-
【博客439】Kubernetes CRI
Kubernetes CRI
kubelet架构

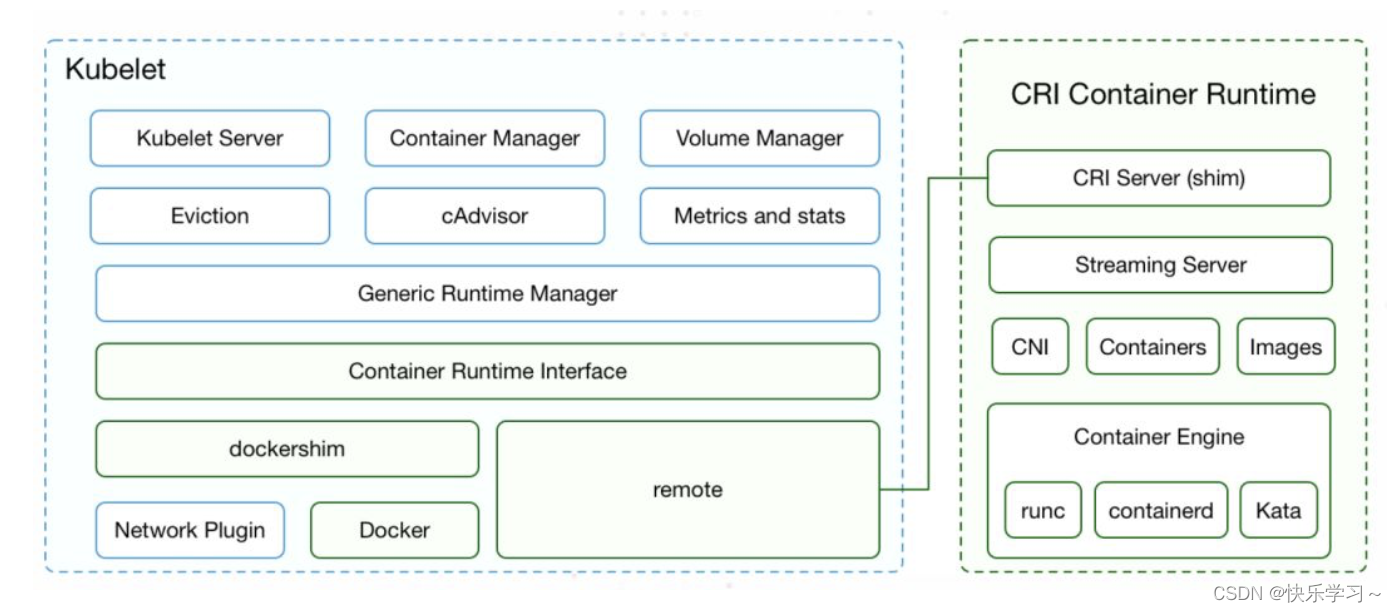
kubelet 的组件包括:
Kubelet Server:对外提供 API,供 kube-apiserver、metrics-server 等服务调用。 比如 kubectl exec 时需要通过 Kubelet API /exec/{token} 与容器进行交互; Container Manager:管理容器的各种资源,比如 CGroups、QoS、cpuset、device 等; Volume Manager:管理容器的存储卷,比如格式化资盘、挂载到 Node 本地、最后再将挂载路径传给容器; Eviction:负责容器的驱逐,比如在资源不足时驱逐优先级低的容器,保证高优先级容器的运行; cAdvisor:负责为容器提供 Metrics; Metrics 和 stats:提供容器和节点的度量数据, 比如 metrics-server 通过 /stats/summary 提取的度量数据是 HPA 自动扩展的依据; Generic Runtime Manager:是容器运行时的管理者,负责于 CRI 交互,完成容器和镜像的管理; 在 CRI 之下,包括两种容器运行时的实现: * 一种是内置的 dockershim,实现了 Docker 容器引擎的支持以及 CNI 网络插件(包括 kubenet)的支持; * 另一种是外部的容器运行时,用来支持 runc、containerd、gVisor 等外部容器运行时。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
Kubelet 通过 CRI 接口跟外部容器运行时交互,组件包括:
CRI Server:CRI gRPC server,监听在 unix socket 上; Streaming Server:提供 streaming API,包括 Exec、Attach、Port Forward; 容器和镜像的管理:比如拉取镜像、创建和启动容器等; CNI 网络插件的支持:用于给容器配置网络; 容器引擎管理:比如支持 runc 、containerd 或者支持多个容器引擎。- 1
- 2
- 3
- 4
- 5
Kubernetes 中的容器运行时按照不同的功能可以分为三个部分:
第一部分: kubelet 中容器运行时的管理,它通过 CRI 管理容器和镜像;
第二部分:容器运行时接口,它是 kubelet 与外部容器运行时的通信接口;
第三部分:具体的容器运行时实现,包括 kubelet 内置的 dockershim 以及外部的容器运行时(如 cri-o、cri-containerd、frakti等)
