-
springboot上传word/doc/docx文档(含图片)与HTML富文本导入/导出互相转换解析!超级硬核qaq
测试效果
先看下效果
文档内容如下:
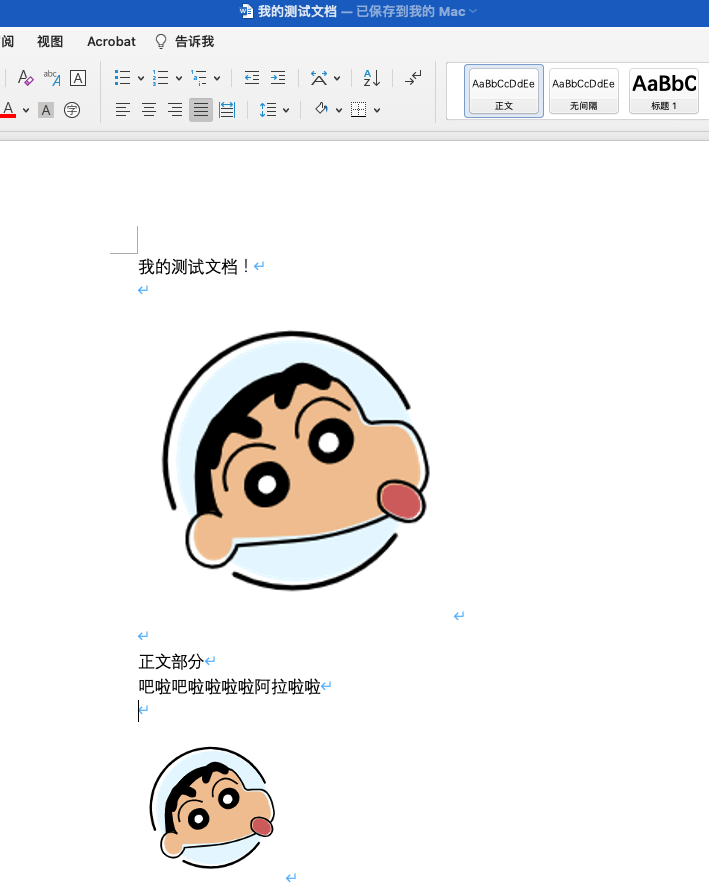
上传
上传docx文档
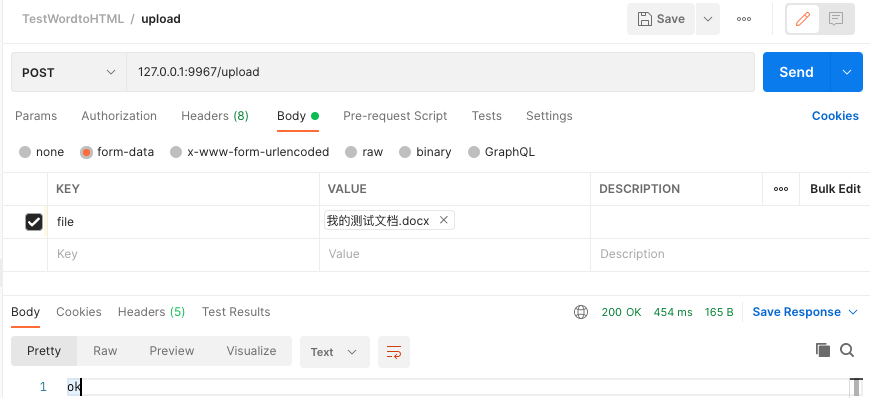
查看解析内容<html><head><style>p{margin-top:0pt;margin-bottom:1pt;}p.a{text-align:justified;}p.X1{margin-top:17.0pt;margin-bottom:16.5pt;}span.X1{font-size:22.0pt;font-weight:bold;}span.X10{font-size:22.0pt;font-weight:bold;}style>head><body><div style="width:595.3pt;margin-bottom:72.0pt;margin-top:72.0pt;margin-left:90.0pt;margin-right:90.0pt;"><p>我的测试文档!p><p><br/>p><p><img src="1659939780312/word/media/image1.png" style="width:200.0pt;height:200.0pt;"/>p><p><br/>p><p>正文部分p><p>吧啦吧啦啦啦啦阿拉啦啦p>div>body>html>- 1

上传doc文档
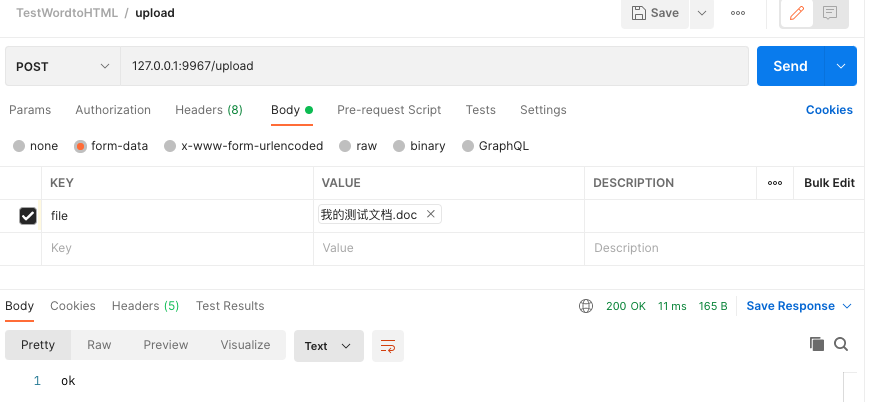
查看解析内容<html><head><META http-equiv="Content-Type" content="text/html; charset=utf-8"><style type="text/css">.b1{white-space-collapsing:preserve;}.b2{margin: 1.0in 1.25in 1.0in 1.25in;}.p1{text-align:justify;hyphenate:auto;font-family:Times New Roman;font-size:10pt;}style><meta content="Student" name="author">head><body class="b1 b2"><p class="p1"><span>我的测试文档!span>p><p class="p1">p><p class="p1"><img src="1659940657795.jpg" style="width:2.7777777in;height:2.7777777in;vertical-align:text-bottom;">p><p class="p1">p><p class="p1"><span>正文部分span>p><p class="p1"><span>吧啦吧啦啦啦啦阿拉啦啦span>p><p class="p1">p><p class="p1"><img src="1659940657795.jpg" style="width:1.3083333in;height:1.3083333in;vertical-align:text-bottom;">p>body>html>- 1
导出
利用刚刚解析出来的HTML导出为Word
访问导出接口即可下载文档

导出效果

实现原理
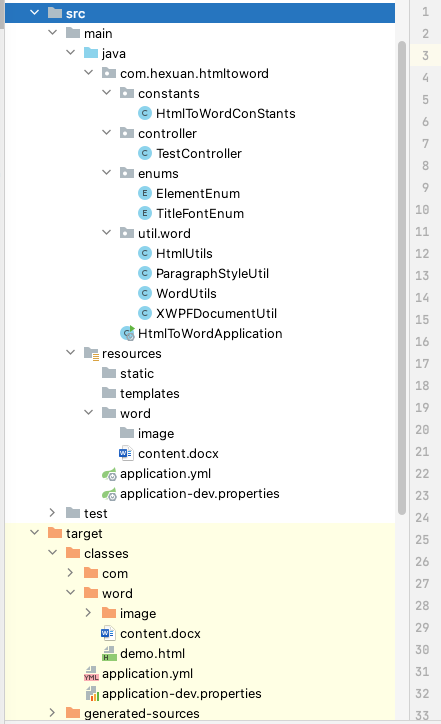
代码结构
注意target/classes/word/image目录和content.docx模版文档要存在
content.docx中的内容就是content:
依赖
<dependency> <groupId>cn.afterturngroupId> <artifactId>easypoi-spring-boot-starterartifactId> <version>4.2.0version> dependency> <dependency> <groupId>org.jsoupgroupId> <artifactId>jsoupartifactId> <version>1.13.1version> dependency> <dependency> <groupId>org.docx4jgroupId> <artifactId>docx4jartifactId> <version>3.3.6version> <exclusions> <exclusion> <groupId>org.slf4jgroupId> <artifactId>slf4j-log4j12artifactId> exclusion> exclusions> dependency> <dependency> <groupId>com.deepoovegroupId> <artifactId>poi-tlartifactId> <version>1.6.0-beta1version> dependency> <dependency> <groupId>org.apache.poigroupId> <artifactId>poiartifactId> <version>3.17version> dependency> <dependency> <groupId>org.apache.poigroupId> <artifactId>poi-scratchpadartifactId> <version>3.17version> dependency> <dependency> <groupId>org.apache.poigroupId> <artifactId>poi-ooxmlartifactId> <version>3.17version> dependency> <dependency> <groupId>fr.opensagres.xdocreportgroupId> <artifactId>xdocreportartifactId> <version>2.0.1version> dependency> <dependency> <groupId>org.apache.poigroupId> <artifactId>poi-ooxml-schemasartifactId> <version>3.17version> dependency> <dependency> <groupId>org.apache.poigroupId> <artifactId>ooxml-schemasartifactId> <version>1.4version> dependency> <dependency> <groupId>org.apache.commonsgroupId> <artifactId>commons-lang3artifactId> <version>3.7version> dependency>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
