-
如何实现有状态转化操作
有状态转化操作
1 UpdateStateByKey
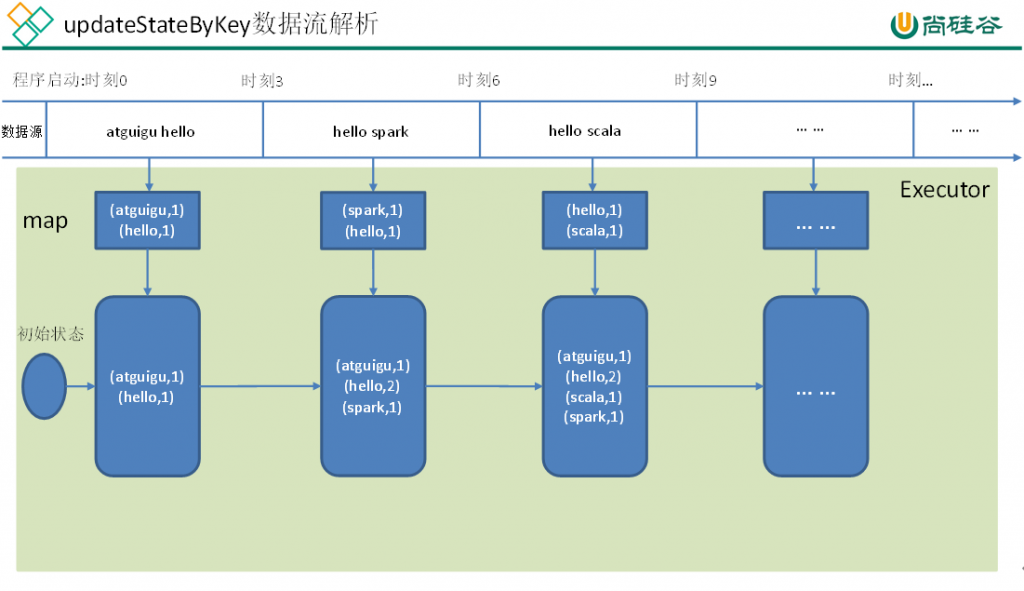
UpdateStateByKey原语用于记录历史记录,有时,我们需要在DStream中跨批次维护状态(例如流计算中累加wordcount)。针对这种情况,updateStateByKey()为我们提供了对一个状态变量的访问,用于键值对形式的DStream。给定一个由(键,事件)对构成的 DStream,并传递一个指定如何根据新的事件更新每个键对应状态的函数,它可以构建出一个新的 DStream,其内部数据为(键,状态) 对。
updateStateByKey() 的结果会是一个新的DStream,其内部的RDD 序列是由每个时间区间对应的(键,状态)对组成的。
updateStateByKey操作使得我们可以在用新信息进行更新时保持任意的状态。为使用这个功能,需要做下面两步:
- 定义状态,状态可以是一个任意的数据类型。
- 定义状态更新函数,用此函数阐明如何使用之前的状态和来自输入流的新值对状态进行更新。
使用updateStateByKey需要对检查点目录进行配置,会使用检查点来保存状态。
更新版的wordcount
(1)编写代码
package com.atguigu.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object WorldCount {
def main(args: Array[String]) {
// 定义更新状态方法,参数values为当前批次单词频度,state为以往批次单词频度
val updateFunc = (values: Seq[Int], state: Option[Int]) => {
val currentCount = values.foldLeft(0)(_ + _)
val previousCount = state.getOrElse(0)
Some(currentCount + previousCount)
}
val conf = new SparkConf().setMaster(“local[*]”).setAppName(“NetworkWordCount”)
val ssc = new StreamingContext(conf, Seconds(3))
ssc.checkpoint(“./ck”)
// Create a DStream that will connect to hostname:port, like hadoop102:9999
val lines = ssc.socketTextStream(“hadoop102”, 9999)
// Split each line into words
val words = lines.flatMap(_.split(” “))
//import org.apache.spark.streaming.StreamingContext._ // not necessary since Spark 1.3
// Count each word in each batch
val pairs = words.map(word => (word, 1))
// 使用updateStateByKey来更新状态,统计从运行开始以来单词总的次数
val stateDstream = pairs.updateStateByKey[Int](updateFunc)
stateDstream.print()
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate
//ssc.stop()
}
}
(2)启动程序并向9999端口发送数据
[atguigu@hadoop102 kafka]$ nc -lk 9999
ni shi shui
ni hao ma
(3)结果展示
——————————————-
Time: 1504685175000 ms
——————————————-
——————————————-
Time: 1504685181000 ms
——————————————-
(shi,1)
(shui,1)
(ni,1)
——————————————-
Time: 1504685187000 ms
——————————————-
(shi,1)
(ma,1)
(hao,1)
(shui,1)
(ni,2)
2 WindowOperations
Window Operations可以设置窗口的大小和滑动窗口的间隔来动态的获取当前Steaming的允许状态。所有基于窗口的操作都需要两个参数,分别为窗口时长以及滑动步长。
(1)窗口时长:计算内容的时间范围;
(2)滑动步长:隔多久触发一次计算。
注意:这两者都必须为批次大小的整数倍。
如下图所示WordCount案例:窗口大小为批次的2倍,滑动步等于批次大小。
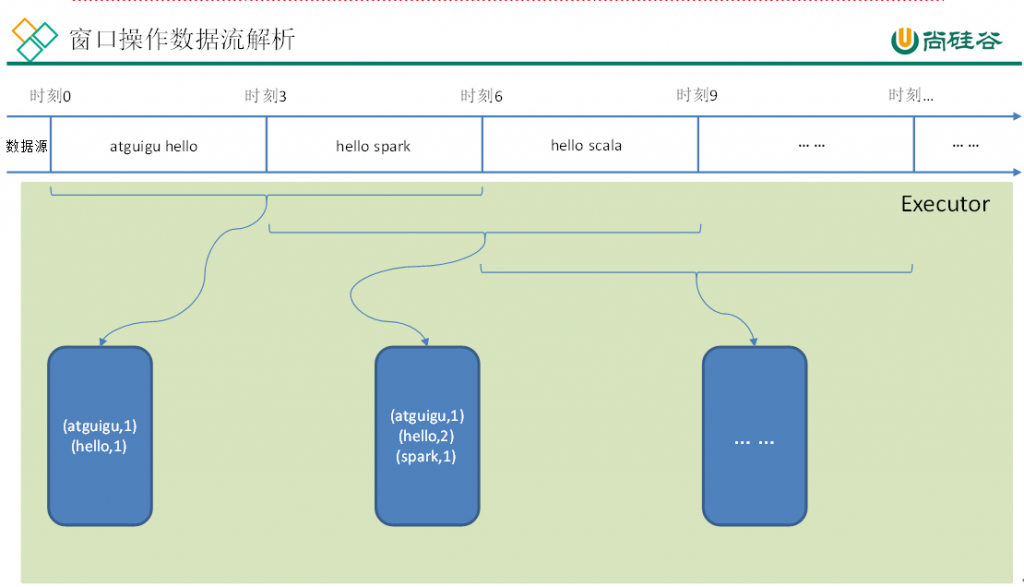
WordCount第三版:3秒一个批次,窗口12秒,滑步6秒。
package com.atguigu.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object WorldCount {
