-
谷歌爬虫插件webscraper使用详细实操
谷歌爬虫插件webscraper使用详细实操
webscraper插件是一款谷歌的爬虫插件,一键拖拽就可以安装,方便操作。这个插件对于不会编程的人来说很友好,只用学会通用的操作步骤,基本可以满足日常的学习或者其他获取数据的需要。
工具优缺点介绍
就我个人使用而言,简单谈一谈这个插件的优缺点吧。
优点:
1、自然不用说就是可视化工具,只需要简单鼠标选中爬取区域操作,不需要学习像python啦这种爬虫语言。
2、爬取完成后可以导出xlsx文档,数据分类清晰直观。
缺点:
1、需要首先对插件的几个概念有所理解,比如sitemap、selector、element click、父子节点
2、看自己的爬取需求复杂度,如果简单爬取,那用到工具的text可能就够了,而大部分情况下,很多人爬的数据量多一些,会用到翻页,或者跳转二级页面。这样的话就需要多操作操作实例。
3、有些网站使用鼠标选中不准确,可能就需要一点html/css知识,不过这个也不是多难,找到数据的位置,把盒子的css定位找到,按照格式填写就可以。
4、遇到网站加载比较慢时,需要看情况而定,因为这个工具是完全爬完才可以结束,并拿到数据。所以如果中间想停了,直接断网,然后再连接,刷新数据,既可以拿到爬取的结果。插件中一些概念扫盲
1、我们爬取的数据本质是什么?
我觉得在使用这个插件之前,我们先要大概理解下,我们要爬取的目标本质是个什么。首页在你的目标网站页面,右键点击‘检查’:
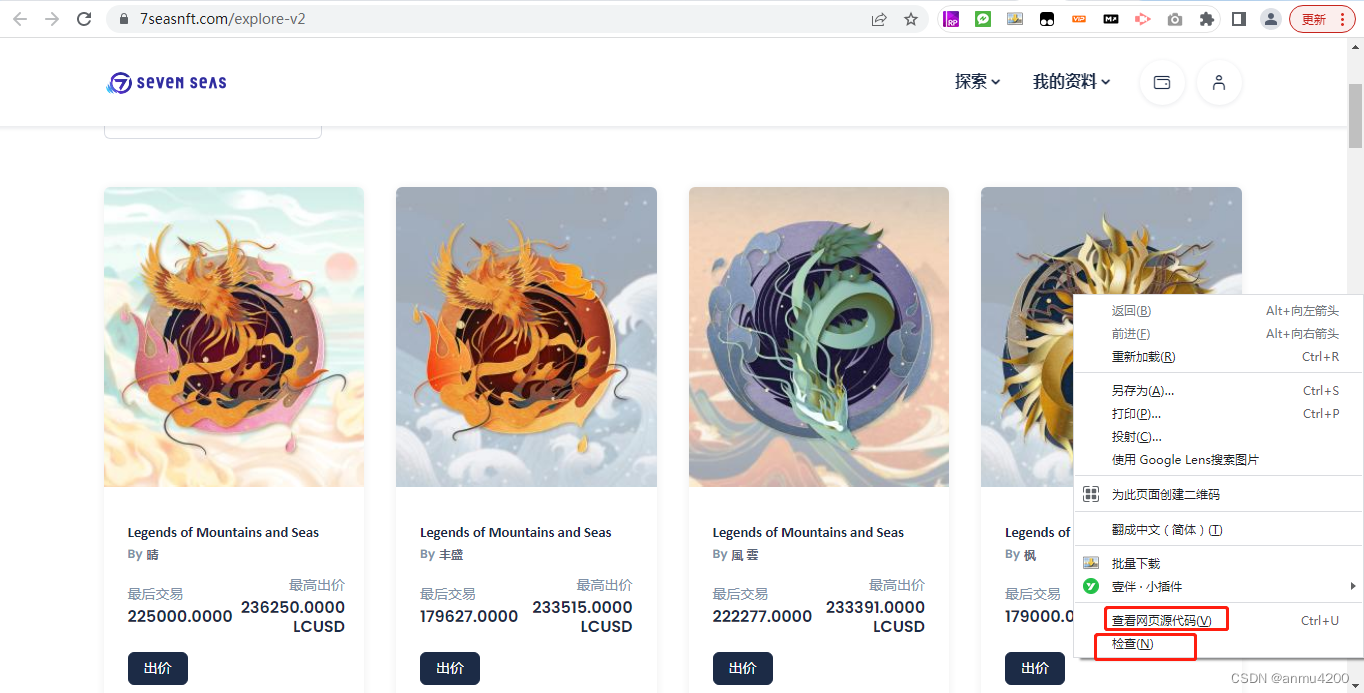
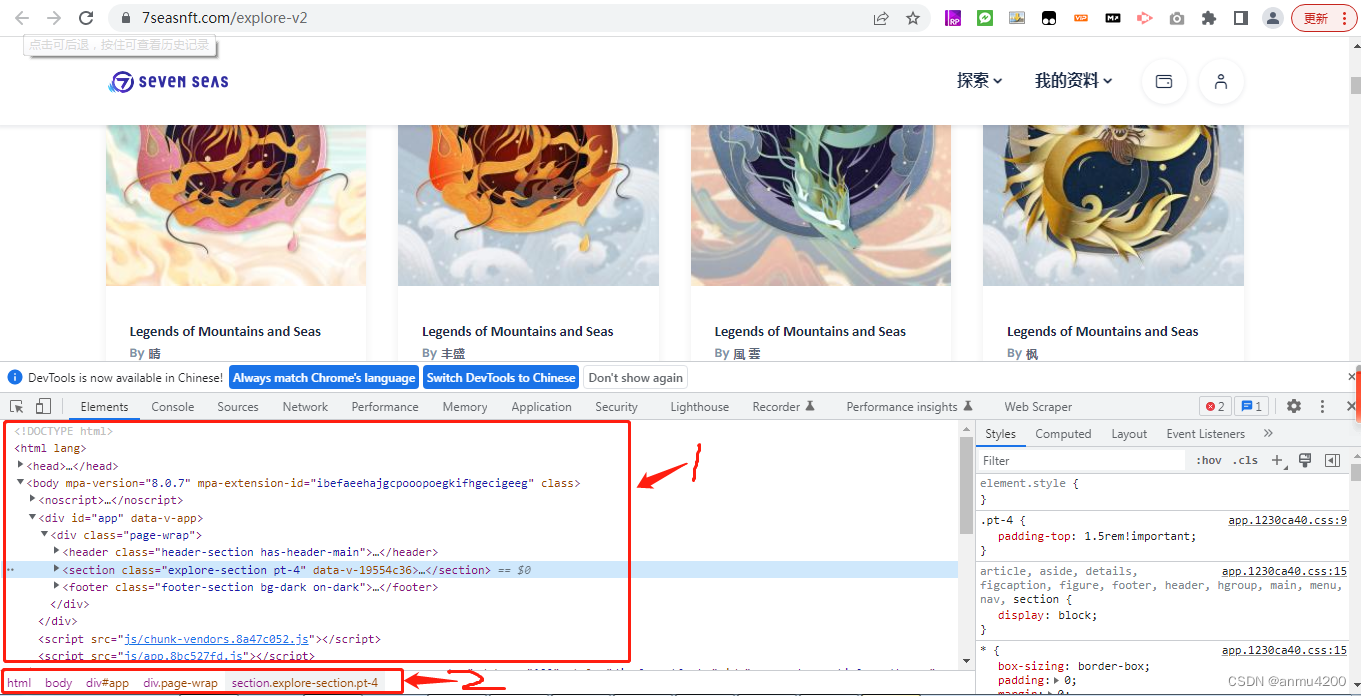
