-
tkinter-TinUI-xml实战(7)PDF分页与合并
引言
PDF格式文件作为一种使用广泛的文件,自诞生之始就被很多人使用。因为其各种原因,PDF成为几乎所有正式文件首选发布格式。无论是学生、社会机构、文本报告等等,都会使用的PDF文件。
其中,我们可能会涉及到一些问题:
-
文件由很多页,但是自己需要获取提交的就那几页(比如学校的志愿时数公布文件,我的名字就在其中一页,每一页都有正式题目和盖章)
-
有若干个PDF文件需要合并(比如我的英语电子版作业。。。)
这就要求我们去找能够进行PDF合并和分页的工具了。
一些客户端软件我倒是没看见几个可以免费的,线上工具,我就在使用ILovePDF。但是ILovePDF有一个重大的问题,不是有价格方案,对我来说免费额度够用,而是网络连接不稳定。
结果比对
本篇文章写于“成功”后,对比了一下,本次编写的PDF工具合并并输出一个23MB的PDF文件用了不到2秒,而使用ILovePDF使用了近1分钟。
依赖库
本次需要用到
PyPDF2库。一个完全免费开源、持续更新、高效的PDF处理库。为作者以及开发团队点赞!!!
声明
本项目属于作者原创。借鉴了GitHub/TinUI上的
tuxml.py,翻版必究,但可以自行添加功能代码。本项目使用的TinUI为我开源并维护在GitHub上的主文件——TinUI.py。当然,使用PYPI中下载安装的tinui也可以。
文件结构
- pdf-fg.xml - 分页界面
- pdf-hb.xml - 合并界面
- PDF分割.py - 分页主程序
- PDF合并.py - 合并主程序
- tinui.py - TinUI核心支持
核心代码
本次因为演示原因,分页主程序和合并主程序是分开来写的。
PDF文件的操作不是本篇文章的重点。关于PyPDF2的相关API,网络上有很多。
分页程序
界面设计
还记得我们之前完成的TinUIXml编辑器吗?现在可以拿出来用了。否则,光纯代码写TinUI界面就够我写十分钟了。使用TinUIXml编辑器后,不到三分钟就搞定了xml文件和IDO代码。
这是设计过程中的一张截图。
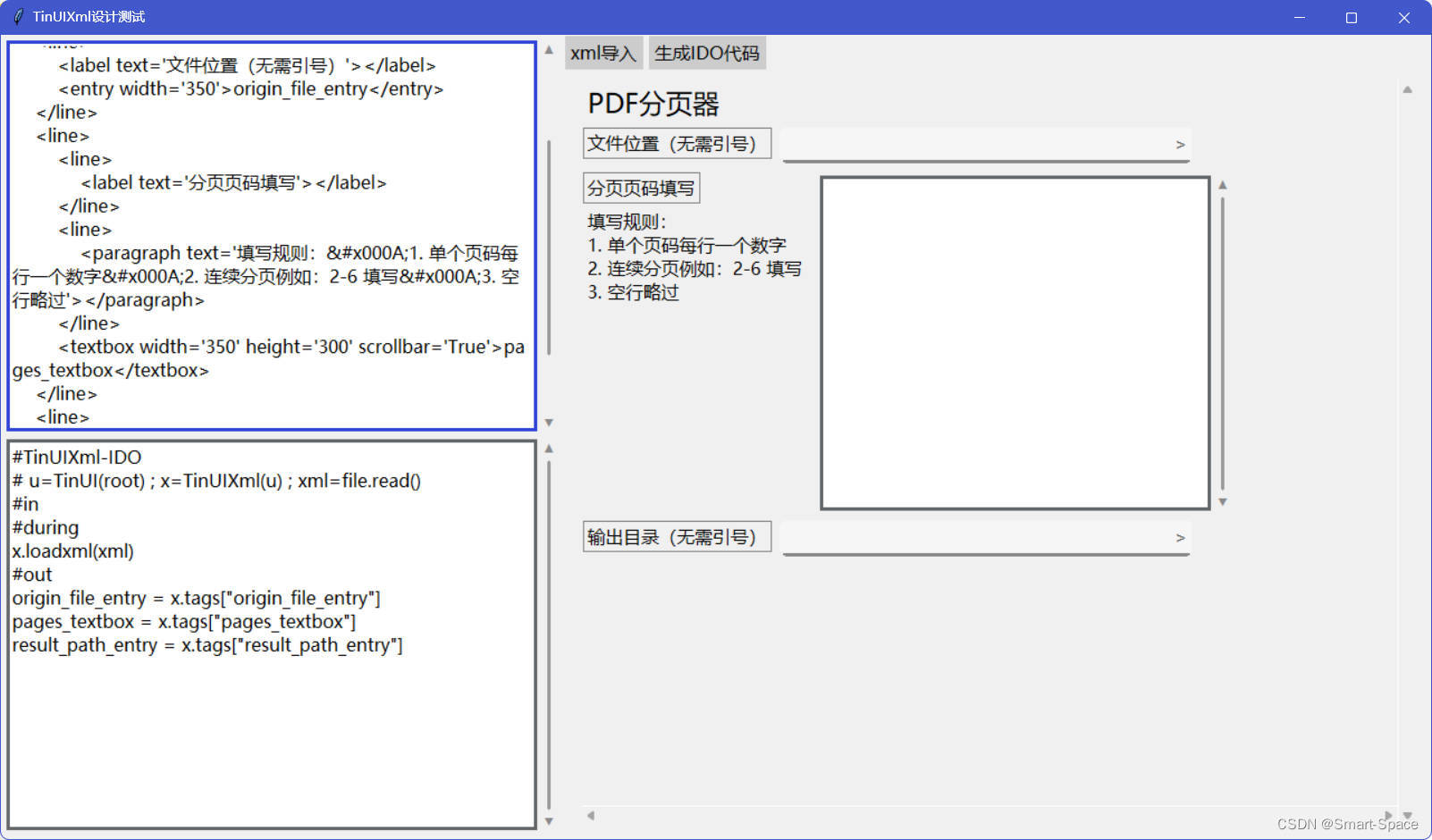
这样修改后可以立刻检查UI界面,并且完成后可以自动生成IDO部分代码,真的是超方便。
我自己手动写IDO其实也很烦躁。。。
pdf-fg.xml:
