-
刷完HashMap源码,我们一起进大厂
不可不知的哈希映射
引言 hashmap这个东西呢,太老生常谈了 开发中常用、面试中常问 总之,很重要。。。。。 接下来呢 咱们就一起来看下,里面到底有哪些解不开的东西- 1
- 2
- 3
- 4
- 5
2.1 HashMap数据结构
目标:
HashMap 概念、数据结构回顾(JDK8和JDK7) & 为什么1.8使用红黑树?
概念:
HashMap 是一个利用散列表(哈希表)原理来存储元素的集合,是根据Key value而直接进行访问的数据结构
在 JDK1.7 中,HashMap 是由 数组+链表构成的。
在 JDK1.8 中,HashMap 是由 数组+链表+红黑树构成
回顾: 数组、链表(优势和劣势)
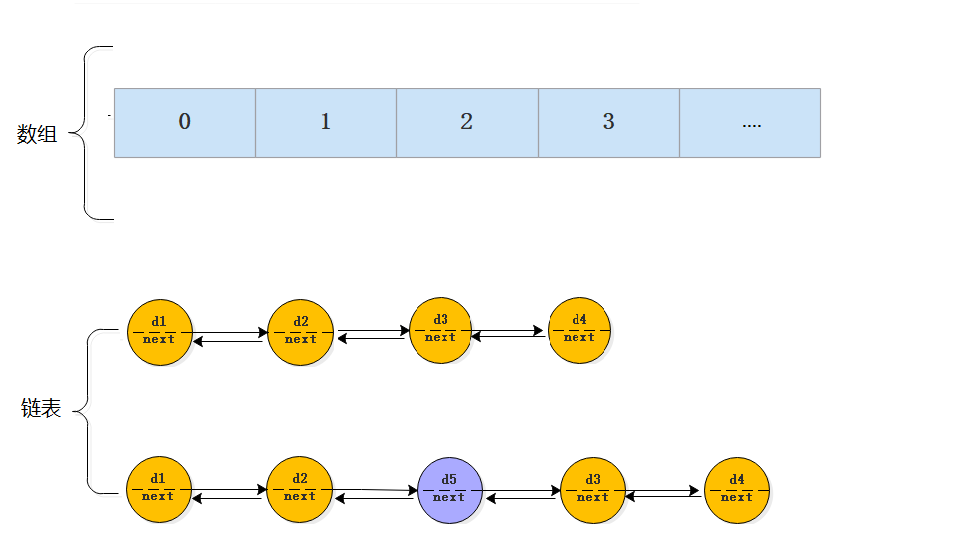
数组: 优势:数组是连续的内存,查询快(o1) 劣势:插入删除O(N) 链表: 优势:不是连续的内存,随便插入(前、中间、尾部) 插入O(1) 劣势:查询慢O(N)
思考?
为什么是JDK1.8 是数组+链表+红黑树???HashMap变化历程
1.7的数据结构:链表变长,效率低 了!!!
1.8的数据结构:
数组+链表+红黑树
链表--树(链长度>8、数组长度大于64)
备注:现在重点讲map,不讲树的操作。树在算法课里有详细学习
总结:
JDK1.8使用红黑树,其实就是为了提高查询效率
因为,1.7的时候使用的数组+链表,如果链表太长,查询的时间复杂度直接上升到了O(N)
2.2 HashMap继承体系
目标:梳理map的继承关系

