-
新零售项目及离线数仓核心面试,,220807,,
新零售 = 线上下单 + 线下配送售后
叮咚买菜、盒马鲜生、鲜丰、百果园、朴朴、每日优鲜
业务流程类比与,外卖平台,,

两个项目选spark

即席查询???

画技术架构图,, ???
可以加上软件版本嘛
取决于简历项目时间,,至少前一年,,


cdh6,18,19年出来的,

事实指标值的分类
可累加、半可累加、不可累加
UV半可累加,时间维度不可累加,地区维度可累加
uv重复(1个用户三十天都访问,只统计1个)
比率类不可累加
如果不可累加:对所有数据重新计算(上卷基于上一层)

400行的代码,,宽表字段多关联表多,多种8种组合维度,
ETL工程师 岗位:大数据 ETL工程师 看岗位需求hadoop

不找建模相关工作,,只能经验积累,,至少2个项目积累后,,
岗位侧重点擅长不同,建模,业务,开发,spark,flink,
md高亮需要背诵,,,


拉链表,历史状态,不太冗余,,
开链,闭链,断链,
-
开链:数据进入拉链表,当前是数据的最新状态,endTime=9999-12-31
-
闭链:数据在拉链表变成了历史状态,endTime = 有了具体的值
-
断链:漏了某一天的数据没有拉链
-
退链:将拉链表回退到某一天的状态

1-一般在表中规范来讲,不允许存在null中
值
数值:0
字符串:-1 、''

Join/分组:这一列不会包含null
hive优化,spark优化,
属性优化,
sql开发优化,
结构设计优化



字典:100个字,99个字:s开头发音
字典目录:拼音检索:索引
查这个字典中所有以s开头发音汉字
1-查,2-不查
总共就一百字,
索引:数据量大,数据种类多
RBO:基于规则







