=None):
- num_examples=(len(corpus_indices)-1)//num_steps
- print(num_examples)
- epoch_size=num_examples//batch_size
- print(epoch_size)
- example_indices=list(range(num_examples))
- print(example_indices)
- random.shuffle(example_indices)
- #返回从pos开始的长为num_steps的序列
- def _data(pos):
- return corpus_indices[pos:pos+num_steps]
- for i in range(epoch_size):
- i=i*batch_size
- batch_indices=example_indices[i:i+batch_size]
- X=[_data(j*num_steps) for j in batch_indices]
- Y=[_data(j*num_steps+1) for j in batch_indices]
- yield nd.array(X,ctx),nd.array(Y,ctx)
- seq=list(range(50))
- for X,Y in data_iter_random(seq,batch_size=3,num_steps=4):
- print("输入",X,"\n标签",Y)
- '''
- 输入
- [[ 4. 5. 6. 7.]
- [44. 45. 46. 47.]
- [ 8. 9. 10. 11.]]
- 标签
- [[ 5. 6. 7. 8.]
- [45. 46. 47. 48.]
- [ 9. 10. 11. 12.]]
- 输入
- [[40. 41. 42. 43.]
- [28. 29. 30. 31.]
- [16. 17. 18. 19.]]
- 标签
- [[41. 42. 43. 44.]
- [29. 30. 31. 32.]
- [17. 18. 19. 20.]]
- 输入
- [[32. 33. 34. 35.]
- [36. 37. 38. 39.]
- [24. 25. 26. 27.]]
- 标签
- [[33. 34. 35. 36.]
- [37. 38. 39. 40.]
- [25. 26. 27. 28.]]
- 输入
- [[12. 13. 14. 15.]
- [ 0. 1. 2. 3.]
- [20. 21. 22. 23.]]
- 标签
- [[13. 14. 15. 16.]
- [ 1. 2. 3. 4.]
- [21. 22. 23. 24.]]
- '''
可以看出两个小批量之间顺序是打乱的,没有相毗邻。
2.3相邻采样
相邻采样可以让相邻的两个随机小批量在原序列中相毗邻,所以我们可以用一个小批量最终时间步的隐藏状态来初始化下一个小批量的隐藏状态, 从而使下一个小批量的输出也取决于当前小批量的输入,如此循环下去。这对实现循环神经网络造成两个影响:1、在训练模型时,只需要在每个迭代周期开始时初始化隐藏状态。2、 当多个相邻小批量通过传递隐藏状态串联起来时,模型参数的梯度计算将依赖所有的序列,所以在同一迭代周期中,随着迭代次数的增加,梯度计算开销会越来越大。
- def data_iter_consecutive(corpus_indices,batch_size,num_steps,ctx=None):
- corpus_indices=nd.array(corpus_indices,ctx=ctx)
- data_len=len(corpus_indices)
- batch_len=data_len//batch_size
- indices=corpus_indices[0:batch_size*batch_len].reshape((batch_size,batch_len))
- epoch_size=(batch_len-1)//num_steps
- for i in range(epoch_size):
- i=i*num_steps
- X=indices[:,i:i+num_steps]
- Y=indices[:,i+1:i+num_steps+1]
- yield X,Y
- seq=list(range(50))
- for X,Y in data_iter_consecutive(seq,batch_size=3,num_steps=4):
- print("输入",X,"\n标签",Y)
- '''
- 输入
- [[ 0. 1. 2. 3.]
- [16. 17. 18. 19.]
- [32. 33. 34. 35.]]
- 标签
- [[ 1. 2. 3. 4.]
- [17. 18. 19. 20.]
- [33. 34. 35. 36.]]
- 输入
- [[ 4. 5. 6. 7.]
- [20. 21. 22. 23.]
- [36. 37. 38. 39.]]
- 标签
- [[ 5. 6. 7. 8.]
- [21. 22. 23. 24.]
- [37. 38. 39. 40.]]
- 输入
- [[ 8. 9. 10. 11.]