def main(args: Array[String]) {
val conf = new SparkConf().setMaster(“local[2]”).setAppName(“NetworkWordCount”)
val ssc = new StreamingContext(conf, Seconds(3))
ssc.checkpoint(“./ck”)
// Create a DStream that will connect to hostname:port, like localhost:9999
val lines = ssc.socketTextStream(“hadoop102”, 9999)
// Split each line into words
val words = lines.flatMap(_.split(” “))
// Count each word in each batch
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b),Seconds(12), Seconds(6))
// Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.print()
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate
}
}
关于Window的操作还有如下方法:
(1)window(windowLength, slideInterval): 基于对源DStream窗化的批次进行计算返回一个新的Dstream;
(2)countByWindow(windowLength, slideInterval): 返回一个滑动窗口计数流中的元素个数;
(3)reduceByWindow(func, windowLength, slideInterval): 通过使用自定义函数整合滑动区间流元素来创建一个新的单元素流;
(4)reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]): 当在一个(K,V)对的DStream上调用此函数,会返回一个新(K,V)对的DStream,此处通过对滑动窗口中批次数据使用reduce函数来整合每个key的value值。
(5)reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]): 这个函数是上述函数的变化版本,每个窗口的reduce值都是通过用前一个窗的reduce值来递增计算。通过reduce进入到滑动窗口数据并”反向reduce”离开窗口的旧数据来实现这个操作。一个例子是随着窗口滑动对keys的“加”“减”计数。通过前边介绍可以想到,这个函数只适用于”可逆的reduce函数”,也就是这些reduce函数有相应的”反reduce”函数(以参数invFunc形式传入)。如前述函数,reduce任务的数量通过可选参数来配置。

val ipDStream = accessLogsDStream.map(logEntry => (logEntry.getIpAddress(), 1))
val ipCountDStream = ipDStream.reduceByKeyAndWindow(
{(x, y) => x + y},
{(x, y) => x – y},
Seconds(30),
Seconds(10))
//加上新进入窗口的批次中的元素 //移除离开窗口的老批次中的元素 //窗口时长// 滑动步长countByWindow()和countByValueAndWindow()作为对数据进行计数操作的简写。countByWindow()返回一个表示每个窗口中元素个数的DStream,而countByValueAndWindow()返回的DStream则包含窗口中每个值的个数。
val ipDStream = accessLogsDStream.map{entry => entry.getIpAddress()}
val ipAddressRequestCount = ipDStream.countByValueAndWindow(Seconds(30), Seconds(10))
val requestCount = accessLogsDStream.countByWindow(Seconds(30), Seconds(10))
-
相关阅读:
【论文阅读】CVPR 2023 色彩后门:色彩空间中的鲁棒中毒攻击
Linux 软链接 与 硬链接 的区别
入门力扣自学笔记110 C++ (题目编号1374)
Redis分布式锁 - 基于Jedis和LUA的分布式锁
Web3安全性:保护去中心化应用和用户的最佳实践
【力扣周赛】第 357 场周赛(⭐反悔贪心)
阿里35+老测试员生涯回顾,自动化测试真的有这么吃香吗?
基于springboot大学生租房系统springboot10
Windows11 手把手教授开放端口
R语言ggplot2可视化:可视化折线图、使用theme函数中的legend.position参数自定义图例的位置
- 原文地址:https://blog.csdn.net/zjjcchina/article/details/126230916