<tinui> <line> <title text='PDF分页器'>title> line> <line> <label text='文件位置(无需引号)'>label> <entry width='350'>origin_file_entryentry> line> <line> <line> <label text='分页页码填写'>label> line> <line> <paragraph text='填写规则: 1. 单个页码每行一个数字 2. 连续分页例如:2-6 填写 3. 空行略过'>paragraph> line> <textbox width='350' height='300' scrollbar='True'>pages_textboxtextbox> line> <line> <label text='输出目录(无需引号)'>label> <entry width='350'>result_path_entryentry> line> <line> <button text='开始分页PDF' command='self.funcs["start"]'>button> <paragraph text='当前状态:'>paragraph> <paragraph text='空闲'>stateparagraph> line> tinui>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
源文件代码
from tkinter import Tk,Frame import os from tinui import * from PyPDF2 import PdfFileReader, PdfFileWriter def start(*e): restate('分页中……') u.update() ofile=origin_file_entry[0].get() fname=os.path.split(os.path.splitext(ofile)[0])[1] rpath=result_path_entry[0].get() if rpath[-1] not in ('\\','/'): rpath+='\\' pages_list=pages_textbox[0].get(1.0,'end').split('\n') pagenum=list() for i in pages_list: if i=='': continue if '-' in i: start,end=i.split('-') start=int(start) end=int(end)+1 for p in