- [24. 25. 26. 27.]
- [40. 41. 42. 43.]]
- 标签
- [[ 9. 10. 11. 12.]
- [25. 26. 27. 28.]
- [41. 42. 43. 44.]]
- '''
3.构造循环神经网络
为了将词表示成向量输入到神经网络,一个简单办法就是使用独热编码(one-hot)向量,除了这个词对应索引i所在的元素设置为1,其余全部为0,我们直接看示例:
- nd.one_hot(nd.array([1,3,5]),10)
- '''
- [[0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]
- [0. 0. 0. 1. 0. 0. 0. 0. 0. 0.]
- [0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]]
- '''
- nd.one_hot(nd.array([[1,2,4],[2,4,7]]),10)
- '''
- [[[0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]
- [0. 0. 1. 0. 0. 0. 0. 0. 0. 0.]
- [0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]]
- [[0. 0. 1. 0. 0. 0. 0. 0. 0. 0.]
- [0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]
- [0. 0. 0. 0. 0. 0. 0. 1. 0. 0.]]]
- '''
- print(nd.one_hot(nd.array(nd.array([[1,2,4],[2,4,7]]).T),10))
- print(nd.array([[1,2,4],[2,4,7]]).T)
- '''
- [[[0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]
- [0. 0. 1. 0. 0. 0. 0. 0. 0. 0.]]
- [[0. 0. 1. 0. 0. 0. 0. 0. 0. 0.]
- [0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]]
- [[0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]
- [0. 0. 0. 0. 0. 0. 0. 1. 0. 0.]]]
- [[1. 2.]
- [2. 4.]
- [4. 7.]]
- '''
- 针对循环神经网络做的一个独热编码函数(自带有):
- def to_onehot(X,size):
- return [nd.one_hot(x,size) for x in X.T]
- X=nd.arange(10).reshape((2,5))
- print(X)
- inputs=to_onehot(X,10)#d2l.to_onehot(X,10)
- print(inputs)
- '''
- [[0. 1. 2. 3. 4.]
- [5. 6. 7. 8. 9.]]
- [
- [[1. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
- [0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]]
, - [[0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]
- [0. 0. 0. 0. 0. 0. 1. 0. 0. 0.]]
, - [[0. 0. 1. 0. 0. 0. 0. 0. 0. 0.]
- [0. 0. 0. 0. 0. 0. 0. 1. 0. 0.]]
, - [[0. 0. 0. 1. 0. 0. 0. 0. 0. 0.]
- [0. 0. 0. 0. 0. 0. 0. 0. 1. 0.]]
, - [[0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]
- [0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]]
] - '''
3.1建立模型
现在开始构造神经网络,以周杰伦专辑歌词数据集训练模型来创作歌词。
- import d2lzh as d2l
- from mxnet import autograd,gluon,init,nd
- from mxnet.gluon import data as gdata,loss as gloss,nn,rnn
- import random
- import zipfile
- #FileNotFoundError: [Errno 2] No such file or directory: '../data/jaychou_lyrics.txt.zip'
- #调用自带的需要注意路径,本人为了图简单,直接将data目录拷贝到上一级目录里
- corpus_indices,char_to_idx,idx_to_char,vocab_size=d2l.load_data_jay_lyrics()
- #初始化模型参数
- #ctx=d2l.try_gpu()
- ctx=None
- num_inputs,num_hiddens,num_outputs=vocab_size,256,vocab_size