思路
上传word文件,解析出HTML内容,图片存储到定义好的静态资源目录,主题HTML文档中img的src存储的是相对路径
当导出word文件时,先对HTML文档img的src进行解析,增加服务器的静态资源访问位置路径,这样就能访问到图片输出为word
可以根据需求可以替换成图片资源服务器~静态资源配置
用于定义图片存储和模版文件等
application.ymlspring: application: name: hotevent-service undertow: buffer-size: 1024 direct-buffers: true profiles: active: dev resources: static-locations: ${res.src} servlet: multipart: enabled: true #是否启用http上传处理 max-request-size: 100MB #最大请求文件的大小 max-file-size: 20MB #设置单个文件最大长度 file-size-threshold: 20MB #当文件达到多少时进行磁盘写入 #当前应用相关的配置请在app下添加 app: resource-img-path: ${app.resource-img-path.val} upload-img-path: ${app.upload-img-path.val}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
application-dev.properties
# 应用名称 spring.application.name=html-to-word # 应用服务 WEB 访问端口 server.port=9967 app.upload-img-path.val=/Users/cat/Documents/image/ app.resource-img-path.val=http://127.0.0.1:9967/ #富文本内图片url前缀 app.html.url.head=http://127.0.0.1:9967/image/ # 富文本导出 word 模版路径 word.src=word/content.docx #静态资源映射路径, 用于存储解析的图片 res.src=file:/Users/cat/Desktop/html-to-word/target/classes/word res.word=/Users/cat/Desktop/html-to-word/target/classes/word/- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
代码实现
HtmlToWordConStants 常量类
package com.hexuan.htmltoword.constants; /** * 处理富文本公共常量 * * @author hexuan.wang */ public class HtmlToWordConStants { /** * 固定元素节点 */ public static final String COMMONATTR = "data-class"; /** * html标签 */ public static final String HTML_ELEMENT = ""; /** * word转html的默认文件名 */ public static final String DEMO_HTML = "demo.html"; /** * doc文件后缀 */ public static final String DOC = ".doc"; /** * docx文件后缀 */ public static final String DOCX = ".docx"; /** * 图片默认缩放宽度 */ public static final String IMG_WIDTH = "400"; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
TestController 接口测试案例
package com.hexuan.htmltoword.controller; import com.hexuan.htmltoword.constants.HtmlToWordConStants; import com.hexuan.htmltoword.util.word.ExcelUtils; import com.hexuan.htmltoword.util.word.XWPFDocumentUtil; import fr.opensagres.poi.xwpf.converter.core.BasicURIResolver; import fr.opensagres.poi.xwpf.converter.core.FileImageExtractor; import fr.opensagres.poi.xwpf.converter.xhtml.XHTMLConverter; import fr.opensagres.poi.xwpf.converter.xhtml.XHTMLOptions; import org.apache.commons.lang3.StringUtils; import org.apache.poi.hwpf.HWPFDocument; import org.apache.poi.hwpf.converter.PicturesManager; import org.apache.poi.hwpf.converter.WordToHtmlConverter; import org.apache.poi.hwpf.usermodel.PictureType; import org.apache.poi.openxml4j.opc.OPCPackage; import org.apache.poi.xwpf.usermodel.XWPFDocument; import org.jsoup.Jsoup; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; import org.springframework.beans.factory.annotation.Value; import org.springframework.web.bind.annotation.