前面三个部分属于k8s CRI范畴,但其中不包括最终容器对应的真实后端,比如:containerd等
容器运行时的演进

容器运行时的演进可以分为三个阶段:
第一阶段
在 Kubernetes v1.5 之前,kubelet 内置了 Docker 和 rkt 的支持,并且通过 CNI 网络插件给它们配置容器网络。 这个阶段的用户如果需要自定义运行时的功能是比较痛苦的,需要修改 kubelet 的代码, 并且这些修改很有可能无法推到上游社区。 这就需要维护一个自己的 fork 分支,但维护和升级都非常麻烦。- 1
- 2
- 3
- 4
第二阶段
不同用户实现的容器运行时各有所长,许多用户都希望 Kubernetes 支持更多的运行时。 于是,从 v1.5 开始增加了 CRI 接口,通过容器运行时的抽象层消除了这些障碍, 使得无需修改 kubelet 就可以支持运行多种容器运行时。 CRI 接口包括了一组 Protocol Buffer、gRPC API 、用于 streaming 接口的库以及 用于调试和验证的一系列工具等。在此阶段,内置的 Docker 实现也逐步迁移到了 CRI 的接口下。 但此时 rkt 还未完全迁移,这是因为 rkt 迁移 CRI 的过程将在独立的 repository 完成,方便其维护和管理。- 1
- 2
- 3
- 4
- 5
- 6
- 7
第三阶段
从 v1.11 开始,Kubelet 内置的 rkt 代码删除,CNI 的实现迁移到 dockershim 之内。 这样,除了 Docker 之外,其他的容器运行时都通过 CRI 接入。 外部的容器运行时一般称为 CRI Shim,它除了实现 CRI 接口外,也要负责为容器配置网络。 推荐使用 CNI,因为这样可以支持社区内的众多网络插件,不过这也不是必需的, 网络插件只需要满足 Kubernetes 网络的基本假设即可, 即 IP-per-Pod、所有 Pod 和 Node 都可以直接通过 IP 相互访问。- 1
- 2
- 3
- 4
- 5
- 6
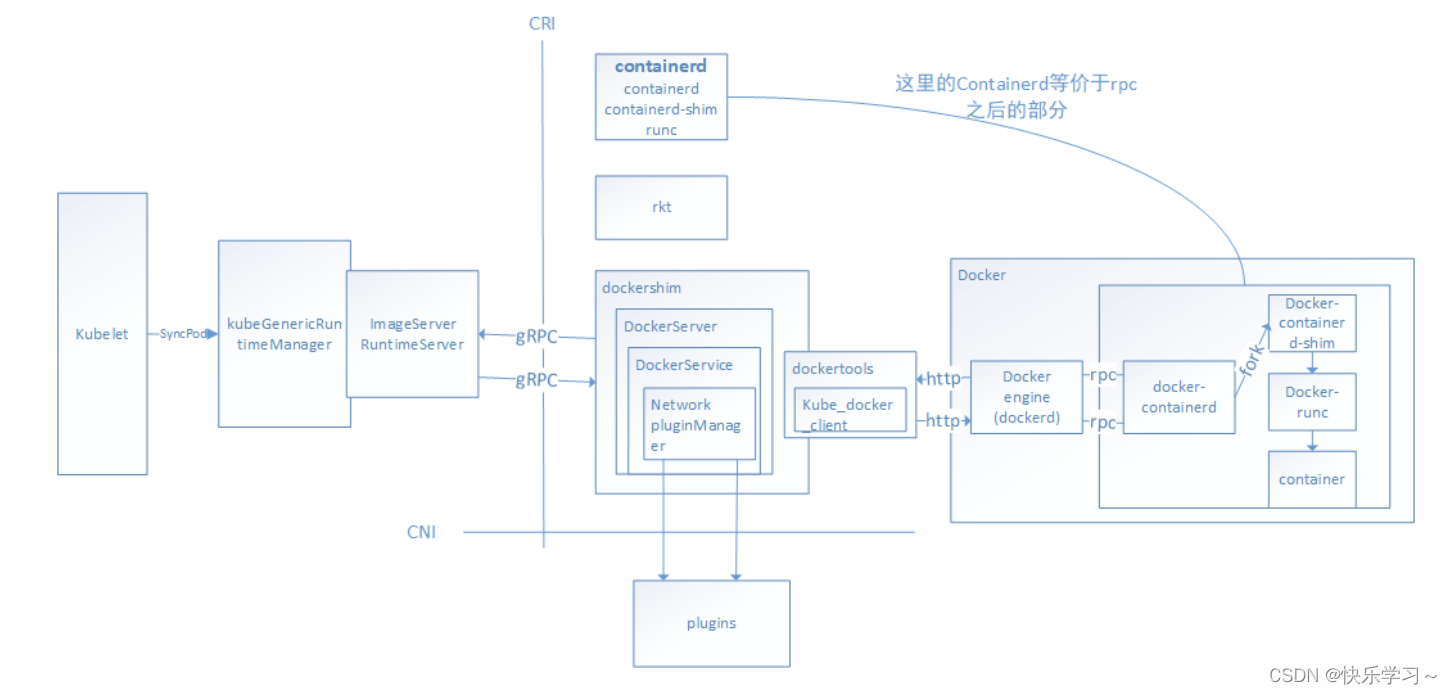
默认docker模式的调用关系
CRI接口规范
CRI 接口包括 RuntimeService 和 ImageService 两个服务,这两个服务可以在一个 gRPC server 中实现,也可以分开成两个独立服务。目前社区的很多运行时都是将其在一个 gRPC server 里面实现。
容器运行时接口(CRI)是一个用来扩展容器运行时的接口,它基于 gPRC,用户不需要关心内部通信逻辑,只需要实现定义的接口(包括 RuntimeService 和 ImageService)方可。
RuntimeService 负责管理 Pod 和容器的生命周期;