我们可以看到,这个页面的数据,其实就是一个html网页(程序语言上讲),把检查的框拖大一点,大概看一下它的结构:
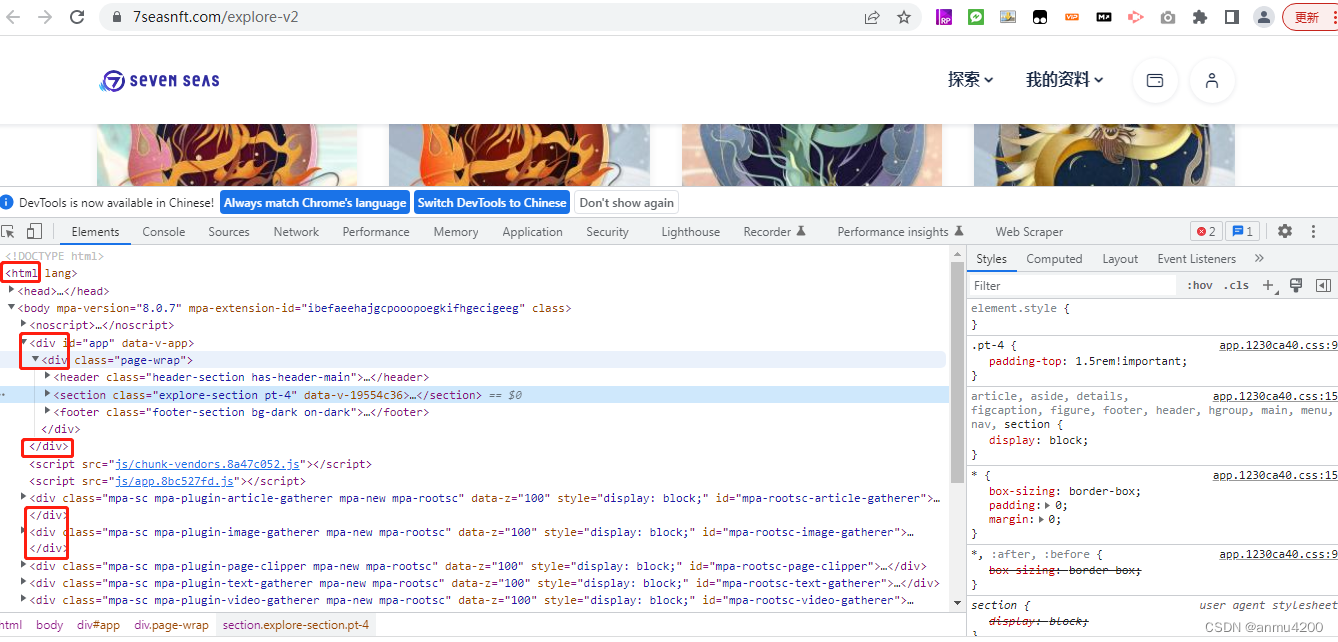
我们可以看到,它里面最核心的其实就是一堆div盒子。所以可以这么理解,页面上的这些数据,基本都是放在这个盒子里的,那么就好了。这个基础理解了之后,那么后面我们就知道,鼠标选中了哪个盒子,就爬取哪个盒子的数据。2、sitemap
sitemap可以这么理解,就相当于你用当前这个插件,新建了一个爬虫工作区,后面的爬虫操作都在这个里面进行。
3、selector
selector这个意思是选择器,直观的理解就是,我们的鼠标要选中的区域
4、element click
这里涉及到一个父子选择器,可以这么理解,比如翻页。我第一个节点,框到了所有大的div盒子,然后让自动点击下一页。接着在这个节点里面,新建一个子节点,具体爬取单个div盒子的某个内容。
插件实操1:爬取知乎热点数据
当然上面的只是一个基础的解释,不理解没有关系,直接看这里的实操,自己演示一遍,多操作操作就明白了,光听理论是没用的。
1、爬取一个当前页的数据:爬取zhi乎的近期热点数据
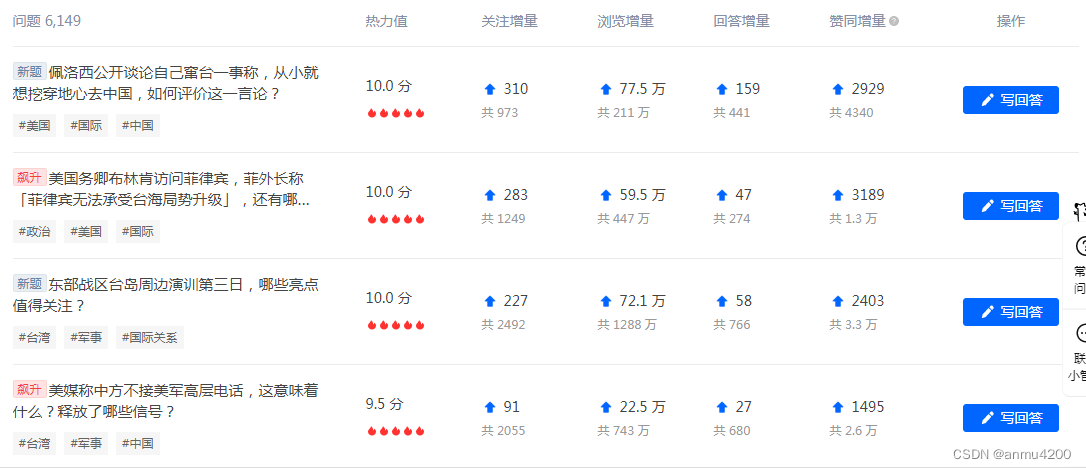
开始操作,操作步骤:
1> 右键检查,并点击web scraper插件的tab:
2> 新建一个sitemap(我们的爬虫项目,或者工作区),create sitemap,这里的名字可以随便起,比如我叫:zhihu
url贴上当前页面的url
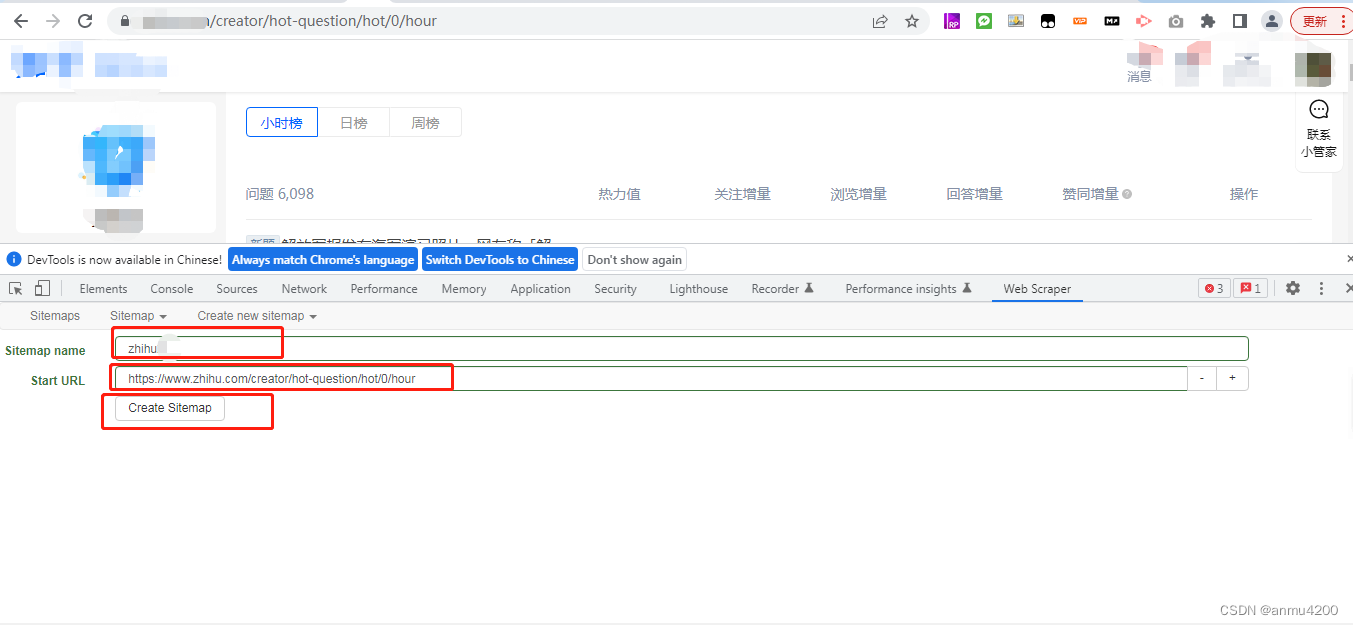
ok了,这样我们的工作区就建完了
3> 新建selector,选择爬取项

