-
分布式一致性协议 之 NWR协议与Gossip 协议
NWR协议
1、什么是NWR协议
NWR是一种在分布式存储系统中用于控制一致性级别的一种策略。在亚马逊的云存储系统中,就应用NWR来控制一致性。
- N:在分布式存储系统中,有多少份备份数据
- W:代表一次成功的更新操作要求至少有w份数据写入成功
- R: 代表一次成功的读数据操作要求至少有R份数据成功读取
2、原理
NWR值的不同组合会产生不同的一致性效果,当W+R>N的时候,整个系统对于客户端来讲能保证强一致性。
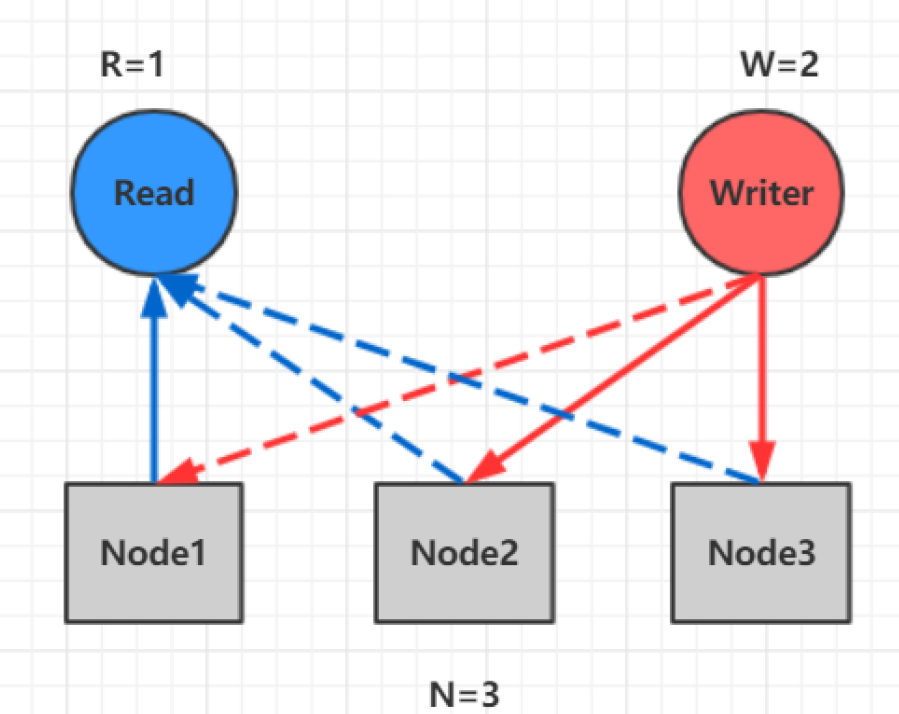
以常见的N=3、W=2、R=2为例:
- N=3,表示,任何一个对象都必须有三个副本
- W=2表示,对数据的修改操作只需要在3个副本中的2个上面完成就返回
- R=2表示,从三个对象中要读取到2个数据对象,才能返回
在分布式系统中,数据的单点是不允许存在的。即线上正常存在的备份数量N设置1的情况是非常危险的,因为一旦这个备份发生错误,就 可能发生数据的永久性错误。假如我们把N设置成为2,那么,只要有一个存储节点发生损坏,就会有单点的存在。所以N必须大于2。N越高,系统的维护和整体 成本就越高。工业界通常把N设置为3。
1. 当W是2、R是2的时候,W+R>N,这种情况对于客户端就是强一致性的。