ImageService 负责管理镜像的生命周期;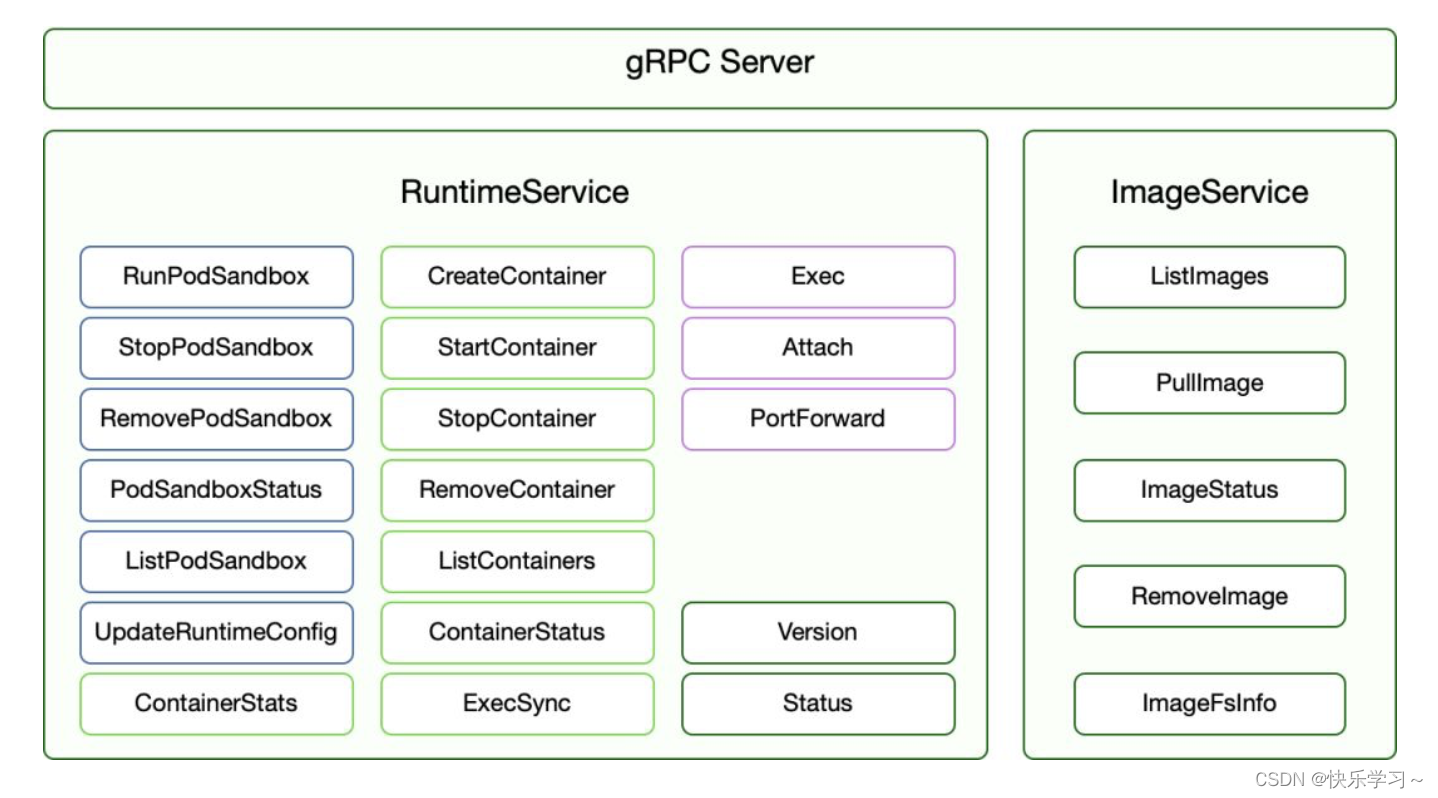
管理镜像的 ImageService 提供了 5 个接口:查询镜像列表; 拉取镜像到本地; 查询镜像状态; 删除本地镜像; 查询镜像占用空间等。 这些都很容易映射到 Docker API 或者 CLI 上面。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
RuntimeService 则提供了更多的接口,按照功能可以划分为四组:
PodSandbox 的管理接口:PodSandbox 是对 Kubernete Pod 的抽象,用来给容器提供一个隔离的环境 (比如挂载到相同的 CGroup 下面),并提供网络等共享的命名空间。 PodSandbox 通常对应到一个 Pause 容器或者一台虚拟机; Container 的管理接口:在指定的 PodSandbox 中创建、启动、停止和删除容器; Streaming API 接口:包括 Exec、Attach 和 PortForward 等三个和容器进行数据交互的接口, 这三个接口返回的是运行时 Streaming Server 的 URL,而不是直接跟容器交互; 状态接口:包括查询 API 版本和查询运行时状态。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Streaming API
Streaming API 用于客户端与容器进行交互,包括 Exec、PortForward 和 Attach 等三个接口。 kubelet 内置的 Docker 通过 nsenter、socat 等方法来支持这些特性,但它们不一定适用于其他的运行时, 也不支持 Linux 之外的其他平台。 因而,CRI 也显式定义了这些 API,并且要求容器运行时返回一个 Streaming Server 的 URL 以便 kubelet 重定向 API Server 发送过来的流式请求。 因为所有容器的流式请求都会经过 kubelet,这可能会给节点的网络流量带来瓶颈, 因而 CRI 要求容器运行时启动一个对应请求的单独的流服务器,将地址返回给 kubelet。 kubelet 将这个信息再返回给 Kubernetes API Server,它会直接打开与运行时提供的服务器相连的流连接, 并通过它跟客户端连通。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