这里我们可以注意到:有一个_root节点,这个就是最外层的节点,后面的操作内容都要在这个之下接着开始,填写selector里面的内容,id:info(可以随便起),Type:Text(默认的,我们先用这个),select,点击这个后,页面鼠标光标移动到的盒子区域,就会变成浅黄色,点击要爬的区域,就编程红色,然后选中既可

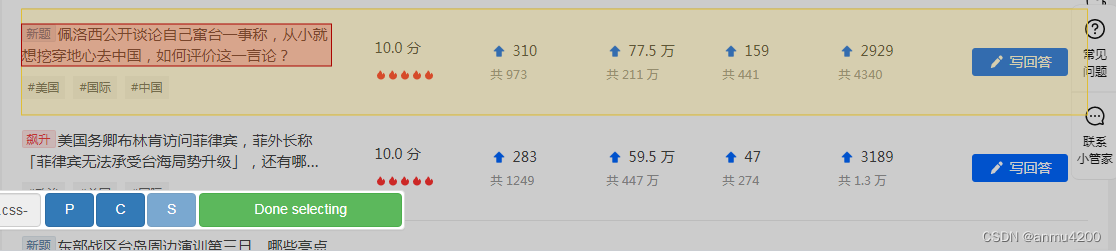
当然,这个只是选中了一个区域,如果要爬多组数据,可以继续选中第二个标题,那么这页的数据就都选中了
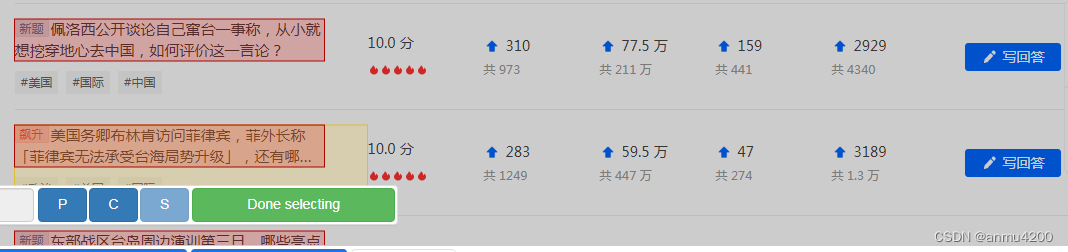
然后点击 Done selecting就完成选中工作
这个时候会看到,select后面的输入框里面,多了我们选中盒子的标识:
这块可以留意一下,后面遇到难题这里可以救命

同时下面的Multiple也选中,因为要爬多个数据:

最后save selector4> 同理,可以继续新建下一个selector
5> 爬取
选择中间这个 sitemap zhihu下拉框,选择scrape

网站响应还ok的话,这里默认2000就行(2000单位是毫秒,也就是2秒)

start scraping
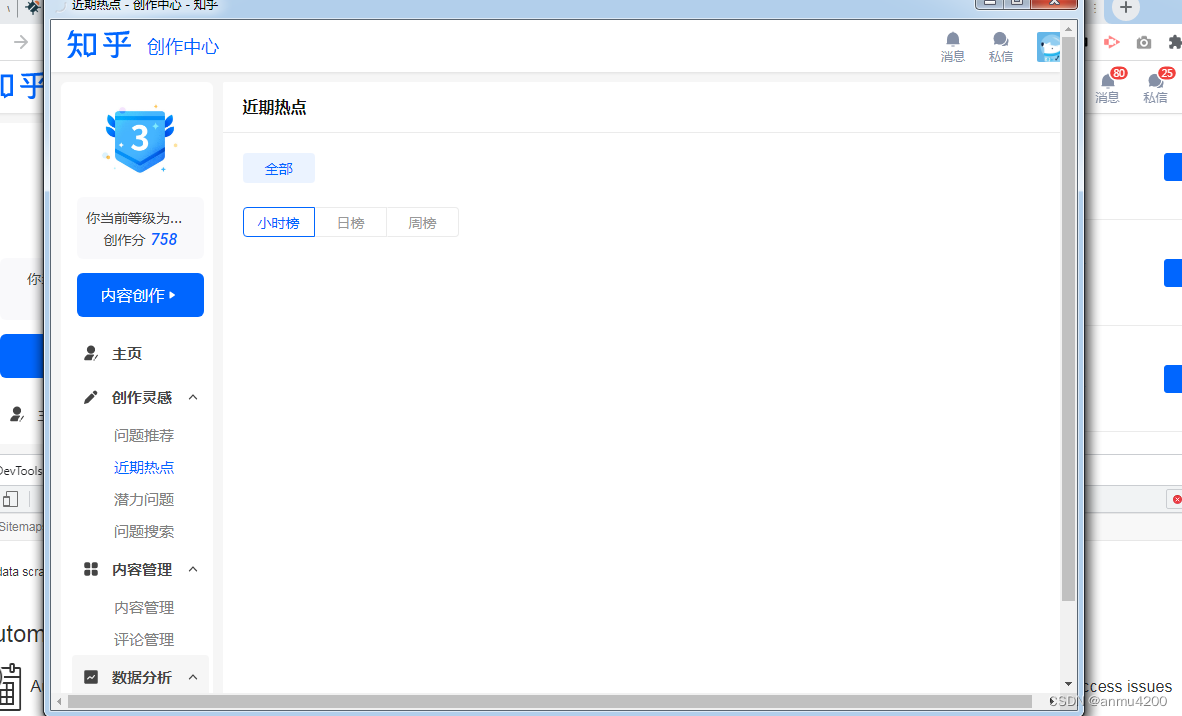
完成后点击 refresh

就能(预览)看到我们爬取的数据如果这里爬取的数据有残缺,有的没爬到,可以继续编辑原来的info和info2两个selector,选择大一点的盒子
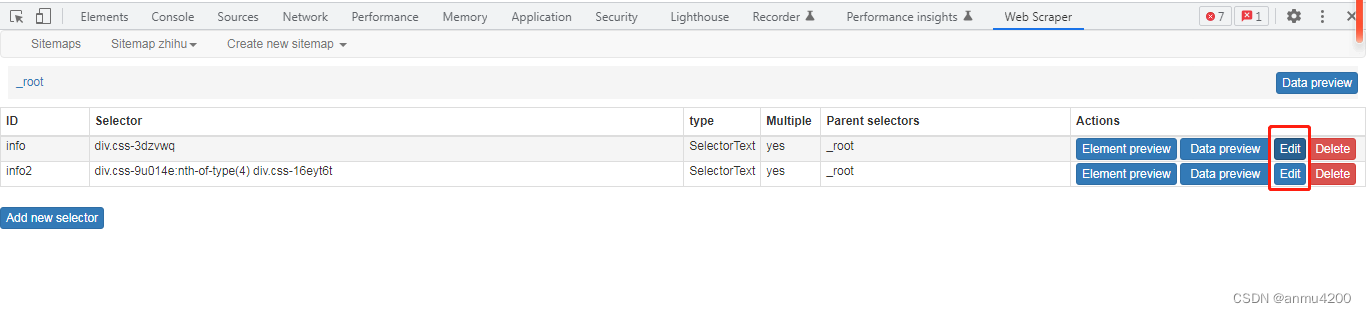
但是我们看到,这里的数据每条不对应,为什么呢?原因是,我们这样分开爬取的两个数据,是相互独立的,没有关系,所以自然无法对应。
