-
Shell 正则及其命令
目录
一、sort
- sort排序
- 基本用法:
- sort 选项 文件
- 默认以字符排序(a b c d),如果第一个字母相同,比较第二个,以此类推


- -t指定分隔符
- -k指定需要排序的列
- -n以数字形式排序
- -r反向排序
- -u去重



二、uniq
- uniq 去重
- uniq 选项... 文件…....
- 基本功能:只能将连续的重复去掉
- -c 统计字符出现的次数
- 后面是字符数字前面是出现的次数
- -d 只显示有连续重复的行
- -u 只显示出现1次的行(2个及2个以上不显示)


三、tr
- 基本功能是转换
- 只要出现 d e f 就转换成 2 6 8
- 当转换数值不足时,一直转换成最后一个
- 实际应用:将文件中的所有小写转换成大写
- -d删除匹配到的字符
- -s 压缩 将连续的数字8压缩成1个数字8
- -c反向取值




四、cut
- cut 切片 提取需要的列
- cut [选项] [文件]
- -d 指明分隔符
- -f 指明需要的列数

实际应用



- wc
- wc 选项 目标文件
- 统计列数,wc本身就是参数 word
- -l: 统计行数
- -w: 统计单词个数
- -C: 统计字节数
- 注意空行和换行符
五、paste
-d 指定分隔符

综合应用
cat nginx.access.log-2021013 |cut -d" " -f1

cat nginx.access.log-2021013 |cut -d" " -f1|sort
cat nginx.access.log-2021013 |cut -d" " -f1|sort -n|uniq -c
cat nginx.access.log-2021013 |cut -d" " -f1|sort -n|uniq -c|sort -nr
cat nginx.access.log-2021013 |cut -d" " -f1|sort -n|uniq -c|sort -nr|head
cat nginx.access.log-2021013 |awk '{print $1}'|sort -n|uniq -c|sort -nr|head
六、正则表达式
REGEXP: Regular Expressions,由一类特殊字符及文本字符所编写的模式,其中有些字符(元字符)不表示字符字面意义,而表示控制或通配的功能,类似于增强版的通配符功能,但与通配符不同,通配符功能是用来处理文件名,而正则表达式是处理文本内容中字符。
正则表达式被很多程序和开发语言所广泛支持: vim, les,grep,sed,awk, nginx,mysql等,主要用来匹配字符串(命令结果,文本内容),通配符匹配文件(而且是已存在的文件)find 命令支持通配符 vim 命令支持正则表达式
基本正则表达式
扩展正则表达式1.元字符
. 匹配任意单个字符,可以是一个汉字
[] 匹配指定范围内的任意单个字符
[^] 匹配指定范围外的任意单个字符
如果 . 写在[ ]就是 . 不需要转义 转义 . \. 代表转义


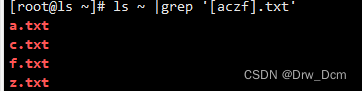





2.次数
(1) * 匹配前面的字符任意次,包括0次,贪婪模式:尽可能长的匹配
(2) .* 任意长度的任意字符
(3) \? 匹配其前面的字符出现0次或1次,即:可有可无
(4) \+ 匹配其前面的字符出现最少1次,即:肯定有且>=1次
(5) \{n\} 匹配前面的字符n次(精确匹配)
(6) \{m,n\} 匹配前面的字符至少m次,至多n次
(7) \{,n\} 匹配前面的字符至多n次,<=n
(8) \{n,\} 匹配前面的字符至少n次


3.扩展
* 匹配前面字符任意次
? 0或1次
+ 1次或多次
{n} 匹配n次
{m,n} 至少m,至多n次
{,n} 匹配前面的字符至多n次, <=n,n可以为0
{n,} 匹配前面的字符至少n次, >=n,n可以为0实际应用



-
相关阅读:
SemanticKITTI点云标注工具
总结/笔记-vue中的插槽(默认插槽、具名插槽、作用域插槽)
最大二叉树
mycat分库分表实战
网络通信类API 推荐
MV*结构的发展
威纶通触摸屏制作自定义欢迎界面的几种方法介绍
Django学习日志10
电脑病毒感染C卷(Java&&Python&&C++&&Node.js&&C语言)
RabbitMQ的六种模式
- 原文地址:https://blog.csdn.net/Drw_Dcm/article/details/126191610