*; import org.springframework.web.multipart.MultipartFile; import org.w3c.dom.Document; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException; import javax.xml.transform.OutputKeys; import javax.xml.transform.Transformer; import javax.xml.transform.TransformerException; import javax.xml.transform.TransformerFactory; import javax.xml.transform.dom.DOMSource; import javax.xml.transform.stream.StreamResult; import java.io.*; import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; /** * 正常接口返回通用返回对象,这里只是为了演示word与html的互相转换返回的String */ @RestController public class TestController { @Value("${word.src}") private String exportWordSrc; @Value("${res.word}") private String resWord; @Value("${app.html.url.head}") private String htmlUrlHead; /** * 文件上传 * * @param file 上传文件 * @return * @throws Exception */ @PostMapping(value = "/upload") public String upload(@RequestParam("file") MultipartFile file) throws Exception { String message = "success"; if (!file.isEmpty()) { StringBuilder context = new StringBuilder(); try { if (file.getOriginalFilename().endsWith(HtmlToWordConStants.DOC)) { docToHtml(file); } else if (file.getOriginalFilename().endsWith(HtmlToWordConStants.DOCX)) { docxToHtml(file); } else { message = "格式有误,只允许doc,docx的word文件"; return message; } } catch (FileNotFoundException e) { e.printStackTrace(); message = "操作失败"; return message; } String content = readFileByLines(resWord + HtmlToWordConStants.DEMO_HTML); System.out.println(content); } return "ok"; } /** * 逐行读取文件 * * @param fileName * @return */ public static String readFileByLines(String fileName) { FileInputStream file = null; BufferedReader reader = null; InputStreamReader inputFileReader = null; String content = ""; String tempString = null; try { file = new FileInputStream(fileName); inputFileReader = new InputStreamReader(file, "utf-8"); reader = new BufferedReader(inputFileReader); // 一次读入一行,直到读入null为文件结束 while ((tempString = reader.readLine()) != null) { content += tempString; } reader.close(); } catch (IOException e) { e.printStackTrace(); return null; } finally { if (reader != null) { try { reader.close(); } catch (IOException e1) { } } } return content; } /** * doc转html 输出到资源/word/demo.html * * @param file * @throws TransformerException * @throws IOException * @throws ParserConfigurationException */ void docToHtml(MultipartFile file) throws TransformerException, IOException, ParserConfigurationException { HWPFDocument hwpfDocument = new HWPFDocument(file.getInputStream()); WordToHtmlConverter converter = new WordToHtmlConverter(DocumentBuilderFactory.newInstance().newDocumentBuilder().newDocument()); //设置存储图片的管理者--使用匿名内部类实现 该类实现了PicturesManager接口,实现了其中的savePicture方法 converter.setPicturesManager(new PicturesManager() { FileOutputStream out = null; //在下面的processDocument方法内部会调用该方法 用于存储word中的图片文件 @Override public String savePicture(byte[] bytes, PictureType pictureType, String name, float width, float height) { String imgName = String.valueOf(System.currentTimeMillis()); try { //单个图片的保存 out = new FileOutputStream(resWord + "image/" + imgName + ".jpg"); out.write(bytes); } catch (IOException exception) { exception.printStackTrace(); } finally { if (out != null) { try { out.close(); } catch (IOException e) { e.printStackTrace(); } } } //这里要返回给操作者(HtmlDocumentFacade)一个存储的路径 用于生成Html时定位到图片资源 return imgName + ".jpg"; } }); //使用外观模式,将hwpfDocument文档对象设置给HtmlDocumentFacade中的Document属性 converter.processDocument(hwpfDocument); //获取转换器中的document文档 Document htmlDocument = converter.getDocument(); //充当文档对象模型 (DOM) 树形式的转换源树的持有者 -- 源树 DOMSource domSource = new DOMSource(htmlDocument); //转换器 该对象用于将源树转换为结果树 Transformer transformer = TransformerFactory.newInstance().newTransformer(); //设置输出时的以什么方式输出,也可说是结果树的文件类型 可以是html/xml/text或者是一些扩展前三者的扩展类型 transformer.setOutputProperty(OutputKeys.METHOD, "html"); //设置一些必要的属性 设置输出时候的编码为utf-8 transformer.setOutputProperty(OutputKeys.ENCODING, "utf-8"); //转换 将输入的源树转换为结果树并且输出到streamResult中 transformer.transform(domSource, new StreamResult(new File(resWord + HtmlToWordConStants.DEMO_HTML))); } /** * docx转html 输出到资源/word/demo.html * * @param file * @throws IOException */ void docxToHtml(MultipartFile file) throws IOException { OutputStreamWriter outputStreamWriter = null; XWPFDocument document = new XWPFDocument(file.getInputStream()); XHTMLOptions options = XHTMLOptions.create(); // 存放图片的文件夹 options.setExtractor(new FileImageExtractor(new File(resWord + "image/" + System.currentTimeMillis()))); // html中图片的路径 options.URIResolver(new BasicURIResolver(System.currentTimeMillis() + "/")); outputStreamWriter = new OutputStreamWriter(new FileOutputStream(resWord + HtmlToWordConStants.DEMO_HTML), "utf-8"); XHTMLConverter xhtmlConverter = (XHTMLConverter) XHTMLConverter.getInstance(); xhtmlConverter.convert(document, outputStreamWriter, options); outputStreamWriter.close(); } /** * 导出 word 文档 * * @param request * @param response * @return * @throws Exception */ @GetMapping(value = "/exportWord") public String exportWord(HttpServletRequest request, HttpServletResponse response) throws Exception { String content = "我的测试文档!

正文部分
吧啦吧啦啦啦啦阿拉啦啦