客户端发送向两个NameNode
jn共享edist

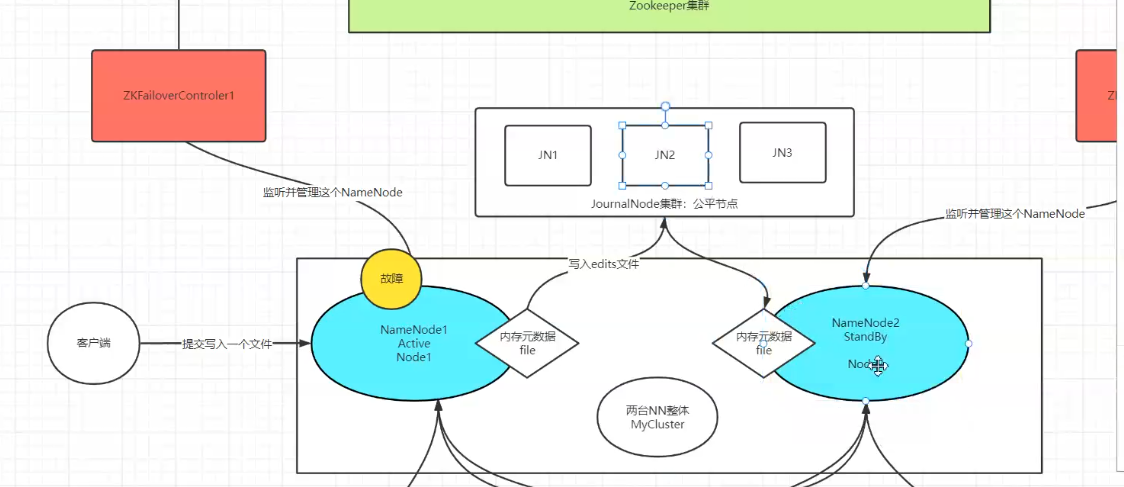
集群多主
zkfc坏了啊

zkfc坏了,只会发死临时节点,,


hdfs安全,副本机制,,




Input、Map、Output
sqoop

一行一个kv对,,


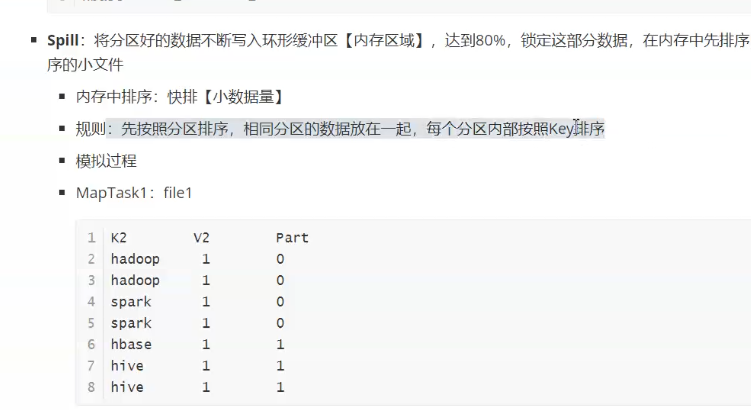
分区,spill分区内排序(快排,内存中),,



map端shuffle,
为什么是相同分区放在一起?
方便reduce拉取速度(索引文件,避免一条条判断)


reduce端shuffle(分区拉取,合并,排序,分组)
reduce方法:V2中每个值进行sum


TextInputFormat执行过程中:读取数据、实现切片、转换KV
reduce端shuffle(分区拉取,合并排序,分组)
分组本质比较:相同就是一组
加快分组效率,不匹配就不后续比较,,

归并排序:基于数据索引的排序,参与的排序的部分是有序的两个部分,归并可以更快





按顺序分配资源,,,



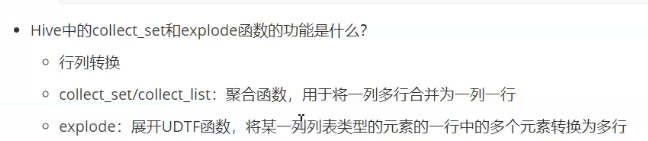



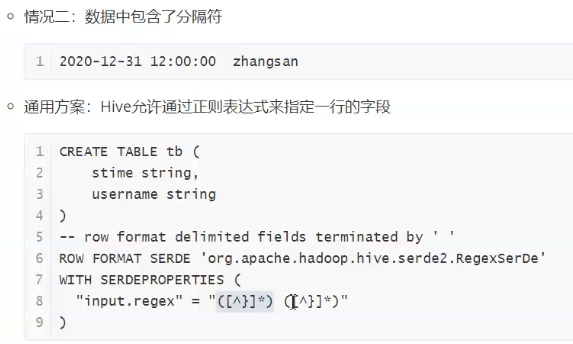
逻辑字段,表里没有,




内部表,外部表,,

星型模型/星座模型 ???
-
维度表设计模型
-
雪花模型【冗余度低,查询性能低】:维度表拥有子维度表,部分维度表关联在维度表中,间接的关联事实表
-
星型模型/星座模型【冗余度高,查询性能高】:维度表没有子维度,直接关联在事实表
上,星座模型中有多个事实
-
mr流程,input分片,map,map端shuffle(分区,spill溢写,merge),reduce端shuffle(拉取,merge),reduce聚合,output,
preview

自己梳理一个笔记:面经
列举所有可能问的问题以及答案
重点问题细化,最好能举出项目中例子,,
md高亮需要背诵,,,



hdfs数据安全??
3副本机制,,
-
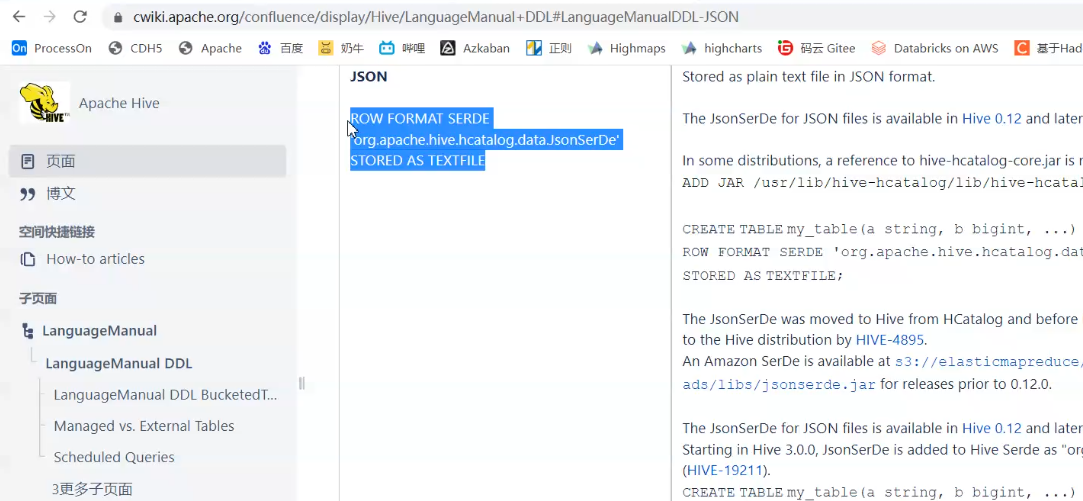
常见的存储格式有哪些,各自有什么优点?
-
Parquet、Orc、Avro
-