在上图中,如果R+W>N,则读取操作和写入操作成功的数据一定会有交集(如图中的Node2),这样就可以保证一定能够读取到最新版本的更新数据,数据的强一致性得到了保证。在满足数据一致性协议的前提下,R或者W设置的越大,则系统延迟越大,因为这取决于最慢的那份备份数据的响应时间。
2. 当R+W<=N,无法保证数据的强一致性
因为成功写和成功读集合可能不存在交集,这样读操作无法读取到最新的更新数值,也就无法保证数据的强一致性。
Gossip 协议
1、什么是Gossip 协议
Gossip 协议也叫 Epidemic 协议 (流行病协议)。原本用于分布式数据库中节点同步数据使用,后被广泛用于数据库复制、信息扩散、集群成员身份确认、故障探测等。
从 gossip 单词就可以看到,其中文意思是八卦、流言等意思,我们可以想象下绯闻的传播(或者流行病的传播);gossip 协议的工作原理就类似于这个。gossip 协议利用一种随机的方式将信息传播到整个网络中,并在一定时间内使得系统内的所有节点数据一致。Gossip 其实是一种去中心化思路的分布式协议,解决状态在集群中的传播和状态一致性的保证两个问题。
2、Gossip原理
Gossip 协议的消息传播方式有两种:反熵传播 和 谣言传播
反熵传播
是以固定的概率传播所有的数据。所有参与节点只有两种状态:Suspective(病原)、Infective(感染)。过程是种子节点会把所有的数据都跟其他节点共享,以便消除节点之间数据的任何不一致,它可以保证最终、完全的一致。缺点是消息数量非常庞大,且无限制;通常只用于新加入节点的数据初始化。
谣言传播
是以固定的概率仅传播新到达的数据。所有参与节点有三种状态:Suspective(病原)、Infective(感染)、Removed(愈除)。过程是消息只包含最新 update,谣言消息在某个时间点之后会被标记为 removed,并且不再被传播。缺点是系统有一定的概率会不一致,通常用于节点间数据增量同步。
3、通信方式
Gossip 协议最终目的是将数据分发到网络中的每一个节点。根据不同的具体应用场景,网络中两个节点之间存在三种通信方式:推送模式、拉取模式、推/拉模式
Push
节点 A 将数据 (key,value,version) 及对应的版本号推送给 B 节点,B 节点更新 A 中比自己新的数据

Pull
A 仅将数据 key, version 推送给 B,B 将本地比 A 新的数据(Key, value, version)推送给 A,A 更新本地

Push/Pull
与 Pull 类似,只是多了一步,A 再将本地比 B 新的数据推送给 B,B 则更新本地
4、优缺点
综上所述,我们可以得出 Gossip 是一种去中心化的分布式协议,数据通过节点像病毒一样逐个传播。因为是指数级传播,整体传播速度非常快。
优点:
- 扩展性:允许节点的任意增加和减少,新增节点的状态 最终会与其他节点一致
- 容错:任意节点的宕机和重启都不会影响 Gossip 消息的传播,具有天然的分布式系统容错特性
- 去中心化:无需中心节点,所有节点都是对等的,任意节点无需知道整个网络状况,只要网络连通,任意节点可把消息散播到全网
- 最终一致性:Gossip 协议实现信息指数级的快速传播,因此在有新信息需要传播时,消息可以快速地发送到全局节点,在有限的时间内能够做到所有节点都拥有最新的数据。
缺点
- 消息延迟:节点随机向少数几个节点发送消息,消息最终是通过多个轮次的散播而到达全网;不可避免的造成消息延迟。
- 消息冗余:节点定期随机选择周围节点发送消息,而收到消息的节点也会重复该步骤;不可避免的引起同一节点消息多次接收,增加消息处理压力
Gossip 协议由于以上的优缺点,所以适合于 AP 场景的数据一致性处理,常见应用有:P2P 网络通信、Redis Cluster、Consul。
-
相关阅读:
3D技术在数字藏品中的应用
APP中有html5页面的时候,怎么进行元素定位
表单和servlet在idea中实现文件的上传
GBase 8c约束设计建议
Servlet入门
【PAT甲级】1058 A+B in Hogwarts
【Java】JVM内存回收
浅谈 RxJS: lodash for async、流式任务模型、函数式与响应式的结合
c语言编程函数
论文解读(CTDA)《Contrastive transformer based domain adaptation for multi-source cross-domain sentiment classification》
- 原文地址:https://blog.csdn.net/weixin_52851967/article/details/126209233