\n"; //由于刚刚导入解析存储的是相对路径,所以导出时要加上图片资源的前缀,我这里直接存储在了自定义的静态资源目录中 content = replaceImgSrc(content); InputStream in = null; XWPFDocument doc = null; in = Thread.currentThread().getContextClassLoader().getResourceAsStream(exportWordSrc); OPCPackage srcPackage = OPCPackage.open(in); doc = new XWPFDocument(srcPackage); List<Map<String, Object>> mapList = new ArrayList<>(); Map<String, Object> param = new HashMap<>(16); param.put("content", content); mapList.add(param); String s = ""; XWPFDocumentUtil.wordInsertRitchText(doc, mapList); // 将docx输出 ExcelUtils.exportWordList(doc, "导出文件名" + HtmlToWordConStants.DOCX, request, response); //因为上面已经使用response返回了文件,浏览器认为已经收到响应,不需要再次发送响应对象,否则会报错 return null; } /** * 将html中src的相对路径增加服务器资源前缀 * * @param htmlBody * @return */ public String replaceImgSrc(String htmlBody) { org.jsoup.nodes.Document document = Jsoup.parse(htmlBody); Elements nodes = document.select("img"); int nodeLenth = nodes.size(); for (int i = 0; i < nodeLenth; i++) { Element e = nodes.get(i); String src = e.attr("src"); if (StringUtils.isNotBlank(src)) { e.attr("src", htmlUrlHead + src); } } if (htmlBody.contains(HtmlToWordConStants.HTML_ELEMENT)) { return document.toString(); } else { return document.select("body>*").toString(); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
ElementEnum HTML元素映射到word的枚举
package com.hexuan.htmltoword.enums; /** * html 元素枚举映射类 * * @author hexuan.wang */ public enum ElementEnum { H1("h1", "h1", "一级标题"), H2("h2", "h2", "二级标题"), H3("h3", "h3", "三级标题"), H7("h7", "h7", "小标题"), P("p", "paragraph", "段落"), STRONG("strong", "", "加粗"), I("i", "", "斜体"), U("u", "", "字体下划线"), IMG("img", "imgurl", "base64图片"), TABLE("table", "table", "表格"), BR("br", "br", "换行"); private String code; private String value; private String desc; public String getCode() { return code; } public String getValue() { return value; } public String getDesc() { return desc; } ElementEnum(String code, String value, String desc) { this.code = code; this.value = value; this.desc = desc; } public static String getValueByCode(String code) { for (ElementEnum e : ElementEnum.values()) { if (e.getCode().equalsIgnoreCase(code)) { return e.getValue(); } } return null; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
TitleFontEnum 标题字体样式
package com.hexuan.htmltoword.enums; /** * word 设置标题字体大小 * * @author hexuan.wang */ public enum TitleFontEnum { H1("h1", 24), H2("h2", 22), H3("h3", 12), H7("h7", 12); private String title; private Integer font; public String getTitle() { return title; } public Integer getFont() { return font; } TitleFontEnum(String title, Integer font) { this.title = title; this.font = font; } public static Integer getFontByTitle(String title) { for (TitleFontEnum e : TitleFontEnum.values()) { if (title.equals(e.getTitle())) { return e.getFont(); } } return null; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
WordUtils 导出 word 工具类