- def get_params():
- def _one(shape):
- return nd.random.normal(scale=0.01,shape=shape,ctx=ctx)
- #隐藏层参数
- W_xh=_one((num_inputs,num_hiddens))
- W_hh=_one((num_hiddens,num_hiddens))
- b_h=nd.zeros(num_hiddens,ctx=ctx)
- #输出参数
- W_hq=_one((num_hiddens,num_outputs))
- b_q=nd.zeros(num_outputs,ctx=ctx)
- #附上梯度
- params=[W_xh,W_hh,b_h,W_hq,b_q]
- for p in params:
- p.attach_grad()
- return params
- #定义模型
- #返回初始化的隐藏状态,使用元组便于处理隐藏状态含有多个NDArray的情况
- def init_rnn_state(batch_size,num_hiddens,ctx):
- return (nd.zeros(shape=(batch_size,num_hiddens),ctx=ctx),)
- #计算隐藏状态与输出
- def rnn(inputs,state,params):
- W_xh,W_hh,b_h,W_hq,b_q=params
- H,=state#state是元组,加逗号转成列表,可以简单看做去括号
- outputs=[]
- for X in inputs:
- H=nd.tanh(nd.dot(X,W_xh)+nd.dot(H,W_hh)+b_h)
- Y=nd.dot(H,W_hq)+b_q
- outputs.append(Y)
- return outputs,(H,)
- #观察输出和隐藏状态的形状
- X=nd.arange(10).reshape((2,5))
- state=init_rnn_state(X.shape[0],num_hiddens,ctx)#(2,256)
- #inputs=d2l.to_onehot(X.as_in_context(ctx),vocab_size)
- inputs=d2l.to_onehot(X,vocab_size)
- params=get_params()
- outputs,state_new=rnn(inputs,state,params)
- print(len(outputs),state_new[0].shape,outputs[0].shape)#5 (2, 256) (2, 1027)
- #预测函数,d2lzh已有
- def predict_rnn(prefix,num_chars,rnn,params,init_rnn_state,num_hiddens,vocab_size,ctx,idx_to_char,char_to_idx):
- state=init_rnn_state(1,num_hiddens,ctx)
- output=[char_to_idx[prefix[0]]]
- for t in range(num_chars+len(prefix)-1):
- X=d2l.to_onehot(nd.array([output[-1]],ctx=ctx),vocab_size)#上一时间步的输出作为当前时间步的输入
- Y,state=rnn(X,state,params)#计算输出与更新隐藏状态
- if t<len(prefix)-1:
- output.append(char_to_idx[prefix[t+1]])
- else:
- output.append(int(Y[0].argmax(axis=1).asscalar()))
- return ''.join([idx_to_char[i] for i in output])
- predict_rnn('分开',10,rnn,params,init_rnn_state,num_hiddens,vocab_size,ctx,idx_to_char,char_to_idx)
- '分开拿到作中处社晰宣节办'
3.2裁剪梯度与困惑度
在循环神经网络中,容易出现梯度衰减或梯度爆炸,这就造成了模型的不稳定,要么失控要么没法学习下去,为了预防这种情况,我们使用裁剪梯度。假设我们把所有模型参数梯度的元素拼接成一个向量g,并设置裁剪梯度的阈值为θ,裁剪后的梯度:g←min(1,θ / ||g||) * g,||g||是L2范数,也就是说梯度g的范数大于了阈值,就做裁剪,避免爆炸
代码如下(d2lzh包已有):- def grad_clipping(params,theta,ctx):
- norm=nd.array([0],ctx)
- for param in params:
- norm+=(param.grad**2).sum()
- norm=norm.sqrt().asscalar()
- if norm>theta:
- for param in params:
- param.grad[:]*=theta/norm
在前面介绍的卷积神经网络使用的是损失函数或精度来评价模型,这里我们使用困惑度(perplexity)来评价语言模型的好坏,困惑度是对交叉熵损失函数做指数运算后得到的值。
1、最佳情况,模型总是把标签类别的概率预测为1,此时困惑度为1
2、最坏情况,模型总是把标签类别的概率预测为0,此时困惑度为正无穷