这样一个完整的 Exec 流程就如上图所示,分为多个阶段:客户端 kubectl exec -i -t ...; 1、kube-apiserver 向 kubelet 发送流式请求 /exec/; 2、kubelet 通过 CRI 接口向 CRI Shim 请求 Exec 的 URL; 3、CRI Shim 向 kubelet 返回 Exec URL; 4、kubelet 向 kube-apiserver 返回重定向的响应; 5、kube-apiserver 重定向流式请求到 Exec URL,然后将 CRI Shim 内部的 Streaming Server 跟 kube-apiserver 进行数据交互,完成 Exec 的请求和响应。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

基于 CRI 接口的容器运行时通常称为 CRI shim, 这是一个 gRPC Server,监听在本地的 unix socket 上;而 kubelet 作为 gRPC 的客户端来调用 CRI 接口。另外,外部容器运行时需要自己负责管理容器的网络,推荐使用 CNI,使它与 Kubernetes 的网络模型保持一致。
CRI 的推出为容器社区带来了新的繁荣,cri-o、frakti、cri-containerd 等一些列的容器运行时为不同场景而生:
cri-containerd ——基于 containerd 的容器运行时; cri-o ——基于 OCI 的容器运行时; frakti ——基于虚拟化的容器运行时;- 1
- 2
- 3
当使用 CRI 运行时,需要配置 kubelet 的 --container-runtime 参数为 remote,并设置 --container-runtime-endpoint 为监听的 unix socket 位置(Windows 上面为 tcp 端口)。
CRI shim
CRI shim是比如dockershim或一些容器引擎自己实现的cri服务则接收client的请求,在容器引擎和运行时上操作容器、镜像和容器网络等宿主资源。
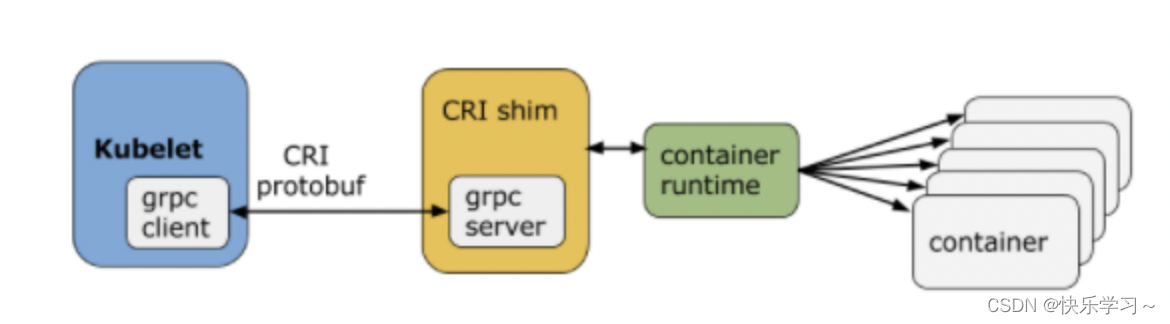
CRI为Kubelet和container runtime直接的通信设计了一对gRPC接口,Kubelet通过gRPC与CRI shim通信,CRI shim进而控制runtime操纵容器。CRI shim是一个接口转换层,我们熟知的docker-shim即为它的实现。
在Docker中,dockershim是独立的进程,而在有些CRI runtime中则是内嵌的代码模块。
以K8s 的代码为例,Kubelet启动时,在NewMainKubelet()函数内会判断默认使用的CRI runtime,如果是Docker,则为dockershim创建CRI shim的gRPC server(dockershim.NewDockerService())并启动。
Kubelet内置了CRI的gRPC client,Kubelet对CRI runtime的调用,就被转换成对CRI shim的gRPC请求。
