-
数组 冒泡排序
目录
一、数组(array)
变量:存储单个元素的内存空间
数组:存储多个元素的连续的内存空间,相当于多个变量的集合1.数组的作用
(1)多个元素的组合,变量的集合
(2)将相同特性的一类数据存进数组中。(3)区分数据: 给每个元素编号
2.数组的分类
(1)普通数组
(2)关联数组
3.数组名和索引
索引的编号(下标)从0开始,属于数值索引
索引可支持使用自定义的格式,而不仅是数值格式,即为关联索引
索引可以不连续3.声明数组
普通数组可以不事先声明,直接使用
关联数组必须先声明,再使用4.数组定义方法
(1)一个一个赋值
(2)一起赋值1)方法一:
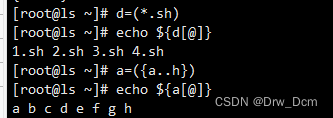
数组名=(value0 value1 value2 ...)2)方法二:
数组名=([0]=value [1]=value [2]=value ...)3)方法三:
列表名="value0 value1 value2 ..."
数组名=($列表名)4)方法四:
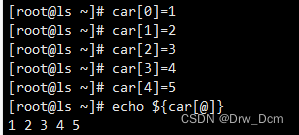
数组名[0]="value"
数组名[1]="value"
数组名[2]="value"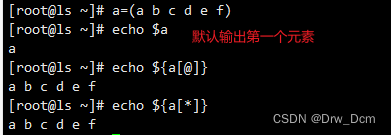

关联数组:
(1)要先声明
(2)赋值
a=(元素1 元素2 元素3 元素4 元素5 ......) 定义数组a
echo ${a[@]} 打印所有元素
echo ${a[*]} 打印所有元素
echo ${#a[*]} 查看数组中有几个元素 数组的长度 a 是数组的名字
echo ${#a[下标]} 查看数组中单独的元素 下标从0开始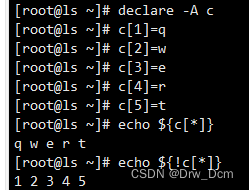


5.数组包括的数据类型
(1)数值类型
(2)字符类型
(3)混合型数值加字符:使用" "或' '定义单引号或双引号括起来数组遍历
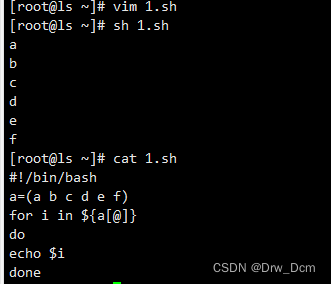
数组切片(截取需要的元素部分)
${a[@]:开始下标:结束下标} !表示显示所有下标

数组追加元素

数组替换

数组删除

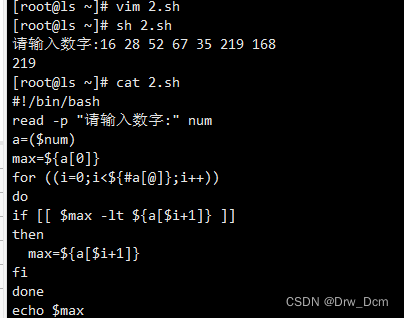
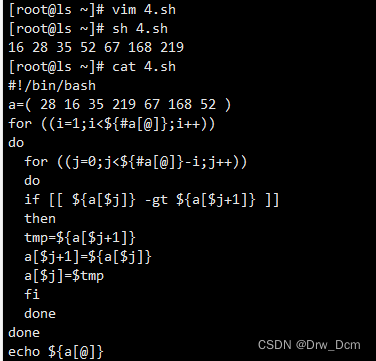
二、冒泡排序
类似气泡上涌的动作,会将数据在数组中从小到大或者从大到小不断的向前移动。
冒泡排序的基本思想是对比相邻的两个元素值,如果满足条件就交换元素值,把较小的元素移动到数组前面,把大的元素移动到数组后面(也就是交换两个元素的位置),这样较小的元素就像气泡一样从底部上升到顶部。
冒泡算法由双层循环实现,其中外部循环用于控制排序轮数,一般为要排序的数组长度减1次,因为最后一次循环只剩下一个数组元素,不需要对比,同时数组已经完成排序了。而内部循环主要用于对比数组中每个相邻元素的大小,以确定是否交换位置,对比和交换次数随排序轮数而减少。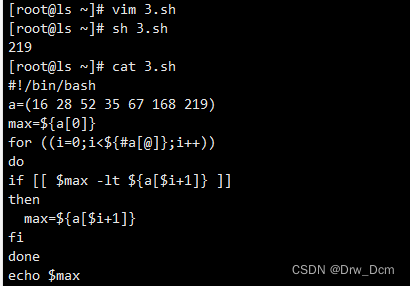
-
相关阅读:
TCP协议详解
汽车电子专业知识篇(五十九)-一文带你全面了解汽车电脑ECU的内部构成、功能模块
SQL审核 | 如何利用 OpenAPI 实现自己的扫描任务
MySQL查询优化
阿里财报中的饿了么:守正出奇
【Linux】进程控制
21.1 stm32使用LTDC驱动LCD--配置说明
CSS 布局 (三) 浮动、定位、多列布局
【PAT甲级 - C++题解】1093 Count PAT‘s
CTF-Misc——图片分析
- 原文地址:https://blog.csdn.net/Drw_Dcm/article/details/126229744