总结
HashMap已经继承了AbstractMap而AbstractMap类实现了Map接口
那为什么HashMap还要在实现Map接口呢?
据 java 集合框架的创始人Josh Bloch描述,这样的写法是一个失误。
在java集合框架中,类似这样的写法很多,最开始写java集合框架的时候,他认为这样写,在某些地方可能是有价值的,直到他意识到错了。
显然的,JDK的维护者,后来不认为这个小小的失误值得去修改,所以就这样存在下来
- Cloneable 空接口,表示可以克隆
- Serializable 序列化
- AbstractMap 提供Map实现接口
2.3 HashMap源码深度剖析
1)目标:
通过阅读HashMap(since1.2)源码,我们可以知道以下几个问题在源码是如何解决的
(1)HashMap的底层数据结构是什么?
(2)HashMap中增删改查操作的底部实现原理是什么?
(3)HashMap是如何实现扩容的?
(4)HashMap是如何解决hash冲突的?
(5)HashMap为什么是非线程安全的?
2)测试代码如下
package com.mmap; import org.openjdk.jol.info.ClassLayout; import java.util.ArrayList; import java.util.ConcurrentModificationException; import java.util.HashMap; import java.util.List; import java.util.concurrent.ConcurrentHashMap; public class MMapTest { public static void main(String[] args) { HashMap- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
3)关于hashMap基本结构的验证
先来个小验证,几乎地球人都知道map是 数组 + 链表 结构,那我们先来验证一下

再来看debug结果:

验证了基本结构,那为啥1和17就在一块了?到底谁和谁放在一个链上呢?内部到底怎么运作的?往下看 ↓
2.3.1 成员变量与内部类
目标:先了解一下它的基本结构
回顾:位运算(下面还会频繁用到)
1<<4
二进制相当于1右边补4个0:10000
十进制相当于1 x 2的4次方 , 也就是 16
二进制运算是因为它的计算效率高
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; //16,默认数组容量:左位移4位,即16 static final int MAXIMUM_CAPACITY = 1 << 30;//最大容量:即2的30次幂 static final float DEFAULT_LOAD_FACTOR = 0.75f;//负载因子:扩容使用,统计学计算出的最合理的 static final int TREEIFY_THRESHOLD = 8;//链表转红黑树阈值 static final int UNTREEIFY_THRESHOLD = 6;//当链表的值小<6, 红黑树转链表 …… transient Node- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
具体的key,value放在哪里呢?答案是一个静态内部类(1.8前是Entry)
static class Node- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
2.3.2 HashMap构造器
1)目标:学习下面的三个构造器,它们都干了哪些事情?
public HashMap() { this.loadFactor = DEFAULT_LOAD_FACTOR; // 负载因子DEFAULT_LOAD_FACTOR = 0.75f }- 1
- 2
public HashMap(int initialCapacity) { this(initialCapacity, DEFAULT_LOAD_FACTOR); }- 1
- 2
public HashMap(int initialCapacity, float loadFactor) { //赋值,多了一些边界判断 if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); this.loadFactor = loadFactor; this.threshold = tableSizeFor(initialCapacity); // 注意,map里是没有capacity这个类变量的! }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
map的构造函数就做了几个赋值这么点事?这么简单?错!接着往下看
2)无参构造函数验证
第一步:添加以下debug变量
第二步:使用默认构造函数时,在put之前和之后分别debug以上变量信息对比看看
put之前:

之后

毫无违和感,那么,我们接着往下!
3)自定义初始化参数验证
接下来我们胡搞一下,让容量=15,因子=0.5,猜一猜会发生什么?

调试到put之后,再来看:

源码剖析:
在有参数构造时,最终tableSizeFor
//capacity函数,初始化了table,就是table的length,否则取的是threshold final int capacity() { return (table != null) ? table.length : (threshold > 0) ? threshold : DEFAULT_INITIAL_CAPACITY; } //带参数的初始化,其实threshold调用的是以下函数: //这是什么神操作??? //其实是将n转成2进制,右移再和自己取或,相当于把里面所有的0变成了1 //最终目的:找到>=n的,1开头后面全是0的数。如果n=111 , 那就是 1000 ; 如果n=100,那就是它自己 //而这个数,恰好就是2的指数,为后面的扩容做铺垫 static final int tableSizeFor(int cap) { int n = cap - 1; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; //到这一步n已经各个位都是1了。 //范围校验,小于0返回1,大于最大值返回最大值,绝大多数正常情况下,返回n+1,也就是10000…… return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
调试案例:
package com.mmap; public class TableSizeTest { public static void main(String[] args) { System.out.println(tableSizeFor(9)); //9的二进制更能看出以下变化 } static final int tableSizeFor(int cap) { System.out.println(Integer.toBinaryString(cap)); //1001 int n = cap - 1; System.out.println(Integer.toBinaryString(n)); //1000 n |= n >>> 1; //无符号右移,前面补0 System.out.println(Integer.toBinaryString(n)); //右移再或,1100 n |= n >>> 2; System.out.println(Integer.toBinaryString(n)); //再移动2位, 1111 n |= n >>> 4; System.out.println(Integer.toBinaryString(n)); //就这么长,再迁移也是1111 n |= n >>> 8; System.out.println(Integer.toBinaryString(n)); n |= n >>> 16; System.out.println(Integer.toBinaryString(n)); //Integer的最大长度32位,16折半后迁移全覆盖 System.out.println(Integer.toBinaryString(n+1)); return n + 1; //+1后变为 10000 ,也就是16 , 2的4次方 } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
4)总结:
map的构造函数没有你想象的那么简单!
- 无参构造时,容量=16,因子=0.75。第一次插入数据时,才会初始化table、阈值等信息
- 有参构造时,不会容忍你胡来,会取大于但是最接近你容量的2的指数倍(想一下为什么?提示:和扩容规则有关)
- 无论哪种构造方式,扩容阈值最终都是 =(容量*因子)
2.3.3 HashMap插入方法
目标:图解+代码+断点分析put源码
1)先了解下流程图

2)关于key做hash值的计算
当我们调用put方法添加元素时,实际是调用了其内部的putVal方法,第一个参数需要对key求hash值
public V put(K key, V value) { return putVal(hash(key), key, value, false, true);//调用Map的putVal方法 }- 1
- 2
小提问:map里所谓的hash是直接用的key的hashCode方法吗?
static final int hash(Object key) { int h; //【知识点】hash扰动 return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }- 1
- 2
- 3
- 4
- 5
图解:

结论:使用移位和异或做二次扰动,不是直接用的hashCode!
3)核心逻辑
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {//onlyIfAbsent:true不更改现有值;evict:false表示table为创建状态 //几个临时变量: //tab=数组,p=插槽指针,n=tab的长度,i数组下标 Node- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
4)重点(寻址计算):
接上文,关于hash值取得后,放入tab的哪个插槽,也就是所谓的寻址我们重点来讲
(n - 1) & hash我们还是以开始的例子,1和17为例,他们的hash计算后正好是1和17本身,我们可以验证一下
Integer i = new Integer(1); Integer j = new Integer(17); System.out.println(i.hashCode() ^ i.hashCode()>>16); //1 System.out.println(j.hashCode() ^ j.hashCode()>>16); //17- 1
- 2
- 3
开始位运算
默认n=16,n-1也就是15,二进制是 1111 那么 15 & 1 1 1 1 1 0 0 0 1 与运算后 = 1 再来看15 & 17,17是 10001 1 1 1 1 1 0 0 0 1 与运算后 = 1 所以,1和17肯定会落在table的1号插槽上!两者会成为链表,解释了我们前面的案例 原理:不管你算出的hash是多少,超出tab长度的高位被抹掉,低位是多少就是你所在的槽的位置,也就是table的下标- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
思考:为什么不用mod(模运算)进行寻址?mod也能保证不会超出数组边界,岂不是更简单直观?
package com.mmap; public class CMod { public static void main(String[] args) { bit(); mod(); } public static void bit() { int a ; long start = System.currentTimeMillis(); //同样的计算次数,先位运算,后取余 for (int i = 1; i < Integer.MAX_VALUE; i++) { a = 1 & i; } long end = System.currentTimeMillis(); System.out.println("BIT耗时>>" + (end - start)); } public static void mod() { int a ; long start = System.currentTimeMillis(); for (int i = 1; i < Integer.MAX_VALUE; i++) { a = 1 % i; } long end = System.currentTimeMillis(); System.out.println("MOD耗时>>" + (end - start)); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
跑一下试试?
结论:
一切为了性能
2.3.4 HashMap扩容方法
目标:图解+代码(map扩容与数据迁移)
注意:扩容复杂、绕、难
备注:线程不安全的
图解: 假设我们 new HashMap(8)
迁移前:长度8 扩容临界点6(8*0.75)