容器运行时实例

细剖kubelet通过CRI与docker的交互
目前 dockershim 的代码其实是内嵌在 Kubelet 中的,所以接收调用的凑巧就是 Kubelet 进程;

当kubelet要创建一个容器时,需要以下几步:1、Kubelet 通过 CRI 接口(gRPC)调用 dockershim,请求创建一个容器。 CRI 即容器运行时接口(Container Runtime Interface),这一步中,Kubelet 可以视作一个简单的 CRI Client,而 dockershim 就是接收请求的 Server。 目前 dockershim 的代码其实是内嵌在 Kubelet 中的,所以接收调用的凑巧就是 Kubelet 进程; 2、dockershim 收到请求后,转化成 Docker Daemon 能识别的格式,发到 Docker Daemon 上请求创建一个容器。 3、Docker Daemon 早在 1.12 版本中就已经将针对容器的操作移到另一个守护进程——containerd 中了, 因此 Docker Daemon 仍然不能帮我们创建容器,而是要请求 containerd 创建一个容器; 4、containerd 收到请求后,并不会自己直接去操作容器,而是创建一个叫做 containerd-shim 的进程, 让 containerd-shim 去操作容器。这是因为容器进程需要一个父进程来做诸如收集状态, 维持 stdin 等 fd 打开等工作。 而假如这个父进程就是 containerd,那每次 containerd 挂掉或升级,整个宿主机上所有的容器都得退出了。 而引入了 containerd-shim 就规避了这个问题(containerd 和 shim 并不是父子进程关系); 5、我们知道创建容器需要做一些设置 namespaces 和 cgroups,挂载 root filesystem 等等操作, 而这些事该怎么做已经有了公开的规范了,那就是 OCI(Open Container Initiative,开放容器标准)。 它的一个参考实现叫做 runC。于是,containerd-shim 在这一步需要调用 runC 这个命令行工具,来启动容器; 6、runC 启动完容器后本身会直接退出,containerd-shim 则会成为容器进程的父进程,负责收集容器进程的状态,上报给 containerd,并在容器中 pid 为 1 的进程退出后接管容器中的子进程进行清理,确保不会出现僵尸进程。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
这个过程Docker Daemon 和 dockershim并没有做什么,Kubelet 为啥不直接调用 containerd 呢?
当然可以,先看下现在的架构为什么如此繁杂容器历史