这里得用,就是父子节点。
父子节点的意思是,父节点把最外层的数据包裹住,也就是我先取所有盒子,然后再取盒子里面的内容。
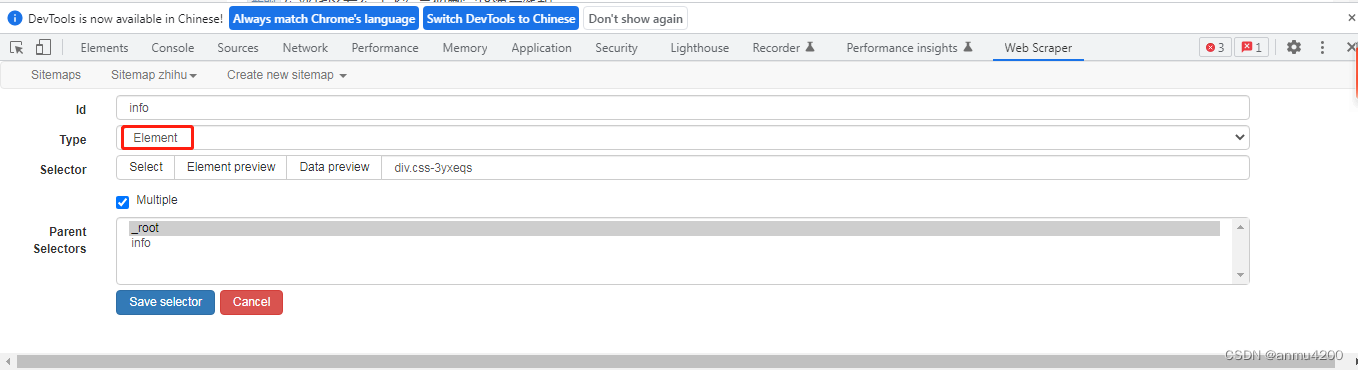
最外层先建一个父节点,选择一个大的盒子,然后子节点爬取这个盒子里的局部数据,这样就可以对应了。父节点:
父节点selector这里注意的是,Type选择Element
两个子节点:
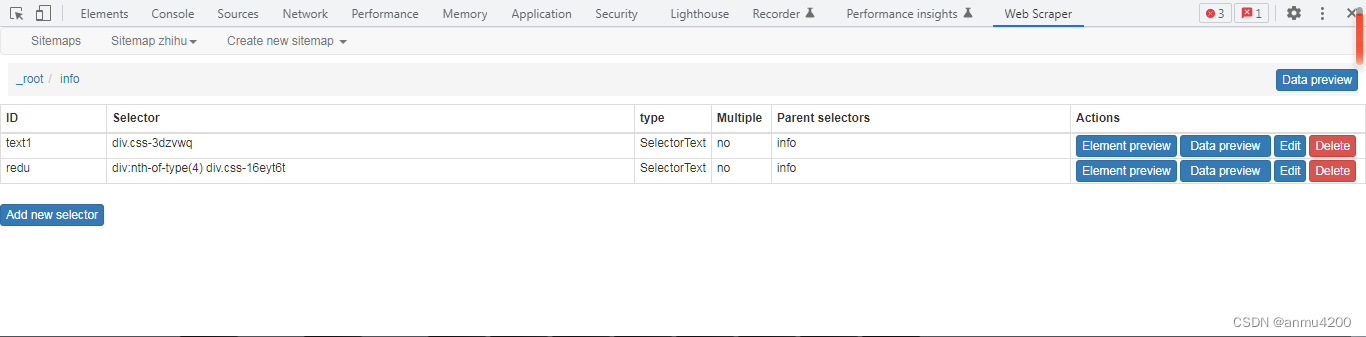
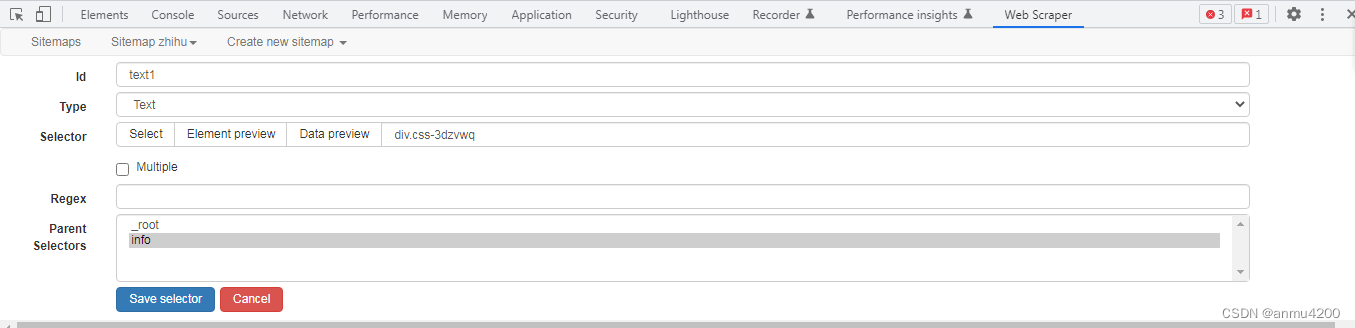
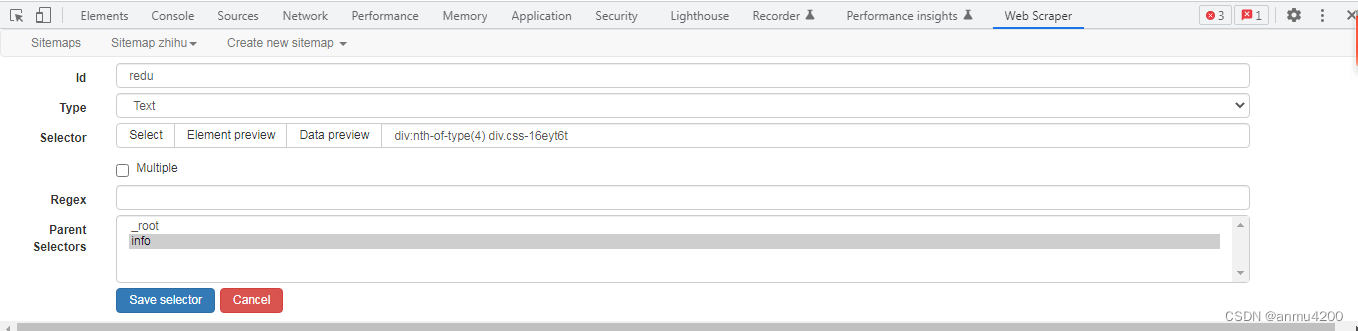
爬取数据:
这样完整的数据都爬下来了,如果你仔细看,会看到那个热度值会跟当前页面不太一样,那是因为我们爬取的是热点数据,它在实时变动,你刷新一下网页就能看到,有些热度增加了。所以这个就爬取成功了。
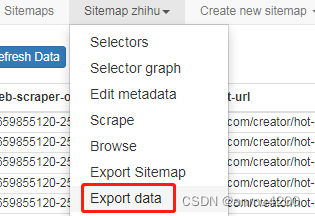
6> 下载数据到本地
Sitemap zhihu选择下拉框 Export Data
然后有两种格式可以选择
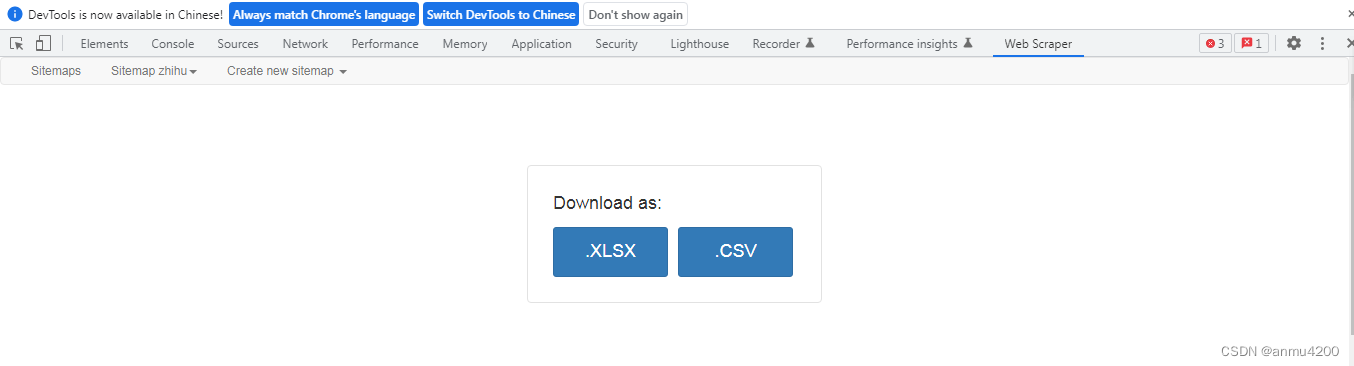
下载完成后,本地数据查看:
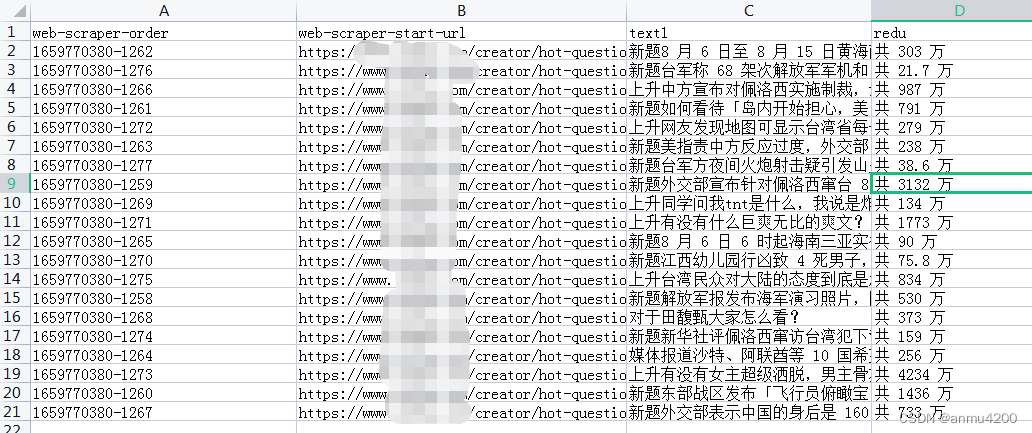
7> 本例子json串如下:
这里说一下如何查看json串,这个就是爬虫生成的脚本了,生成以后就可以让别人导入使用。Sitemao zhihu下拉框选择:Export Sitemap