3、基线情况,模型总是预测所有类别的概率都一样,此时困惑度就是类别的个数那么对于一个有效模型的困惑必须是小于基线情况才行,也就是困惑度小于类别个数(词典大小)现在通过裁剪梯度以及困惑度来训练与评估模型
- #训练并通过困惑度来评估,d2lzh包已有
- def train_and_predict_rnn(rnn,get_params,init_rnn_state,num_hiddens,vocab_size,ctx,corpus_indices,idx_to_char,char_to_idx,
- is_random_iter,num_epochs,num_steps,lr,clipping_theta,batch_size,pred_period,pred_len,prefixes):
- if is_random_iter:
- data_iter_fn=d2l.data_iter_random
- else:
- data_iter_fn=d2l.data_iter_consecutive
- params=get_params()
- loss=gloss.SoftmaxCrossEntropyLoss()
- for epoch in range(num_epochs):
- #相邻采样,epoch开始时初始化隐藏状态
- if not is_random_iter:
- state=init_rnn_state(batch_size,num_hiddens,ctx)
- l_sum,n,start=0.0,0,time.time()
- data_iter=data_iter_fn(corpus_indices,batch_size,num_steps,ctx)
- for X,Y in data_iter:
- #随机采样需每个小批量更新前初始化隐藏状态
- if is_random_iter:
- state=init_rnn_state(batch_size,num_hiddens,ctx)
- #相邻采样就将隐藏状态从计算图中分离
- else:
- for s in state:
- s.detach()
- with autograd.record():
- inputs=d2l.to_onehot(X,vocab_size)
- outputs,state=rnn(inputs,state,params)
- outputs=nd.concat(*outputs,dim=0)
- y=Y.T.reshape((-1,))
- l=loss(outputs,y).mean()#交叉熵损失计算平均分类误差
- l.backward()
- #裁剪梯度(迭代模型参数之前)
- grad_clipping(params,clipping_theta,ctx)
- d2l.sgd(params,lr,1)
- l_sum+=l.asscalar()*y.size
- n+=y.size
- if(epoch+1)%pred_period==0:
- print('epoch %d,perplexity %f,time %.2f sec' % (epoch+1,math.exp(l_sum/n),time.time()-start))
- for prefix in prefixes:
- print(predict_rnn(prefix,pred_len,rnn,params,init_rnn_state,num_hiddens,vocab_size,ctx,idx_to_char,char_to_idx))
- num_epochs,num_steps,batch_size,lr,clipping_theta=250,35,32,1e2,1e-2
- pred_period,pred_len,prefixes=50,50,['分开','不分开']
- train_and_predict_rnn(rnn,get_params,init_rnn_state,num_hiddens,vocab_size,ctx,corpus_indices,idx_to_char,char_to_idx,
- True,num_epochs,num_steps,lr,clipping_theta,batch_size,pred_period,pred_len,prefixes)
- '''
- epoch 50,perplexity 69.879726,time 1.67 sec
- 分开 我想要你想你 你知我不 你是了 一子两 我想要你 你着我 别子我 别你的让我疯狂的可爱女人 坏坏的
- 不分开 我爱你这你的 我想要这 你着我 别子我 别你我 我不要你想你 你知你不 你着了双 你的让我 你的
- epoch 100,perplexity 10.730620,time 1.41 sec
- 分开 一颗两双 在谁耿中 你一定梦 你一定梦 你一定梦 你一定梦 你一定梦 你一定梦 你一定梦 你一定梦
- 不分开吗 单天在双 在小村外的溪边 默默等的 娘果我的见头 有话是你 全要我不见 你不定 在我的脚快 银
- epoch 150,perplexity 3.033938,time 1.39 sec
- 分开 一直用停留都的母斑鸠 印地安老斑鸠 腿短毛不多 除非是人鸦抢了它能活 脑袋瓜有一点秀逗 猎物 夕吸
- 不分开吗 我想你爸 你打的事 就人梦向 我有定受 你在的梦 你的梦空 我想揍你 经再的从快极银 我古 伊原
- epoch 200,perplexity 1.610590,time 1.39 sec
- 分开球默会这样的在淡 能不斜过去圈的誓言 一切又重演 祭司 神殿 征战 弓箭 是谁的从前 喜欢在人潮中你
