-
语音识别与转换小试牛刀(1)
前言
这几天突然觉得语音有点儿意思。想探索一些用一些库来实现下。
语音合成
Text-to-Speech, 简称TTS
之前有一篇记录 语音合成模型小抄(1)pyttsx3
首先, 下载好pyttsx, 由于我看的 文档 是2.6的,所以这里我就下载2.6版本的pyttsx3
pip install pyttsx3==2.6- 1
直接读出来
import pyttsx3 zh_voice_id = 'HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Speech\Voices\Tokens\TTS_MS_ZH-CN_HUIHUI_11.0' en_engine = pyttsx3.init() # 默认英文 zh_engine = pyttsx3.init() zh_engine.setProperty('voice', zh_voice_id) def say_text(engine, text): show_engine_info(engine) engine.say(text) engine.runAndWait() def show_engine_info(engine): voices = engine.getProperty('voices') for voice in voices: print("Voice:") print(" - ID: %s" % voice.id) print(" - Name: %s" % voice.name) print(" - Languages: %s" % voice.languages) print(" - Gender: %s" % voice.gender) print(" - Age: %s" % voice.age) if __name__ == '__main__': say_text(en_engine, 'I will study hard. Only in this way can I get a good remark.') # say_text(zh_engine, '我觉得我没说谎') # 中文还是有问题- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
转存为文件。发现: ‘Engine’ object has no attribute ‘save_to_file’
等我有空看看这个版本下的源码…
FastSpeech2
项目链接 https://github.com/ming024/FastSpeech2
我是在colab上跑的,修改notebook为GPU加速
需要把作者的ckpt(当然自己训练也可以, 就直接放到指定地方即可)加载到google网盘中def copy_pretrained_weight(ckpt_name, ckpt_share_path): assert ckpt_name in ['LJSpeech', 'AISHELL3', 'LibriTTS'] if not os.path.exists('output'): os.mkdir('output') if not os.path.exists('output/ckpt'): os.mkdir('output/ckpt') dir_path = 'output/ckpt/{}'.format(ckpt_name) if not os.path.exists(dir_path): os.mkdir(dir_path) shutil.copy(ckpt_share_path, dir_path) copy_pretrained_weight('LibriTTS', '/content/drive/MyDrive/share/FastSpeech2/LibriTTS_800000.pth.tar')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
改一下pretrained名字
os.rename('/content/FastSpeech2/output/ckpt/LibriTTS/LibriTTS_800000.pth.tar', '/content/FastSpeech2/output/ckpt/LibriTTS/800000.pth.tar')- 1
- 2
我这里是跑 LibriTTS 的版本,多人英文语音合成,其实还有中文的版本AISHELL3, 看一下readme.md就懂了,这里就不说了。
然后需要安装一下requirements.txt中的库,解压一下 HiFiGAN, 这里hifigan是decoder.!unzip -d /content/FastSpeech2/hifigan /content/FastSpeech2/hifigan/generator_universal.pth.tar.zip- 1
跑起来
!python3 synthesize.py --text "Want the stars and the sun, want the world to surrender, and want you by your side."\ --speaker_id 0 --restore_step 800000 --mode single -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml -t config/LibriTTS/train.yaml- 1
- 2
输出信息:
Removing weight norm…
Raw Text Sequence: Want the stars and the sun, want the world to surrender, and want you by your side
Phoneme Sequence: {W AA1 N T DH AH0 S T AA1 R Z AE1 N D DH AH0 S AH1 N sp W AA1 N T DH AH0 W ER1 L D T AH0 S ER0 EH1 N D ER0 sp AE1 N D W AA1 N T Y UW1 B AY1 Y AO1 R S AY1 D}同时还输出了两个文件
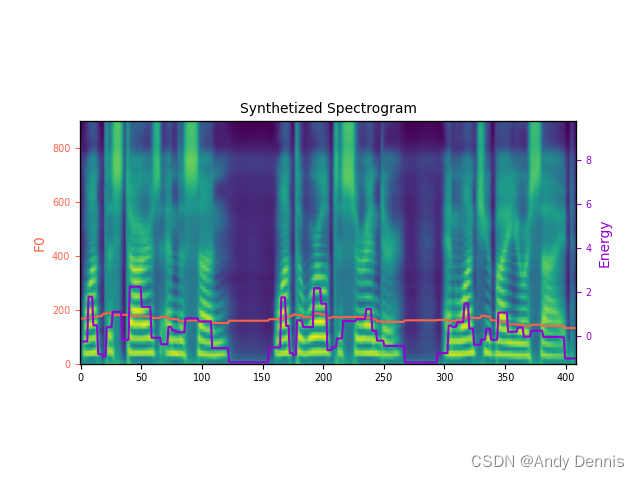
下载到本地后,look一下.这句话生成的梅尔谱。另外.wav文件直接点击就可以播放啦。(该wav文件我会拿来做ASR的例子hh)
语音识别
Automatic Speech Recognition 简称 ASR
pocketSphinx
本来想安装的,结果报错了,看其他博客好像要安装其他东西,先做罢
wenet
https://github.com/wenet-e2e/wenet
pip install wenet- 1
可以先去下载 https://github.com/wenet-e2e/wenet/releases/download/
这些文件,当然也可以直接不指定model_dir,它会自己下载到 C:/Users/Administrator/.wenet/
import sys import wave import wenet def wav2text(test_wav, only_last=True): with wave.open(test_wav, 'rb') as fin: assert fin.getnchannels() == 1 wav = fin.readframes(fin.getnframes()) decoder = wenet.Decoder(lang='en', model_dir='.wenet/en') # We suppose the wav is 16k, 16bits, and decode every 0.5 seconds interval = int(0.5 * 16000) * 2 result = [] for i in range(0, len(wav), interval): last = False if i + interval < len(wav) else True chunk_wav = wav[i: min(i + interval, len(wav))] ans = decoder.decode(chunk_wav, last) result.append(ans) if only_last: return result[-1] return result if __name__ == '__main__': test_wav = 'demo/demo.wav' text = wav2text(test_wav) print(text)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
{
“nbest” : [{
“sentence” : “want the stars and the sun want the world to surrender and want you by your side”
}],
“type” : “final_result”
}看了一下输出内容就是 (没有标点符号…是个问题)
want the stars and the sun want the world to surrender and want you by your side原文:
Want the stars and the sun, want the world to surrender, and want you by your side -
相关阅读:
DADPS Biotin Azide( CAS:1260247-50-4生物素基团和叠氮基团的 PEG 衍生物
如何使用 GTX750 或 1050 显卡安装 CUDA11+
使用 Grafana 使用JSON API 请求本地接口 报错 bad gateway(502)解决
作为一面面试官,如何考察候选人
基于Android+vue的大学生综合信息处理软件APP设计
C#,骑士游历问题(KTP,Knight Tour problem)的回溯(backtracking)算法与源程序
【嵌入式项目应用】__一款简单易用的嵌入式软件程序框架_时间片轮询框架
A-Level物理例题解析及练习Phase Difference
Swagger ui接口自动化批量漏洞测试
【无公网IP】在公网环境下Windows远程桌面Ubuntu 18.04
- 原文地址:https://blog.csdn.net/weixin_43850253/article/details/126187251