package com.hexuan.htmltoword.util.word; import org.apache.poi.xwpf.usermodel.XWPFDocument; import org.springframework.util.Assert; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; import java.io.OutputStream; import java.net.URLEncoder; /** * 导出 word 工具类 * * @author hexuan.wang */ public class WordUtils { /** * 导出word * * @param doc word 模版地址 * @param fileName 文件名 * @param request * @param response */ public static void exportWordList(XWPFDocument doc, String fileName, HttpServletRequest request, HttpServletResponse response) { Assert.notNull(fileName, "导出文件名不能为空"); Assert.isTrue(fileName.endsWith(".docx"), "word导出请使用docx格式"); try { String userAgent = request.getHeader("user-agent").toLowerCase(); if (userAgent.contains("msie") || userAgent.contains("like gecko")) { fileName = URLEncoder.encode(fileName, "UTF-8"); } else { fileName = new String(fileName.getBytes("utf-8"), "ISO-8859-1"); } // 设置强制下载不打开 response.setContentType("application/force-download"); // 设置文件名 response.addHeader("Content-Disposition", "attachment;fileName=" + fileName); OutputStream out = response.getOutputStream(); doc.write(out); out.close(); } catch (Exception e) { e.printStackTrace(); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
XWPFDocumentUtil
package com.hexuan.htmltoword.util.word; import org.apache.poi.xwpf.usermodel.XWPFDocument; import org.apache.poi.xwpf.usermodel.XWPFParagraph; import java.util.List; import java.util.Map; /** * @author hexuan.wang */ public class XWPFDocumentUtil { /** * 往doc的标记位置插入富文本内容 注意:目前支持富文本里面带url的图片,不支持base64编码的图片 * * @param doc 需要插入内容的Word * @param ritchtextMap 标记位置对应的富文本内容 * @param */ public static void wordInsertRitchText(XWPFDocument doc, List<Map<String, Object>> ritchtextMap) { try { int i = 0; long beginTime = System.currentTimeMillis(); // 如果需要替换多份富文本,通过Map来操作,key:要替换的标记,value:要替换的富文本内容 for (Map<String, Object> mapList : ritchtextMap) { for (Map.Entry<String, Object> entry : mapList.entrySet()) { i++; for (XWPFParagraph paragraph : doc.getParagraphs()) { if (entry.getKey().equals(paragraph.getText().trim())) { // 在标记处插入指定富文本内容 HtmlUtils.resolveHtml(entry.getValue().toString(), doc, paragraph); if (i == ritchtextMap.size()) { //当导出最后一个富文本时 删除需要替换的标记 doc.removeBodyElement(doc.getPosOfParagraph(paragraph)); } break; } } } } } catch (Exception e) { e.printStackTrace(); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
项目源码:https://gitee.com/pikachu2333/html-to-word
-
相关阅读:
python基础环境
CSV文件操作
Smale 论文列表: 多标签与标签分布学习方向
100天精通Python(数据分析篇)——第63天:Pandas使用自定义函数案例
PHP交流管理系统wamp运行定制开发mysql数据库html网页算机软件工程
openGauss学习笔记-74 openGauss 数据库管理-创建和管理视图
基于TensorFlow Serving的YOLO模型部署
远程拉取gitlab问题
laravel事件监听和job有哪些区别
MySQL的主从复制与读写分离详解
- 原文地址:https://blog.csdn.net/a2272062968/article/details/126227076