不同点
行式存储or列式存储:Parquet和ORC都以列的形式存储数据,而Avro以基于行的格式存储数据。 就其本质而言,面向列的数据存储针对读取繁重的分析工作负载进行了优化,而基于行的数据库最适合于大量写入的事务性工作负载。
压缩率:基于列的存储区Parquet和ORC提供的压缩率高于基于行的Avro格式。
可兼容的平台:ORC常用于Hive、Presto;Parquet常用于Impala、Drill、Spark、Arrow;Avro常用于Kafka、Druid。
不同的案例和应用场景选择合适的存储格式,可以提升存储和读取的效率。即席查询 ????
什么是即席查询?
即席查询(Ad Hoc Queries),是用户根据自己的需求,灵活的选择查询条件,系统能根据用户的选择生成对应的统计报表。即席查询与普通应用查询的最大不同在于即席查询的 SQL 是灵活的、不确定的、短暂的。
如何实现即席查询?
即席查询所面临的痛点就是响应时间,如何能让一个查询 SQL 在秒级,亚秒级响应?目前在提高响应时间上的优化成熟的方案有两个:基于内存(Presto)和预计算(Kylin)
-
Hive的表类型有几种,有什么区别?
-
总体上Hive有四种表:外部表,内部表(管理表),分区表,桶表。
-
-
如何在Linux命令行执行Hive的SQL语句?
1.“-e”不进入hive的交互窗口执行sql语句
2.“-f”执行脚本中sql语句
-
面试题:项目中什么地方遇到了数据倾斜?
-
结合项目中的实际场景去设计一个答案
打开4040,1.通过时间判断,发现 r_000000 这个 task 执行 20 多分钟了还没完成,对比其他 reduce 时间长的多,其他大部分 task 在 1 分钟之内完成
2.通过任务 Counter 判断
Counter 会记录整个 job 以及每个 task 的统计信息。counter 的 url 一般类似:
http://bd001:8088/proxy/application_1624419433039_1569885/mapreduce/singletaskcounter/task_1624419433039_1569885_r_000000/org.apache.hadoop.mapreduce.FileSystemCounter
通过输入记录数,普通的 task counter 如下,输入的记录数是 13 亿多:而 task=000000 的 counter 如下,其输入记录数是 230 多亿。是其他任务的 100 多倍:
4找到执行特别慢的那个 task,然后 Ctrl+F 搜索 “CommonJoinOperator: JOIN struct” 。Hive 在 join 的时候,会把 join 的 key 打印到日志中。
-
-
相关阅读:
事务的原理、MVCC的原理
我的DW个人网站设计——安徽宣城6页HTML+CSS+JavaScript
视频电影和字幕如何合并?
Python语言核心编程
Text-to-Image最新论文、代码汇总
支持中文!秒建 wiki 知识库的开源项目,构建私人知识网络
【C++】深拷贝和浅拷贝 ② ( 默认拷贝构造函数是浅拷贝 | 代码示例 - 浅拷贝造成的问题 )
LVS-nat模式部署
华为OD 最大岛屿体积(100分)【java】A卷+B卷
MySQL的MHA
- 原文地址:https://blog.csdn.net/m0_48941160/article/details/126206623