迁移过程


核心源码resize方法
//注意!该方法兼容了初始化和扩容,所以比较难理清楚! //需要对照上面的图例来同步讲解。 final Node- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
总结(扩容与迁移):
1、扩容就是将旧表的数据迁移到新表
2、迁移过去的值需要重新计算下标,也就是他的存储位置
3、关于位置可以这样理解:比如旧表的长度8、新表长度16
旧表位置4有6个数据,假如前三个hashCode是一样的,后面的三个hashCode是一样的
迁移的时候;就需要计算这6个值的存储位置
4、如何计算位置?采用低位链表和高位链表;如果位置4下面的数据e.hash & oldCap等于0,
那么它对应的就是低位链表,也就是数据位置不变
5、 e.hash & oldCap不等于0呢?就要重写计算他的位置也就是j + oldCap,(4+8)= 12,就是高位链表位置(新数组12位置)
2.3.5 HashMap获取方法
目标:图解 (这个简单!)
获取流程

get主方法
public V get(Object key) { Node- 1
- 2
- 3
getNode方法
final Node- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
总结:
查询思路比较简单,如果是数组直接返回、如果是红黑实例,就去树上去找,最后,去做链表循环查找
2.3.6 HashMap移除方法
目标:图解+断点分析remove源码
移除流程

tips:
两个移除方法,参数上的区别
走的同一个代码
移除方法:一个参数
public V remove(Object key) { Node- 1
- 2
- 3
- 4
移除方法:二个参数
@Override public boolean remove(Object key, Object value) { return removeNode(hash(key), key, value, true, true) != null; }- 1
- 2
- 3
核心方法removeNode
/** * Implements Map.remove and related methods * * @param hash 扰动后的hash值 * @param key 要删除的键值对的key,要删除的键值对的value,该值是否作为删除的条件取决于matchValue是否为true * @param value key对应的值 * @param matchValue 为true,则当key对应的值和equals(value)为true时才删除;否则不关心value的值 * @param movable 删除后是否移动节点,如果为false,则不移动 * @return 返回被删除的节点对象,如果没有删除任何节点则返回null */ final Node- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
总结:
移除和查询路线差不多,找到后直接remove
注意他的返回值,是删除的那个节点的值
拓展:
为什么说HashMap是线程不安全的
我们从前面的源码分析也能看出,它的元素增删改的时候,没有任何加锁或者cas操作。
而这里面各种++和--之类的操作,显然多线程下并不安全
那谁安全呢?下节课我们分析
专注Java技术干货分享,欢迎志同道合的小伙伴,一起交流学习
-
相关阅读:
T40开发过程记录
学生HTML个人网页作业作品 使用HTML+CSS+JavaScript个人介绍博客网站 web前端课程设计 web前端课程设计代码 web课程设计
Java Math
Java--Spring和MyBatis集成
算法 主持人调度-(双指针+贪心)
考研C语言复习进阶(6)
js中遍历数组的方法总结,以及数组中常用方法总结
TMS570快速上手指南(1)--环境准备和LED闪烁
数据挖掘与统计分析——T检验,正态性检验和一致性检验——代码复现
k8s 编写nginx资源文件
- 原文地址:https://blog.csdn.net/bxg_kyjgs/article/details/126226089

