-
leetcode 30. 串联所有单词的子串
作者简介:C/C++ 、Golang 领域耕耘者,创作者
个人主页:作者主页
活动地址:CSDN21天学习挑战赛
题目来源: leetcode官网
如果感觉博主的文章还不错的话,还请关注➕ 、点赞👍 、收藏🧡三连支持一下博主哦~~~💜 题目描述
给定一个字符串 s 和一些 长度相同 的单词 words 。找出 s 中恰好可以由 words 中所有单词串联形成的子串的起始位置。
注意子串要与 words 中的单词完全匹配,中间不能有其他字符 ,但不需要考虑 words 中单词串联的顺序。
示例1:
输入:s = “barfoothefoobarman”, words = [“foo”,“bar”]
输出:[0,9]
解释:
从索引 0 和 9 开始的子串分别是 “barfoo” 和 “foobar” 。
输出的顺序不重要, [9,0] 也是有效答案。示例2:
输入:s = “wordgoodgoodgoodbestword”, words = [“word”,“good”,“best”,“word”]
输出:[]示例 3:
输入:s = “barfoofoobarthefoobarman”, words = [“bar”,“foo”,“the”]
输出:[6,9,12]🧡 算法分析
此题有一定难度
前提是需要将字符串s 拆分成几个小段,每一段长度为w, 其中
w = words[0].size()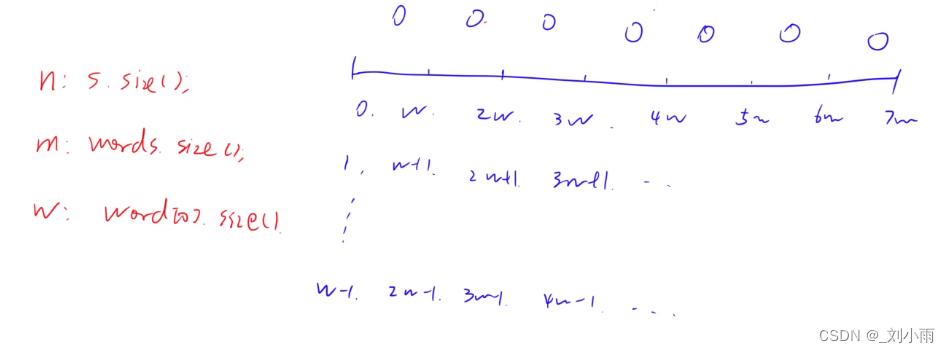
1、先用map哈希表将word中的单词存起来,每个单词有多少个
2、find哈希表表示当从i开始长度是n * len的滑动窗口中将该窗口的字符串以长度是len进行分割出来记录元素的哈希表,记录该窗口每个单词有多少个
3、当枚举到某个窗口时,枚举该窗口的某个单词
- 如果map哈希表中存在该单词,则在find哈希表中记录该单词的数量,并且始终保持find.get(t) <= map.get(t)的状态
- 如果map哈希表中不存在该单词,则一定不符合条件
4、最后,如果该窗口的所有单词都枚举完,没有发现错误,则表示从i开始的窗口符合条件
💚 代码实现
class Solution { public: vector<int> findSubstring(string s, vector<string>& words) { vector<int> re; if(words.empty()) return re; // w 是作步长的 int n = s.size(), m = words.size(), w = words[0].size(); // 哈希表存储words 元素 unordered_map<string, int> tot; for(auto& word : words) tot[word] ++; // 开始按照每个步长循环 for(int i = 0; i < w; i ++) { unordered_map<string, int> wd; int cnt = 0; for(int j = i; j + w <= n; j += w) { if(j >= i + m * w) { auto word = s.substr(j - m * w, w); // 找到前面一个w长度字符串 wd[word] --; // 删除 if(wd[word] < tot[word]) cnt --; // 说明前面的字符串是有效的,移动到后面了,这里就要-- } auto word = s.substr(j, w); wd[word] ++; if(wd[word] <= tot[word]) cnt ++; if(cnt == m) re.push_back(j - (m - 1) * w); } } return re; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
执行结果:

💙 时间复杂度分析
其中遍历一次, 时间复杂度为O(nw)
如果觉得对你有帮助的话:
👍 点赞,你的认可是我创作的动力!
🧡 收藏,你的青睐是我努力的方向!
✏️ 评论,你的意见是我进步的财富! -
相关阅读:
seata相关图形,dljd,cat
【回溯算法】leetcode 51. N 皇后
R语言使用mean函数计算样本(观测)数据中指定变量的相对频数:计算dataframe中指定数据列偏离平均值超过两个标准差的观测样本所占总体的比例
.net6 WebApi使用工厂模式+IOC
计算机网络_2.1 物理层概述
从北京“润”到芝加哥,工程师宝玉“滋润”成长的秘诀
vue二进制转Base64图片展示
Windows 10安装Docker以及配置镜像加速
Windows 11 已修复 AMD CPU 性能问题
t-SNE可视化-Python实现
- 原文地址:https://blog.csdn.net/qq_39486027/article/details/126218449