{“_id”:“zhihu”,“startUrl”:[“https://www.zhihu.com/creator/hot-question/hot/0/hour”],“selectors”:[{“id”:“info”,“parentSelectors”:[“_root”],“type”:“SelectorElement”,“selector”:“div.css-3yxeqs”,“multiple”:true,“delay”:0},{“id”:“text1”,“parentSelectors”:[“info”],“type”:“SelectorText”,“selector”:“div.css-3dzvwq”,“multiple”:false,“delay”:0,“regex”:“”},{“id”:“redu”,“parentSelectors”:[“info”],“type”:“SelectorText”,“selector”:“div:nth-of-type(4) div.css-16eyt6t”,“multiple”:false,“delay”:0,“regex”:“”}]}插件实操2:爬取翻页所有数据
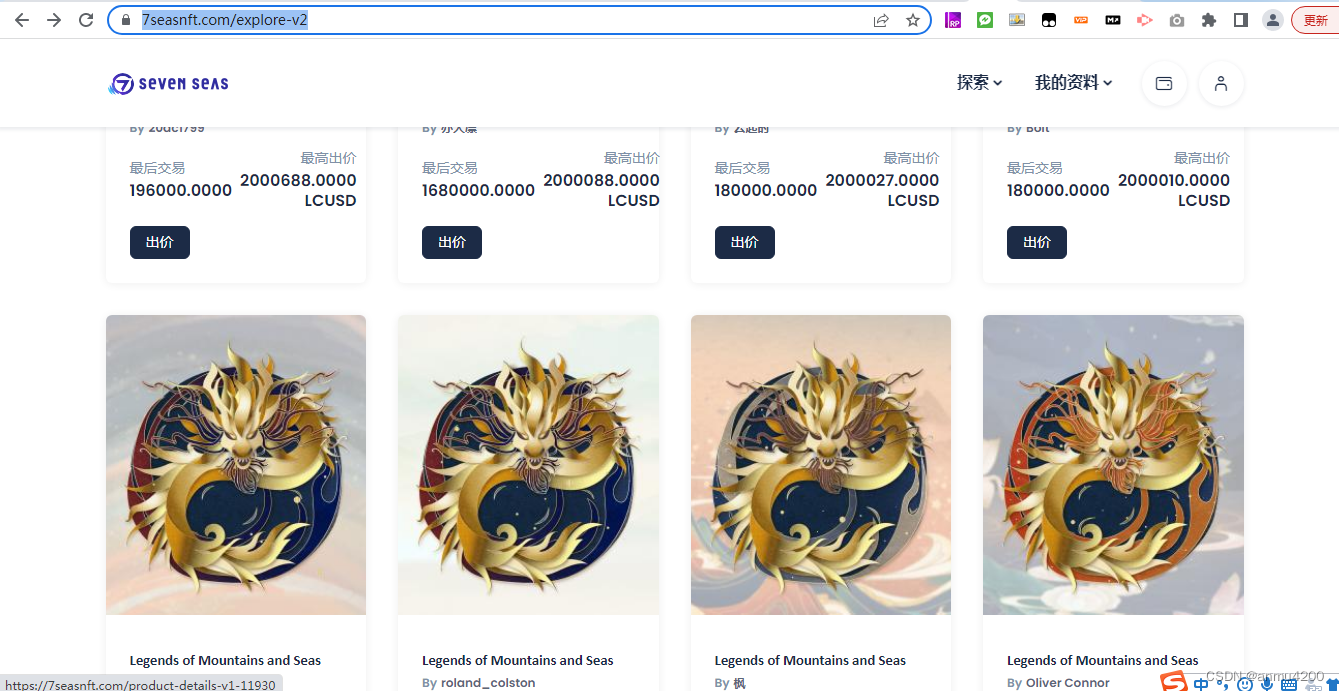
1> 这个是朋友让我帮忙爬取的一个网站
https://7seasnft.com/explore-v2
2> 新建sitemap
前面的步骤,如何切到web scraper,可以看上一个例子的步骤,这里就不赘述了。
3> 新建父节点
父节点,也是和前面一样,需要选择为Element类型的,但是这里我们要实现翻页,所以类型需要选为:Element click。
这里的Element click和上面的Element,可以这么区别,不翻页的话,就是选中爬虫的区域是这些所有的盒子,而翻页的话需要在这个基础上加上点击下一页,也就是多了click来点击下一页的按钮。id: info