早期的k8s runtime架构,远没这么复杂,kubelet创建容器,直接调用docker daemon,docker daemon自己调用libcontainer就把容器运行起来。
运行时标准不能被 Docker 一家公司控制,于是就撺掇着搞了开放容器标准 OCI。
Docker 则把 libcontainer 封装了一下,变成 runC 捐献出来作为 OCI 的参考实现。
再接下来就是 rkt希望 Kubernetes 原生支持 rkt 作为运行时,而且 PR 还真的合进去了。
这么搞可不行,今天能有 rkt,明天就能有更多出来,这么搞下去整天搞兼容性的 bug 就够呛。
于是乎,Kubernetes 1.5 推出了 CRI 机制,即容器运行时接口(Container Runtime Interface),Kubernetes 告诉大家,想做 Runtime实现这个接口就成,成功反客为主。
不过 CRI 本身只是 Kubernetes 推的一个标准,容器运行时当然不能说我跟 Kubernetes 绑死了只提供 CRI 接口,于是就有了 shim(垫片)这个说法,一个 shim 的职责就是作为 Adapter 将各种容器运行时本身的接口适配到 Kubernetes 的 CRI 接口上。
接下来就是 Docker 要搞 Swarm 进军 PaaS 市场,于是做了个架构切分,把容器操作都移动到一个单独的 Daemon 进程 containerd 中去,让 Docker Daemon 专门负责上层的封装编排。可惜 Swarm 在 Kubernetes 面前实在是不够打,惨败之后 Docker 公司就把 containerd 项目捐给 CNCF 缩回去安心搞 Docker 企业版了。
最后就是我们在上一张图里看到的,尽管现在已经有 CRI-O,containerd-plugin 这样更精简轻量的 Runtime 架构,dockershim 这一套作为经受了最多生产环境考验的方案,迄今为止仍是 Kubernetes 默认的 Runtime 实现。
dockershim
CRI 是K8S 定义的一套容器运行时接口,基于gRPC通讯,但是docker不是基于CRI的,因此 kubelet 又把docker 封装了一层,搞了一个所谓的shim,也即是dockershim的东西,dockershim 作为一个实现了CRI 接口的gRPC服务器,供 kubelet 使用。这样的过程其实就是,kubelet作为客户端 通过gRPC调用dockershim服务器,dockershim 内部又通过docker客户端走 http 调用 docker daemon api,多走了一次通讯的开销。下图是目前默认使用docker作为容器引擎的时候,调用过程。

