-
Shell正则表达式
目录
文本处理工具
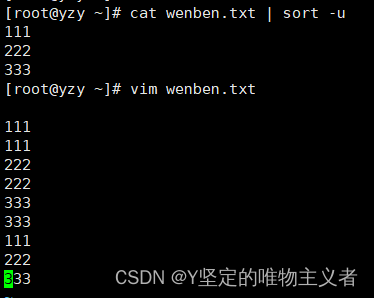
1、sort排序
sort是一个一行为单位对文件进行排序的工具,也可以根据不同的数据类型来排序。比较原则是从首字符向后,依次按ASCII码值进行比较,最后将它们按升序输出
语法格式:
- sort [选项] 参数
- cat file | sort 选项
常用选项 介绍 -f 忽略大小写,会将小写字母都转换为大写字母来进行比较 -b 忽略每行前面的空格 -n 按照数字进行排序 -r 反向排序 -u 等同于uniq,表示相同的数据仅显示一行 -t 指定字段分隔符,默认使用[Tab]键分隔 -k 指定排序字段 -o <输出文件>:将排序后的结果转存至指定文件 - 示例:
- sort -n testfile1#按照数字进行排序
- sort -t ':' -k 3 -n /etc/passwd#将/etc/passwd中的指定字段以:为分隔符,按照数字进行排序
- du -a | sort -nr -o du.txt#将当前家目录中的所有文件进行排序,查出占用空间最大的文件并保存
2、uniq去重
uniq主要是用于去除连续的重复行
注意,是连续的行,所以通常和sort命令结合使用先排序使之变成连续的行再执行去重操作,否则不连续的重复行他不能去重。语法格式:
- uniq [选项] 参数
- cat file | uniq 选项
常用选项 介绍 -c 进行计数统计,并删除文件中重复出现的行(去重) -d 仅显示连续的重复行 -u 仅显示出一次的行 - 示例:
- uniq testile2#用于报告或者忽略文件中连续的重复行
- sort -n testfile2 | uniq -c#对文件的内容进行排序并且进行统计
- grep "Failed password"/var/log/secure | awk '{print $11}' | sort | uniq -c | sort -nr
- #显示登录试错的次数最多的主机IP
- cat testfile2 | sort -n | uniq -u#显示此文件中没有重复行的内容

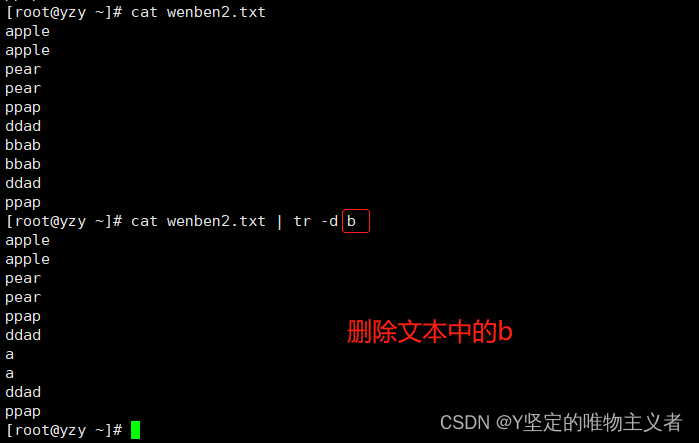
3、tr修改
tr可以用一个字符来替换两一个字符,或者可以完全出去一些字符,也可以用它来出去重复字符
语法格式:
tr [选项] [参数]常用选项 介绍 -c 保留字符集1的字符,其他的字符(包括换行符\n)用字符集2替换 -d 删除所有属于字符集1的字符 -s 将重复出现的字符串压缩为一个字符串;用字符集2 替换 字符集1 -t 字符集2 替换 字符集1,不加选项同结果 
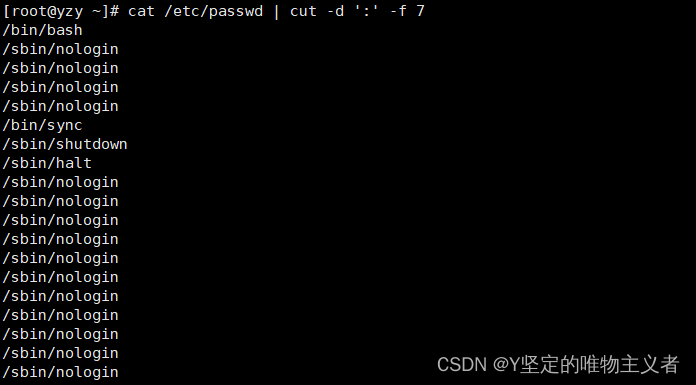
4、cut列举
cut是常见的截取工具
cut命令从文件的每一行剪切字节、字符和字段,并将这些字节、字符和字段写至标准输出,如不制定File的参数,cut命令将会读取标准输入,所以必须要指定-b、-c或-f作为其标志语法格式:
- cut 参数
- cat file | cut 选项
常用选项 介绍 -f 通过指定哪一个字符进行提取,cut命令使用"TAB"作为默认的字段分隔符 -d "TAB"是默认的分隔符,使用此选项可以更改为其他的分隔符 -b 以字节为单位进行分割 –complement 此选项用于排除所指定的字段 –output-delimiter 更改输出内容的分隔符 - 示例:
- cut -d ':' -f 1 /etc/passwd
- grep '/bin/bash' /etc/passwd | cut -d ':' -f 1-4,6,7
- #截取/ect/passwd中以带有/bin/bash字段的行以-分隔的开始字段和结束字段指定字段的范围
- grep '/bin/bash' /etc/passwd | cut -d ':' --complement -f 2#排除第二个字段
- cut -d ':' -f1,7 --output-delimiter=' ' /etc/ passwd#输出分隔符使用空格分隔

正则表达式
-
通常用于判断语句中,用来检查某一个字符串是否满足某一格式
-
正则表达式是由普通字符与元字符组成;普通字符包括大小写字母、数字、标点符号及一些其他符号
-
元字符是指在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符或表达式)在目标对象中的出现模式
基础正则表达式常见的元字符
(支持的工具:grep、egrep、sed、awk)
常用转义符 介绍 示例 \ 转义字符,用于取消特殊符号的含义 \ !、\n、$等 ^ 匹配字符串开始的位置 ^ a、^ the、^ #、^ [a-z] $ 匹配字符串结束的位置 word$、匹配空行 . 匹配除\n之外的任意的一个字符 go.d、g…d * 匹配前面子表达式0次或者多次, goo*d、go.*d、^go.*d$ 总结
可以通过正则表达式来对普通字符和元字符来进行表示,需要知道基础正则表达式和扩展正则表达式的使用
-
相关阅读:
粽子产线的速度提升
LLVM IR 文档 专门解释 LLVM IR
eBPF理解 (四)
linux 系统的磁盘 mbr 转gpt方法
机器学习9—关联分析之Apriori算法和FP-Growth算法
82.(cesium篇)cesium点在3d模型上运动
ESP8266-Arduino编程实例-红外接收
【GPT4账号】ChatGPT/GPT4科研技术应用与AI绘图及论文高效写作
element的表格样式修改
HTML
- 原文地址:https://blog.csdn.net/weixin_71429839/article/details/126216671