Type:Element click
selector:(这里就是来选中爬虫区域的)
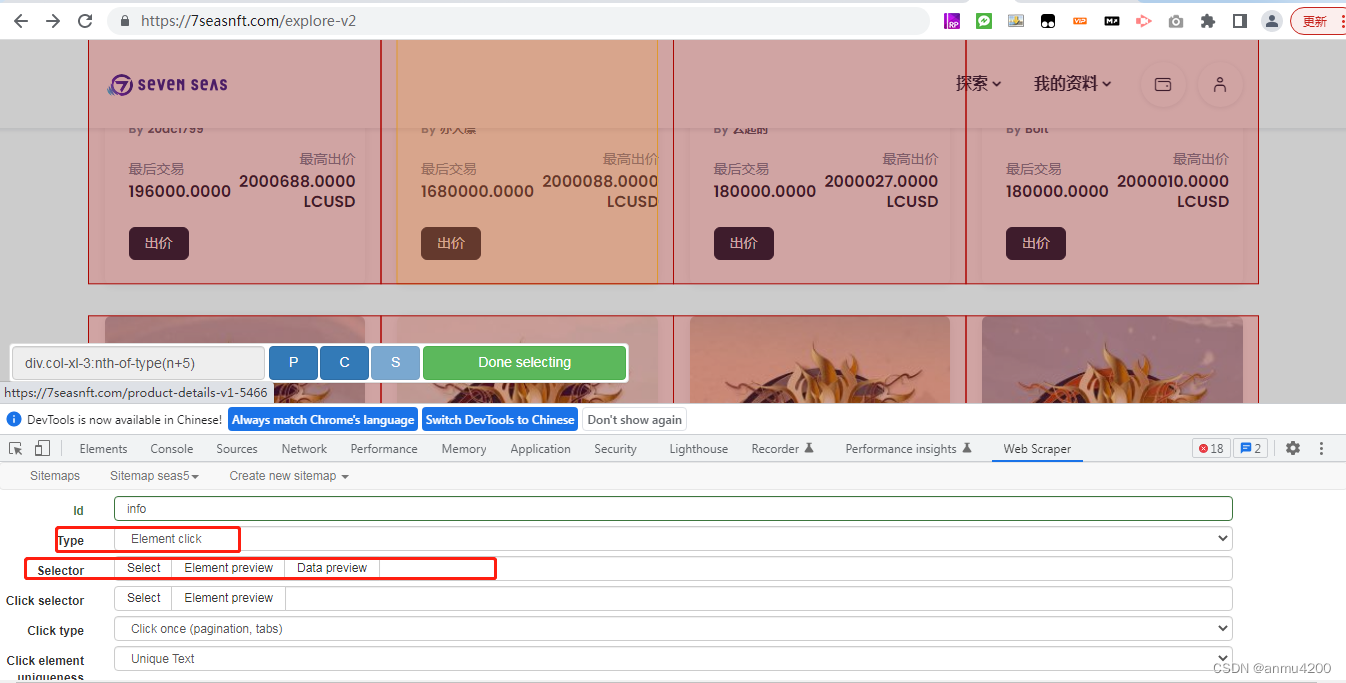

Click selector: (这里就是在选完所有爬虫区域后,我们要点击的下一页的按钮)
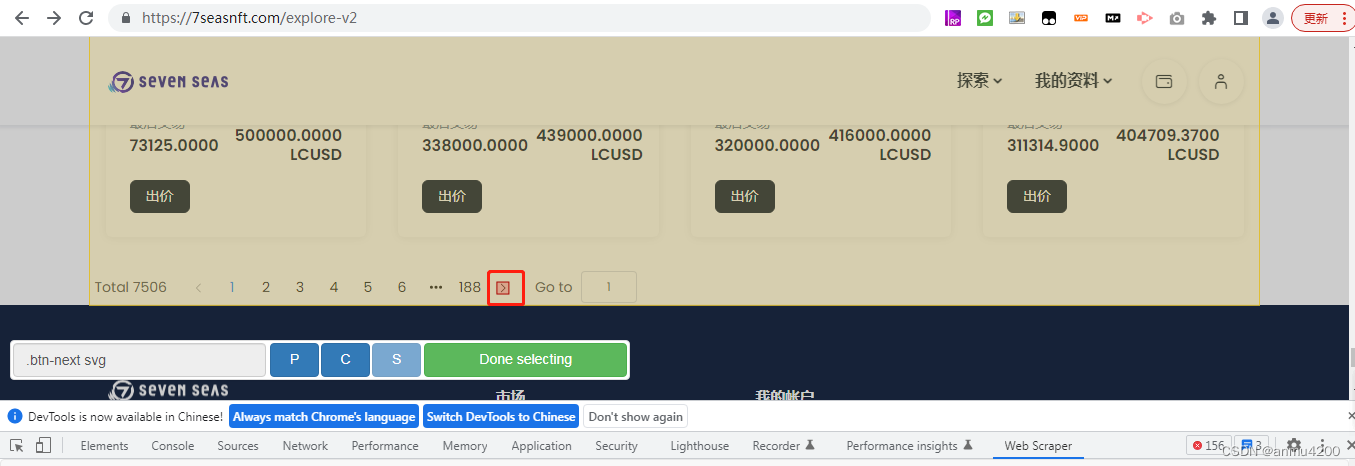
选择这个。这里有个坑,就是在选择了这个小的区域后,我试了下爬不出来数据,后来我选择了一个大的框(还是要多试试吧):
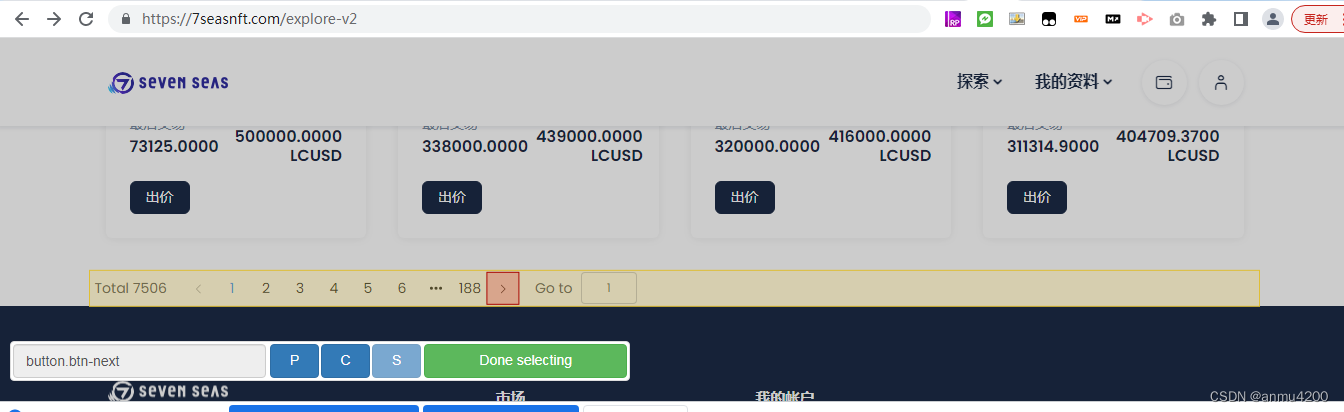
Click type: (这里说的是,点击下一页,是点一次,还是点多次,我们选择click more这个选项,意思就是循环点击下一页)

Click element uniqueness:选择Uniqe HTML+TextDelay:6000(看自己的网站响应,慢的话可以多延迟点)
其他的选项默认既可4> 新建子节点(这里就是来爬取具体内容了)
子节点这里在选择我要爬的标题的时候,死活选不中,看来鼠标选中这个不好使了
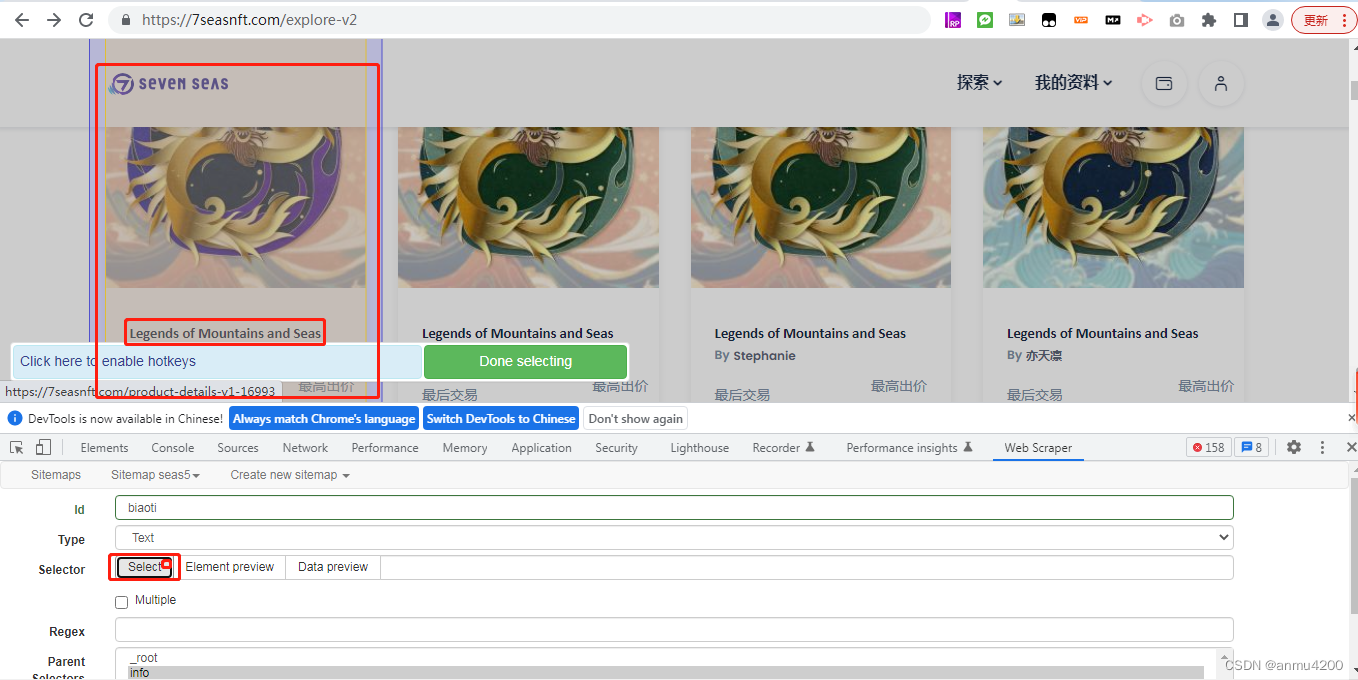
这里就得用另一种办法:
页面选择到Element这个tab,然后用那个箭头去找这个标题所在的div
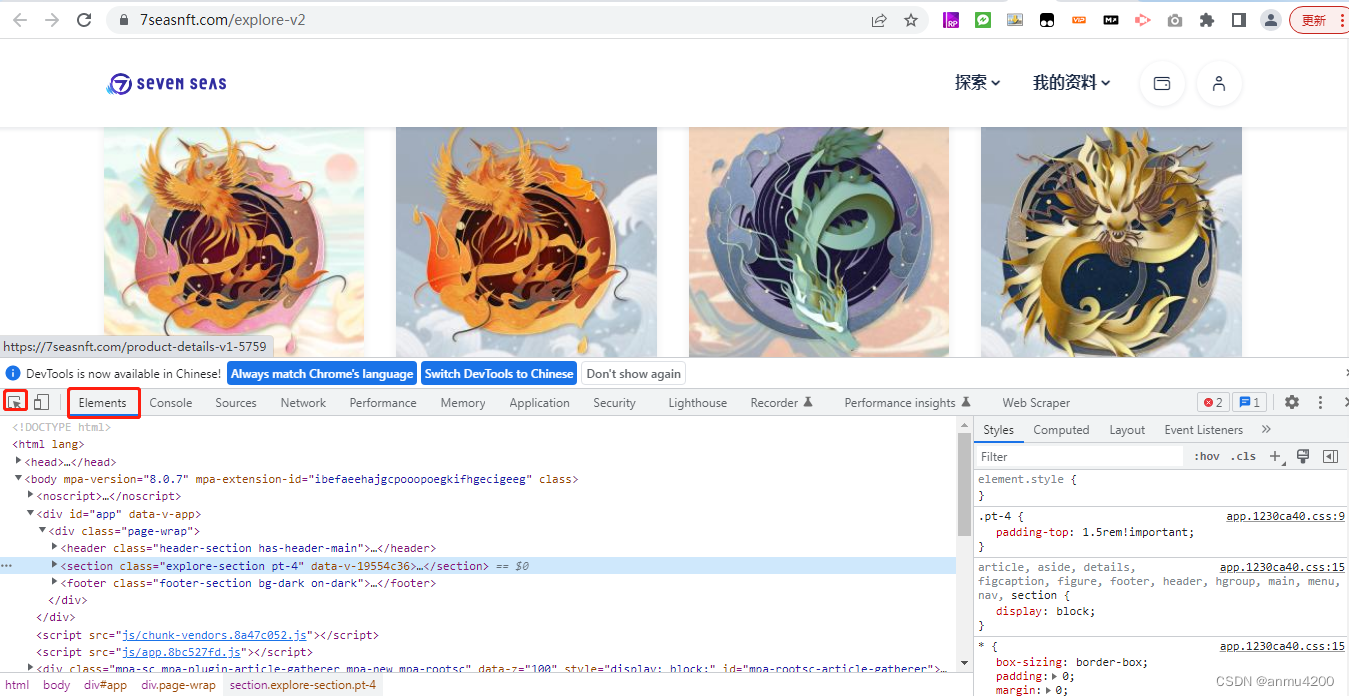
找到它是在这个盒子里:

所以这里的标题,我们直接填写:

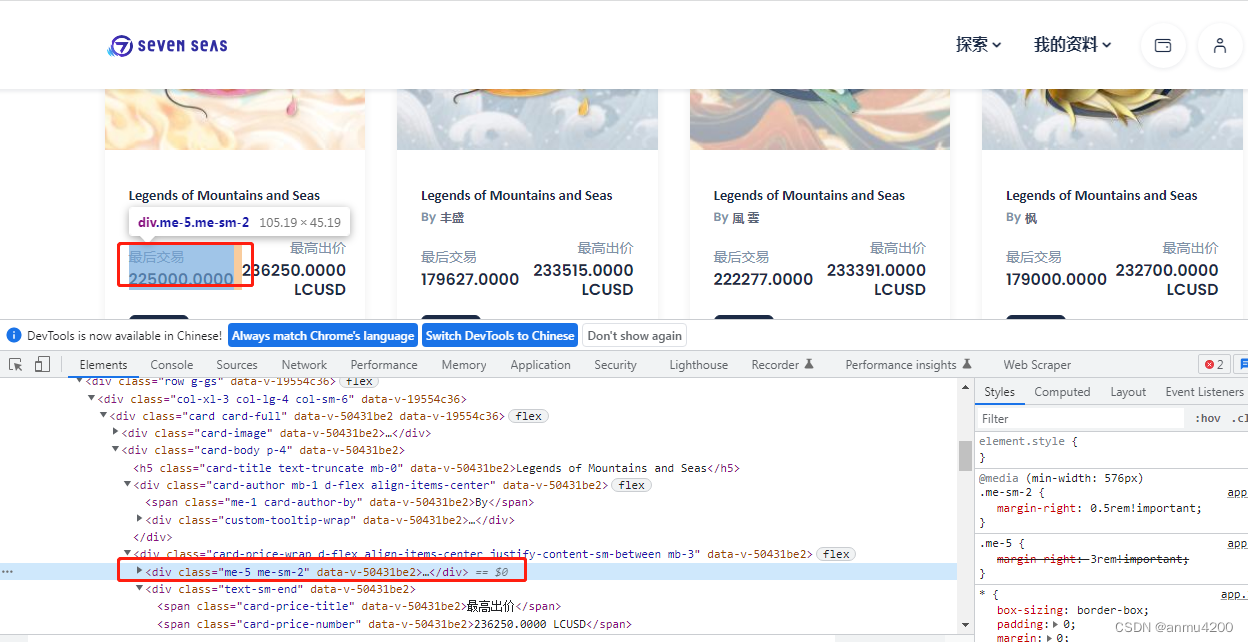
同样的办法,我们再找到,后面两个的:
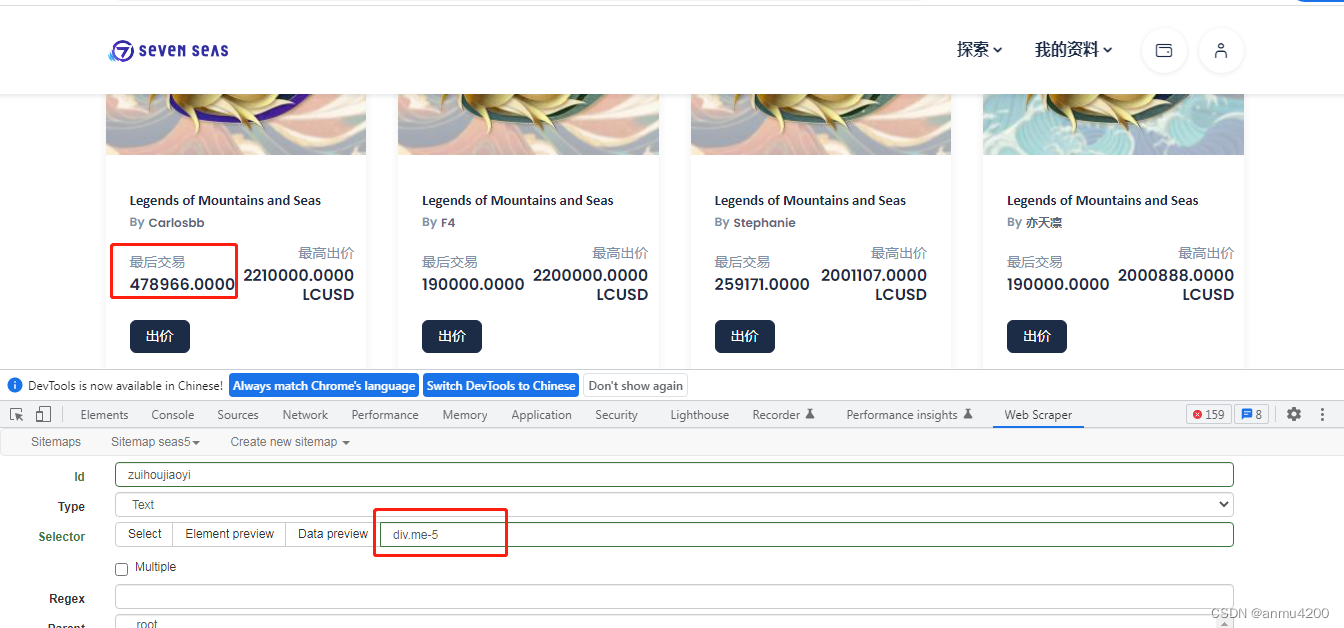