也就是说,为了做一次容器操作,进行了两次rpc,一次http,光从这个调用链来看,就处理的不够优雅。CNI是由kubelet中的dockershim调用的
初始化docker runtime的时候,会将CNI信息配置进去,以便后续dockershim调用CNI
func NewKubeletFlags() *KubeletFlags { remoteRuntimeEndpoint := "" if runtime.GOOS == "linux" { remoteRuntimeEndpoint = "unix:///var/run/dockershim.sock" } else if runtime.GOOS == "windows" { remoteRuntimeEndpoint = "npipe:./pipe/dockershim" } return &KubeletFlags{ EnableServer: true, ContainerRuntimeOptions: *NewContainerRuntimeOptions(), CertDirectory: "/var/lib/kubelet/pki", RootDirectory: defaultRootDir, MasterServiceNamespace: metav1.NamespaceDefault, MaxContainerCount: -1, MaxPerPodContainerCount: 1, MinimumGCAge: metav1.Duration{Duration: 0}, NonMasqueradeCIDR: "10.0.0.0/8", RegisterSchedulable: true, ExperimentalKernelMemcgNotification: false, RemoteRuntimeEndpoint: remoteRuntimeEndpoint, NodeLabels: make(map[string]string), VolumePluginDir: "/usr/libexec/kubernetes/kubelet-plugins/volume/exec/", RegisterNode: true, SeccompProfileRoot: filepath.Join(defaultRootDir, "seccomp"), // prior to the introduction of this flag, there was a hardcoded cap of 50 images NodeStatusMaxImages: 50, EnableCAdvisorJSONEndpoints: false, } } func NewContainerRuntimeOptions() *config.ContainerRuntimeOptions { dockerEndpoint := "" if runtime.GOOS != "windows" { dockerEndpoint = "unix:///var/run/docker.sock" } return &config.ContainerRuntimeOptions{ ContainerRuntime: kubetypes.DockerContainerRuntime, RedirectContainerStreaming: false, DockerEndpoint: dockerEndpoint, DockershimRootDirectory: "/var/lib/dockershim", PodSandboxImage: defaultPodSandboxImage, ImagePullProgressDeadline: metav1.Duration{Duration: 1 * time.Minute}, ExperimentalDockershim: false, // 这里进行了CNI的配置,以便后续dockershim调用CNI CNIBinDir: "/opt/cni/bin", CNIConfDir: "/etc/cni/net.d", CNICacheDir: "/var/lib/cni/cache", } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
使用containerd代替dockershim
containerd 其实也经历了一些演变,早期 containerd 1.0 的调用链其实还是很长,和docker一样也需要一个实现了CRI的进程来负责和kubelet通讯,然后再和containerd通讯,但是到了 containerd 1.1 , containerd 将cri 做成了插件程序集成到了自己内部,这样就彻底减少了调用链的长度,一次 rpc 就可以操控运行时了。

综合创建pod的过程

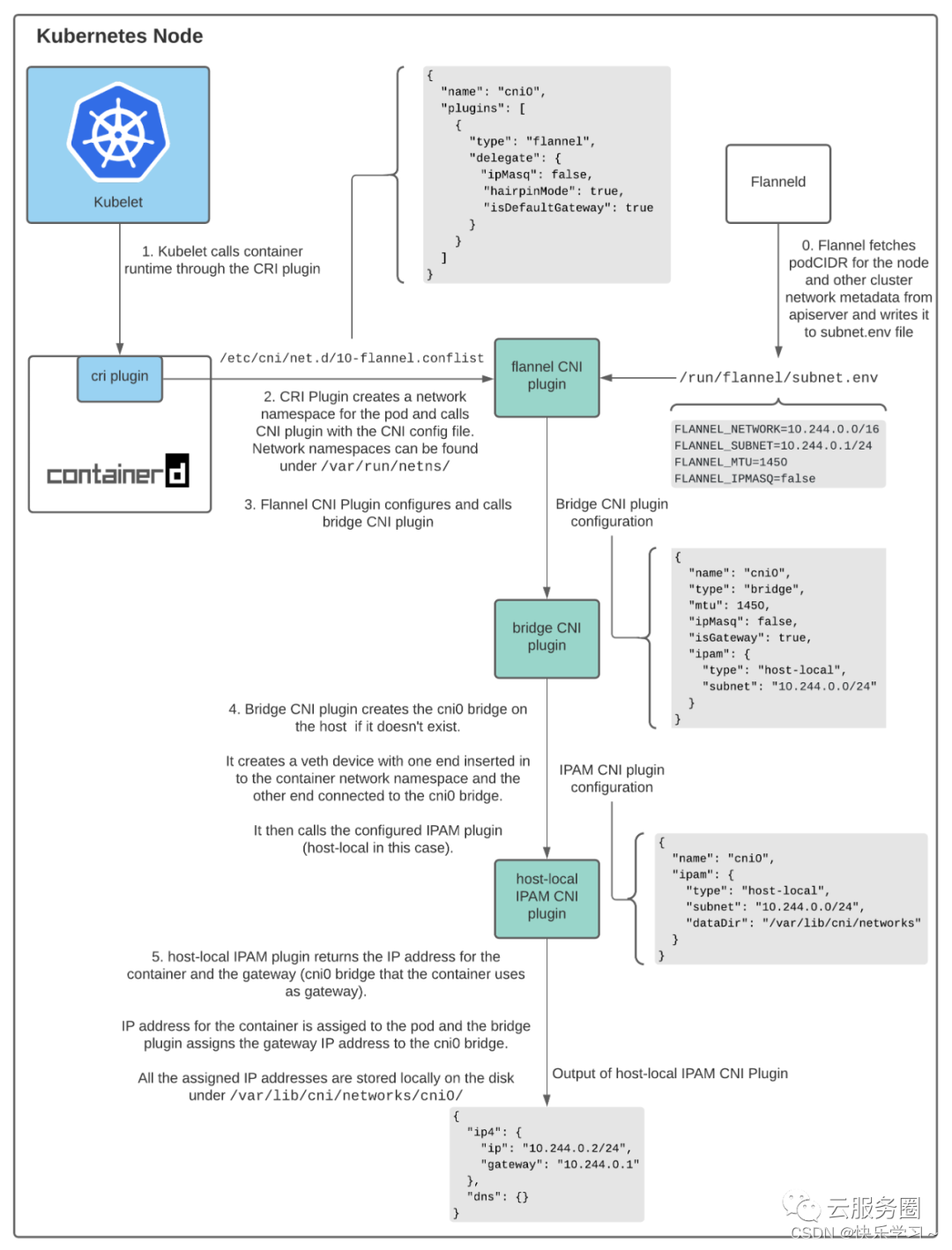
-
相关阅读:
apolloconfig分布式部署
Java-序列化和反序列化
门户网站还有存在的意义吗?
Linux-进程调度(CFS)
java8 实现递归查询
装机必备的浏览器推荐,干净好用,选这4款不会出错
Python攻城师的成长————Django框架(django操作session、 CBV添加装饰器的三种方式 、django中间件、 csrf跨站请求伪造)
【编程题】【Scratch二级】2022.09 绘制图形
MySQL 创建和管理表
Mysql查询——根据字段值自定义排序
- 原文地址:https://blog.csdn.net/qq_43684922/article/details/126191657