- 不分开扫 然后将过去 慢慢温习 让我爱上你 那场悲剧 是你完美演出的一场戏 宁愿心碎哭泣 再狠狠忘记 你爱
- epoch 250,perplexity 1.335831,time 1.43 sec
- 分开球默会记等 在原上的是不 然无过 一直两 我想就这样牵着你的手不放开 爱可不可以永简单纯没有悲哀 我
- 不分开吗 然后将过去 慢慢温习 让我爱上你 那场悲剧 是你完美演出的一场戏 宁愿心碎哭泣 再狠狠忘记 你爱
- '''
如果不裁剪梯度,大家可以试试看有什么结果,测试将会出现溢出错误:
OverflowError: math range error
超出了数值范围,问题出在了指数函数math.exp的l_sum/n值上,大于了709。
然后将is_random_iter设置为False,大家可以看下相邻采样的结果。4.简洁实现
- corpus_indices,char_to_idx,idx_to_char,vocab_size=d2l.load_data_jay_lyrics()
- #定义模型
- num_hiddens,batch_size,num_steps=256,2,35
- rnn_layer=rnn.RNN(num_hiddens,3)
- rnn_layer.initialize()
- state=rnn_layer.begin_state(batch_size=batch_size)
- print(state[0].shape)#(3, 2, 256)(隐藏层个数,批量大小,隐藏单元个数)
- X=nd.random.uniform(shape=(num_steps,batch_size,vocab_size))
- Y,state_new=rnn_layer(X,state)
- print(Y.shape,len(state_new),state_new[0].shape)#(35, 2, 256) 1 (3, 2, 256)
- #循环神经网络模块,在d2lzh中已有
- class RNNModel(nn.Block):
- def __init__(self,rnn_layer,vocab_size,**kwargs):
- super(RNNModel,self).__init__(**kwargs)
- self.rnn=rnn_layer
- self.vocab_size=vocab_size
- self.dense=nn.Dense(vocab_size)
- def forward(self,inputs,state):
- X=nd.one_hot(inputs.T,self.vocab_size)
- Y,state=self.rnn(X,state)
- #output=self.dense(Y.reshape((-1,Y.shape[-1])))
- output=self.dense(Y)
- return output,state
- def begin_state(self,*args,**kwargs):
- return self.rnn.begin_state(*args,**kwargs)
- #预测函数,在d2lzh中已有
- def predict_rnn_gluon(prefix,num_chars,model,vocab_size,ctx,idx_to_char,char_to_idx):
- state=model.begin_state(batch_size=1,ctx=ctx)
- output=[char_to_idx[prefix[0]]]
- for t in range(num_chars+len(prefix)-1):
- X=nd.array([output[-1]],ctx=ctx).reshape((1,1))
- (Y,state)=model(X,state)
- if t<len(prefix)-1:
- output.append(char_to_idx[prefix[t+1]])
- else:
- output.append(int(Y.argmax(axis=1).asscalar()))
- return ''.join([idx_to_char[i] for i in output])
- ctx=None
- #ctx=d2l.try_gpu()
- model=RNNModel(rnn_layer,vocab_size)
- model.initialize(force_reinit=True,ctx=ctx)
- print(predict_rnn_gluon('分开',10,model,vocab_size,ctx,idx_to_char,char_to_idx))
- '''
- 分开录器哀豆器耍逗种勉刚
- '''
- #训练模型,在d2lzh中已有
- def train_and_predict_rnn_gluon(model,num_hiddens,vocab_size,ctx,corpus_indices,idx_to_char,char_to_idx,
- num_epochs,num_steps,lr,clipping_theta,batch_size,pred_period,pred_len,prefixes):
- loss=gloss.SoftmaxCrossEntropyLoss()
- model.initialize(ctx=ctx,force_reinit=True,init=init.Normal(0.01))