最后交易盒子:
最高出价盒子:
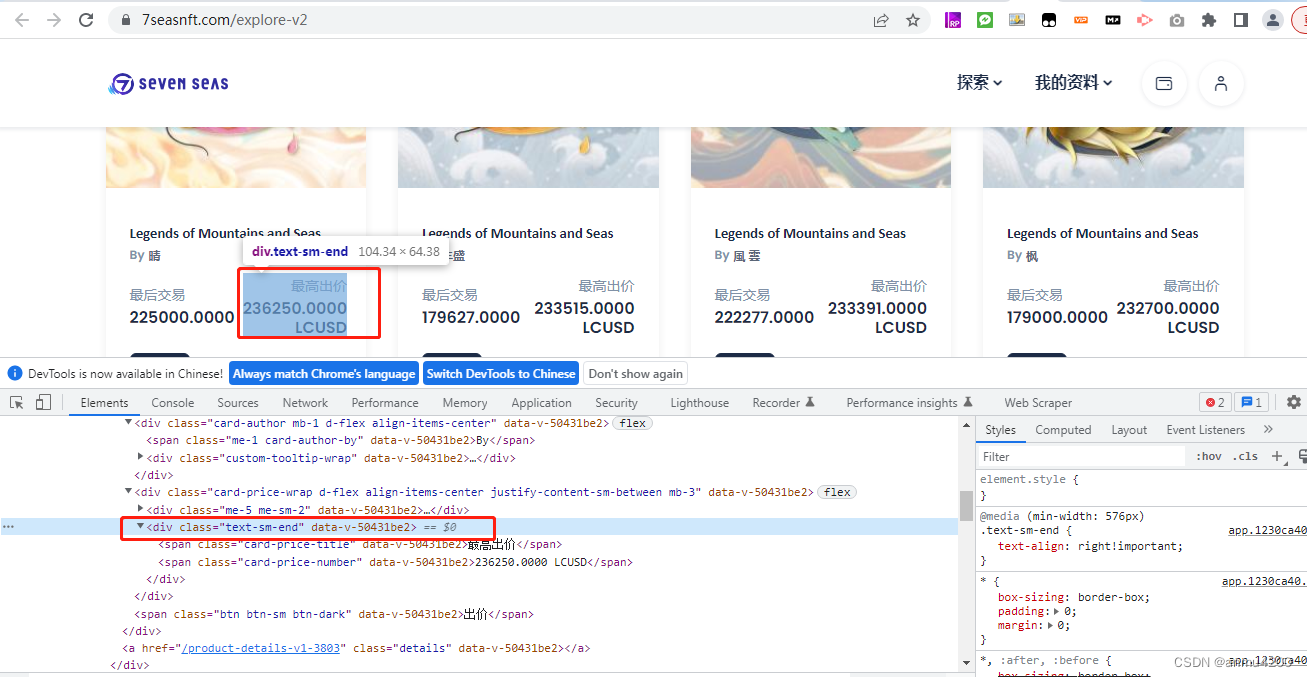
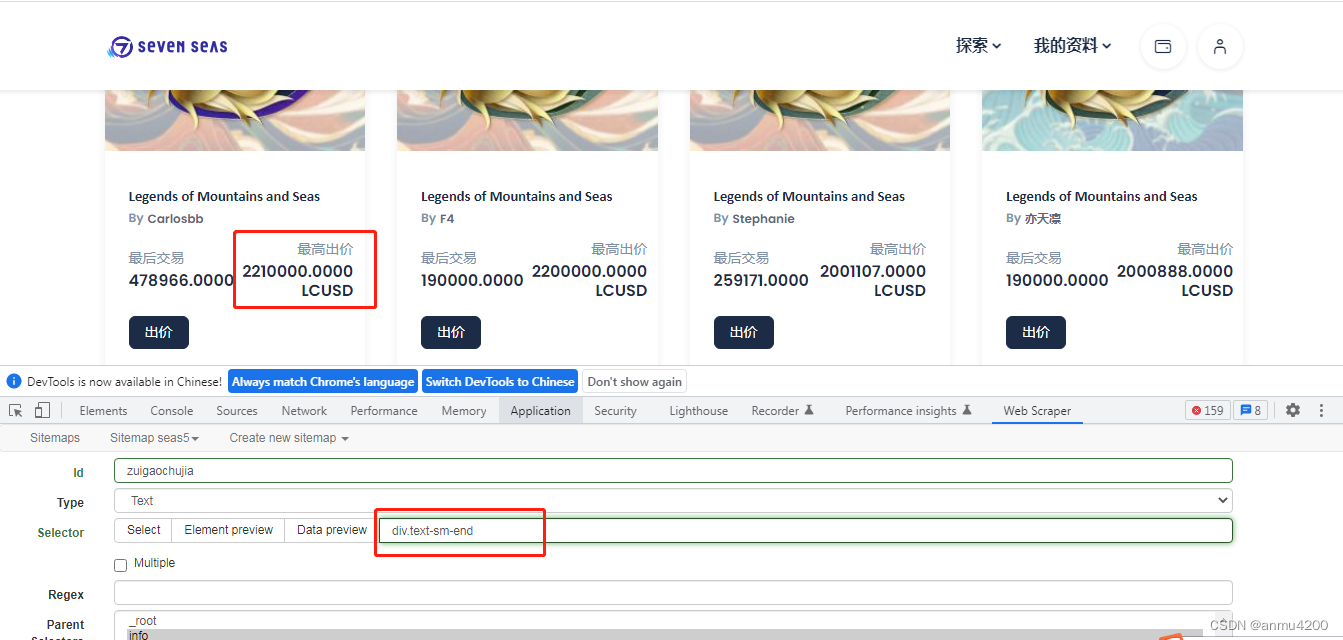
好了我们 的子节点也建好了5> 测试爬取
这里的话,因为数据比较多,所以如果想爬取一部分,中间可以断一下网,然后就可以看到数据了

延迟时间,根据自己的情况而定
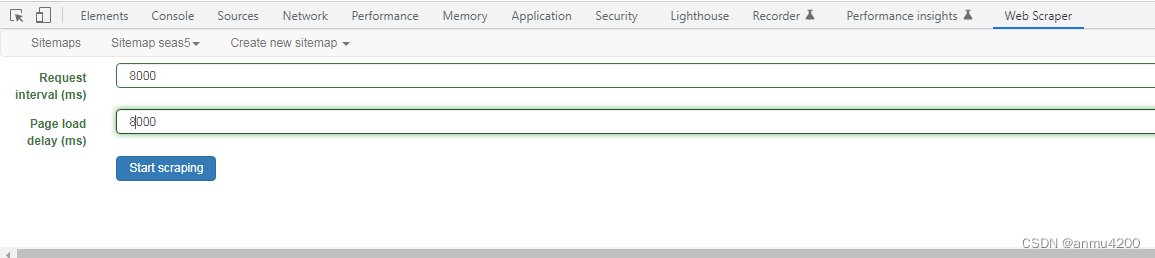
开始爬取
断网一下
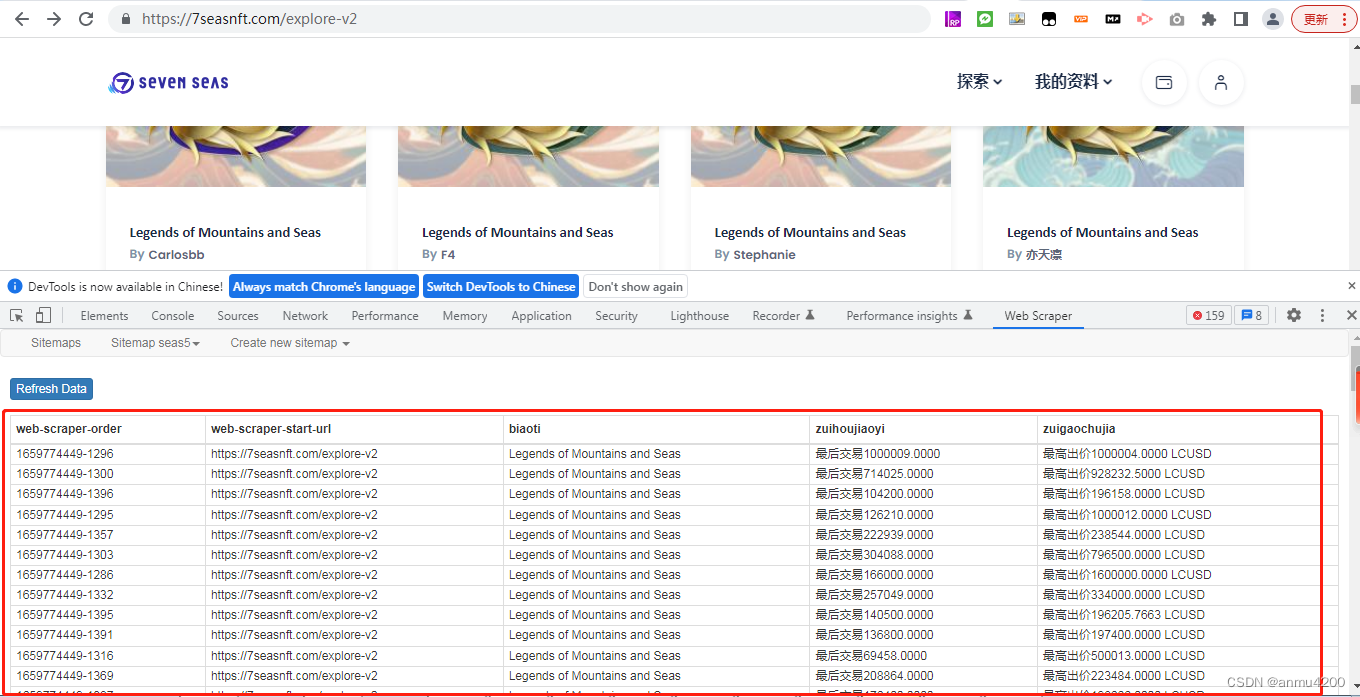
测试爬取成功6> 导出本地
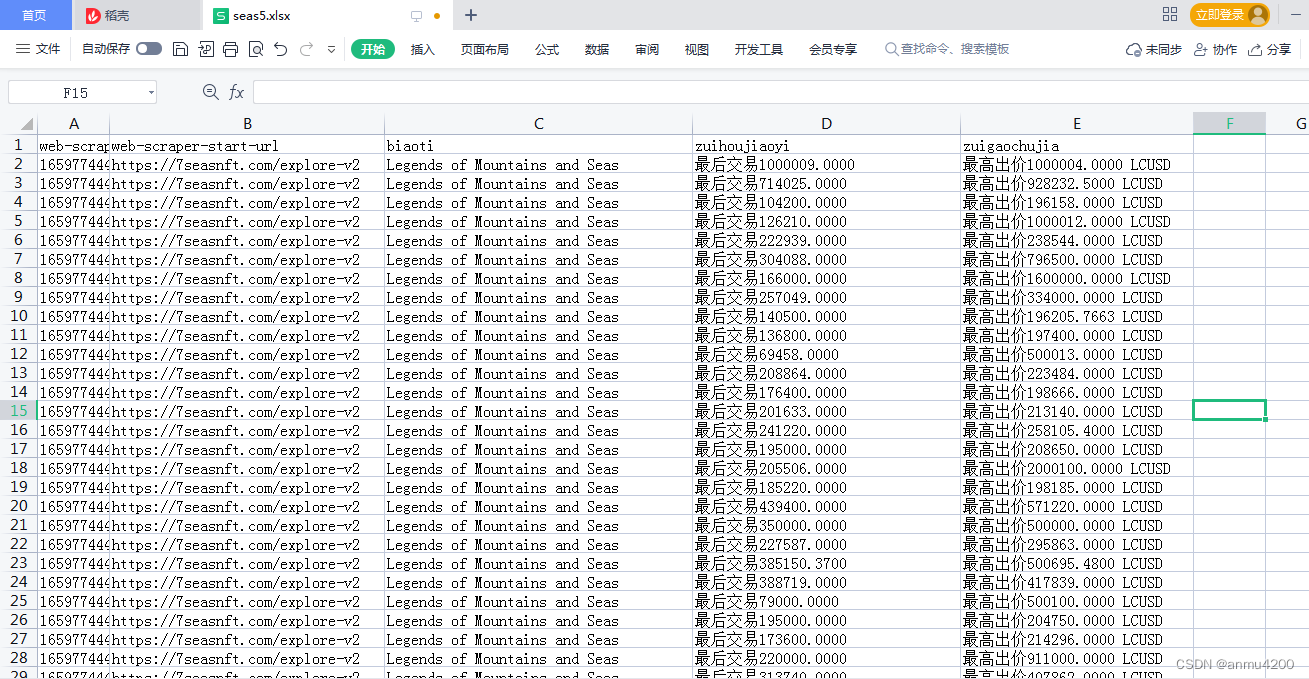
7> 例子json串
{“_id”:“seas5”,“startUrl”:[“https://7seasnft.com/explore-v2”],“selectors”:[{“clickElementSelector”:“button.btn-next”,“clickElementUniquenessType”:“uniqueHTMLText”,“clickType”:“clickMore”,“delay”:6000,“discardInitialElements”:“do-not-discard”,“id”:“info”,“multiple”:true,“parentSelectors”:[“_root”],“selector”:“div.col-xl-3”,“type”:“SelectorElementClick”},{“delay”:0,“id”:“biaoti”,“multiple”:false,“parentSelectors”:[“info”],“regex”:“”,“selector”:“h5.card-title”,“type”:“SelectorText”},{“delay”:0,“id”:“zuihoujiaoyi”,“multiple”:false,“parentSelectors”:[“info”],“regex”:“”,“selector”:“div.me-5”,“type”:“SelectorText”},{“delay”:0,“id”:“zuigaochujia”,“multiple”:false,“parentSelectors”:[“info”],“regex”:“”,“selector”:“div.text-sm-end”,“type”:“SelectorText”}]}【以上内容仅供学习交流,切勿用作非法用途】
写在最后
如果使用webscraper插件遇到问题,或者需要pdf和视频教程,可以加博主V交流:Code2Life2
觉得有用,记得一键三连哦!
-
相关阅读:
Git版本控制管理——分支
目标检测中几个算法的正负样本划分策略
从感官沉浸到无边界互操作,细数元宇宙游戏的底层逻辑世界
LibTorch | 使用神经网络求解一维稳态对流扩散方程
加权自动机:在 Semirings 上建模
意法STTH60RQ06-Y汽车级快恢复二极管,原厂渠道ASEMI代理
基于大数据的Pagerank实验设计
上海亚商投顾:沪指重返3100点 房地产板块掀涨停潮
版本控制 | 想要成为硬件设计高手?最佳实践了解一下!
Redis高可用方案
- 原文地址:https://blog.csdn.net/anmu4200/article/details/126193673