-
Pandas数据分析16——pandas生成虚拟变量,因子化,列表爆炸等操作
参考书目:《深入浅出Pandas:利用Python进行数据处理与分析》
pandas对数据框的分类变量有很多独特的操作,可以方便我们生成虚拟变量,或者是将文本型分类数据转化为数值型分类数据等等。
对分类型数据分成很多列,并且自己取值列为1,其他取值为0 ,这个做法在计量经济学里面叫虚拟变量,计算机科学里面叫独立热编码,机器学习里面叫生成哑变量,其实都是一回事。
导入包
- import numpy as np
- import pandas as pd
虚拟变量 pd.get_dummies()
#语法结构如下:
pd.get_dummies(data, prefix=None,prefix_sep='_', dummy_na=False,
columns=None, sparse=False,drop_first=False, dtype=None)
其中:
prefix:新列的前缀
prefix_sep:新列前缀的连接符
drop_first:是否删除第一列
dummy_na:缺失值是否分一个类首先生成案例数据
- df = pd.DataFrame({'key': list('bbacab'), 'data1': range(6)})
- df

对key这一列生成虚拟变量
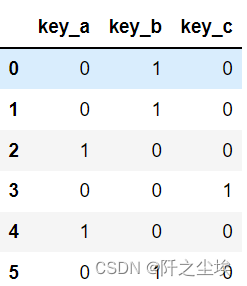
pd.get_dummies(df['key'])
- #用 prefix 给新表列名增加前缀:
- pd.get_dummies(df['key'], prefix='key')
- #可以直接传入 DataFrame 使用:
- df = pd.DataFrame({'A': ['a', 'b', 'a'],
- 'B': ['c', 'c', 'b'],
- 'C': [1, 2, 3]})
- df

- # 最后一列数值数据不会被处理
- pd.get_dummies(df)

- #指定列:并且删除初始列
- pd.get_dummies(df, columns=['A'],drop_first=True)

为什么删除初始列,因为n个分类变量有n列的话,会出现完全的多重共线性,此时称为虚拟变量陷阱。在做最小二乘这种害怕多重共线性的方法时就只能取n-1列变量。其他像随机森林,梯度提升等等不害怕多重共线性的方法就无所谓,
因子化
#因子化值是指将个一维的数据,由于在大量的重复值,可以解析成枚举值,这样我们就方便进行分辨。
#factorize 既可以用作顶层函数 pandas.factorize(),也可以用作Series.factorize() 和 Index.factorize() 方法。
#基本方法,将一个方法进行因子化后将返回两个值,一个是因子化后的编码列表,一个是原数据的去重值列表:- codes, uniques = pd.factorize(['b', 'b', 'a', 'c', 'b'])
- print(codes)
- print(uniques)

#排序, 使用 sort=True 参数后将对唯一性进行排序,编码列表将继续与原值保持对应关系,但从值的大小上将体现出顺序。
- codes, uniques = pd.factorize(['b', 'b', 'a', 'c', 'b'], sort=True)
- print(codes) # array([1, 1, 0, 2, 1])
- print(uniques) # array(['a', 'b', 'c'], dtype=object)

#缺失值, 缺失值不会出现在唯一值列表中,在编码中将为 -1:
- codes, uniques = pd.factorize(['b', None, 'a', 'c', 'b'])
- print(codes) # array([ 0, -1, 1, 2, 0])
- print(uniques) # array(['b', 'a', 'c'], dtype=object)

利用这种方法可以快速的将我们的字符型分类变量转化为数值型变量。
爆炸列表
#爆炸这个词非常形象,是指将类似列表的每个元素转换为一行,索引值是相同的。这个操作也叫 unnest (explode)
生成案例数据
- s = pd.Series([[1, 2, 3], 'foo', [], [3, 4]])
- s

s.explode()
生成案例df
- df = pd.DataFrame({'A': [[1, 2, 3], 'foo', [], [3, 4]], 'B': [1,2]*2})
- df
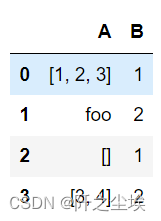
df.explode('A') #B列的值是对应的 B列的值是对应的
B列的值是对应的- #Pandas 1.3.0 开始支持多列的炸开:
- df = pd.DataFrame({'A': [[0, 1, 2], 'foo', [], [3, 4]],
- 'B': 1,
- 'C': [['a', 'b', 'c'], np.nan, [], ['d', 'e']]})
- df

炸开A、C两列
- # A、C 两列执行
- df.explode(list('AC'))
- '''
- A B C
- 0 0 1 a
- 0 1 1 b
- 0 2 1 c
- 1 foo 1 NaN
- 2 NaN 1 NaN
- 3 3 1 d
- 3 4 1 e
- '''
#炸开非列表,有时候遇到不是列表的,但是具有列表的特质,我们也可以处理:
- df = pd.DataFrame([{'var1': 'a,b,c', 'var2': 1},
- {'var1': 'd,e,f', 'var2': 2}])
- df
 var1不是列表,但是我们可以分割成列表
var1不是列表,但是我们可以分割成列表- #看看 var1 列,我们发现可以处理成列表:
- df.assign(var1=df.var1.str.split(',')).explode('var1')

#横向爆炸 以上的操作都是竖向爆炸,如果想横向爆炸,可以考虑使用以下方法。
- df = pd.DataFrame({'name':['A', 'B', 'C', 'D'],'age':[10, 20, 30, 40],
- 'code':[['c1', 'c2'], ['c2', 'c3'], ['c1'], ['c1', 'c3']]})
- df

构建临时的df
- temp = df['code'].apply(pd.Series).add_prefix('code_')
- temp = pd.DataFrame(df.code.to_list()).add_prefix(f'{df.code.name}_')
- temp
#再和原数据拼接起来
pd.concat([df, temp], axis=1)
数据转置
类似矩阵转置:df.T就行
例如
- d2 = {'name': ['Alice', 'Bob'],
- 'score': [9.5, 8],
- 'employed': [False, True],
- 'kids': [0, 0]}
- df2 = pd.DataFrame(data=d2)
- df2

df2.T
#轴交换 swapaxes
#Pandas 提供了一个 DataFrame.swapaxes(axis1, axis2, copy=True) 用来做轴(行列)交换。如果行列交换就相当于 df.T。- df.swapaxes("index", "columns") # 行列交换,相当于 df.T
- df.swapaxes("columns", "index") # 同上
- df.swapaxes("index", "columns", copy=True) # 使生效
- df.swapaxes("columns", "columns") # 无变化
- df.swapaxes("index", "index") # 无变化
-
相关阅读:
探索Web Components
计算机网络:局域网的基本概念和体系结构
线程池——futuretask、CompletionService、CompletableFuture
并查集略解
Nuxt - 超详细 @nuxtjs/axios 介绍封装请求及拦截器配置(脚手架自带请求库)
Sass系统学习
暑假超越计划练习题(4)
Pytorch实现的LSTM、RNN模型结构
[附源码]JAVA毕业设计高校智能排课系统(系统+LW)
【工具】html请求 Content-Encoding=br 返回值乱码的问题 解码返回值
- 原文地址:https://blog.csdn.net/weixin_46277779/article/details/126199488