- trainer=gluon.Trainer(model.collect_params(),'sgd',{'learning_rate':lr,'momentum':0,'wd':0})
- for epoch in range(num_epochs):
- l_sum,n,start=0.0,0,time.time()
- data_iter=d2l.data_iter_consecutive(corpus_indices,batch_size,num_steps,ctx)
- state=model.begin_state(batch_size=batch_size,ctx=ctx)
- for X,Y in data_iter:
- for s in state:
- s.detach()
- with autograd.record():
- (output,state)=model(X,state)
- y=Y.T.reshape((-1,))
- l=loss(output,y).mean()
- l.backward()
- #梯度裁剪
- params=[p.data() for p in model.collect_params().values()]
- d2l.grad_clipping(params,clipping_theta,ctx)
- trainer.step(1)
- l_sum += l.asscalar()*y.size
- n+=y.size
- if (epoch+1)%pred_period==0:
- print('epoch %d,perplexity %f,time %.2f sec ' % (epoch+1,math.exp(l_sum/n),time.time()-start))
- for prefix in prefixes:
- print(predict_rnn_gluon(prefix,pred_len,model,vocab_size,ctx,idx_to_char,char_to_idx))
- num_epochs,batch_size,lr,clipping_theta=250,32,1e2,1e-2
- pred_period,pred_len,prefixes=50,50,['分开','不分开']
- train_and_predict_rnn_gluon(model,num_hiddens,vocab_size,ctx,corpus_indices,idx_to_char,char_to_idx,
- num_epochs,num_steps,lr,clipping_theta,batch_size,pred_period,pred_len,prefixes)
MXNetError: [12:56:29] c:\projects\mxnet-distro-win\mxnet-build\3rdparty\dmlc-core\include\dmlc\./any.h:286: Check failed: type_ != nullptr The any container is empty requested=class mxnet::Imperative::AGInfo
如果出现上述错误,那就是内存不够,然后换成GPU计算即可。
- '''
- epoch 50,perplexity 139.032945,time 0.11 sec
- 分开 想坏
- 不分开 我不要 想坏
- epoch 100,perplexity 23.330386,time 0.11 sec
- 分开著我我我的你界最不了的你人相思寄红豆那场悲剧 我将我这辈子注定一个人演戏默语不著我想上你没牵着你的手
- 不分开让我疯狂的可爱女人 坏坏的让我疯狂的可爱女人 坏坏的让我疯狂的可爱女人 坏坏的让我疯狂的可爱女人 坏
- epoch 150,perplexity 5.121261,time 0.11 sec
- 分开熬的淡淡 干切抢篮多人除驳的砖墙我铺到榉斯坦堡著我像能和远远句么找也等不直 一果我遇见你是一场悲剧
- 不分开让我感狂的可爱女人 坏坏的让我疯狂的可爱女人 坏坏的让我疯狂的可爱女人 坏坏的让我疯狂的可爱女人 坏
- epoch 200,perplexity 1.931705,time 0.12 sec
- 分开 你分啊被远球 的那望开怎么小 就怎么每天祈祷了雕愿 看远女决 不能承受每已无处 旧每开的 偷一出痛
- 不分开让我感狂的可爱女人 坏坏的让你疯狂的可爱女人 坏坏的让我疯狂的可爱女人 坏坏的让你疯狂的可爱女人 坏
- epoch 250,perplexity 1.320265,time 0.11 sec
- 分开书有会 随水已潮起个见 瞎透了我 说你句如果说的离望力够临变沼泽 灰狼啃食的牛肉暴力默回开 我我它让
- 不分开让我感动的可爱女人想成漂泊心伤透单在每人风口不友 一透水我 全你会呵落当 快使用双截棍 哼哼哈兮 如
- '''
-
相关阅读:
Java基础系列(七)——多线程
【Go语言】项目实战:客户信息管理系统(需求分析、项目设计、功能实现)
PCL-MAL 聚己内酯马来酰亚胺
Map集合详细讲解
前端面试题日常练-day45 【面试题】
【Python学习篇】Python基础入门学习——Python基础语法(二)
Monaco Editor教程(十二):使用Marker来增加分词注释,标记,优化编辑器交互体验
你的数据库到底应该如何存储密码?
计算机硬件和软件
字节跳动后端面经
- 原文地址:https://blog.csdn.net/weixin_41896770/article/details/126231680