range(start,end): pagenum.append(p) else: pagenum.append(int(i)) pdfreader=PdfFileReader(ofile) pdfwriter=PdfFileWriter() for page in pagenum: pdfwriter.addPage(pdfreader.getPage(page-1)) with open(rpath+fname+'-分页结果.pdf','wb') as out: pdfwriter.write(out) restate('已生成 '+fname+'-分页结果.pdf') u.after(5000,lambda:restate()) def restate(text='空闲'): u.itemconfig(state,text=text) pages_list=[]#输入框内容 ofile=None rpath=None root=Tk() root.title('PDF分割') root.geometry('600x500') frame=Frame(root) frame.pack(fill='y',side='left') u=BasicTinUI(frame,height=580,width=580) u.pack(fill='both',expand=True) x=TinUIXml(u) #in x.funcs['start']=start #during with open('pdf-fg.xml',mode='r',encoding='utf-8') as f: xml=f.read() x.loadxml(xml) #out origin_file_entry = x.tags["origin_file_entry"] pages_textbox = x.tags["pages_textbox"] result_path_entry = x.tags["result_path_entry"] state = x.tags["state"] root.mainloop()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
最终效果
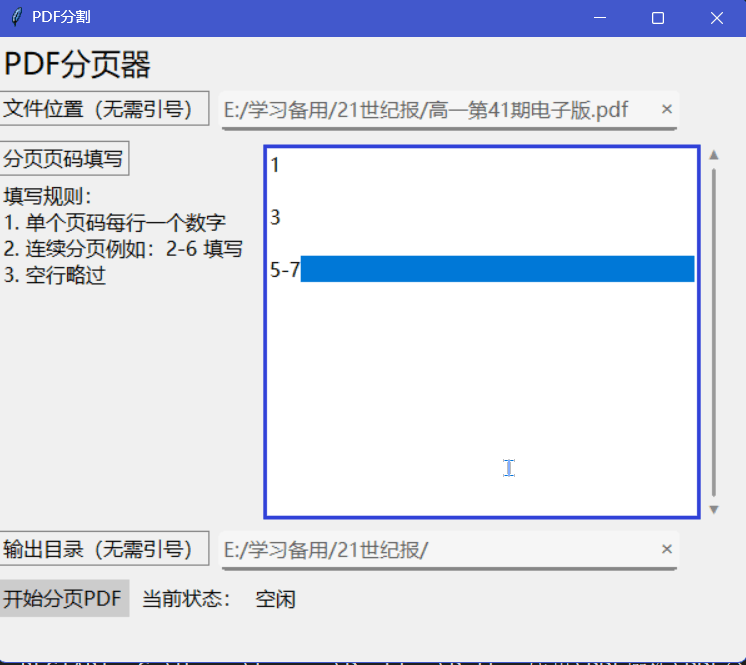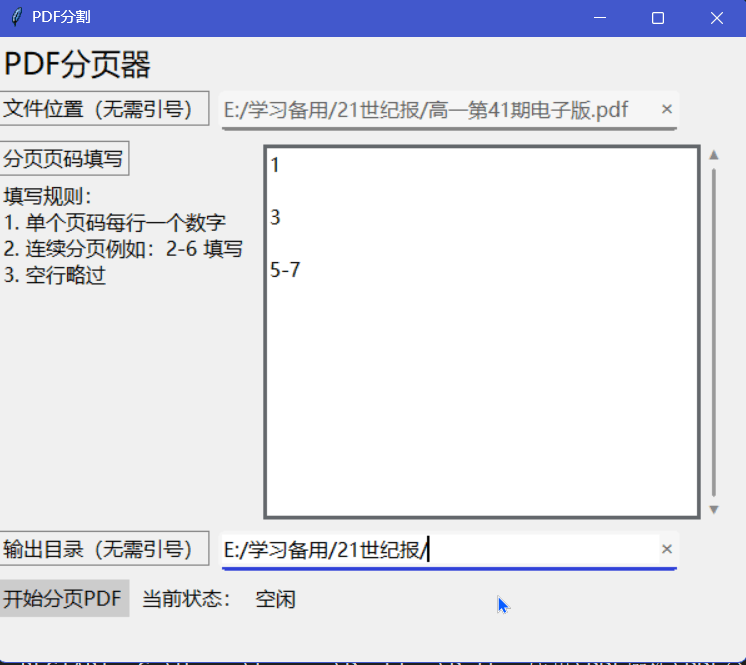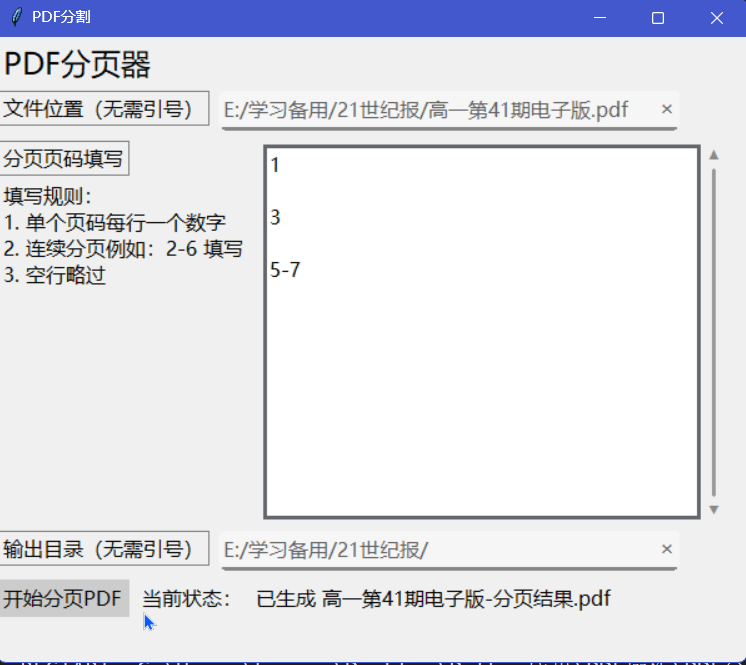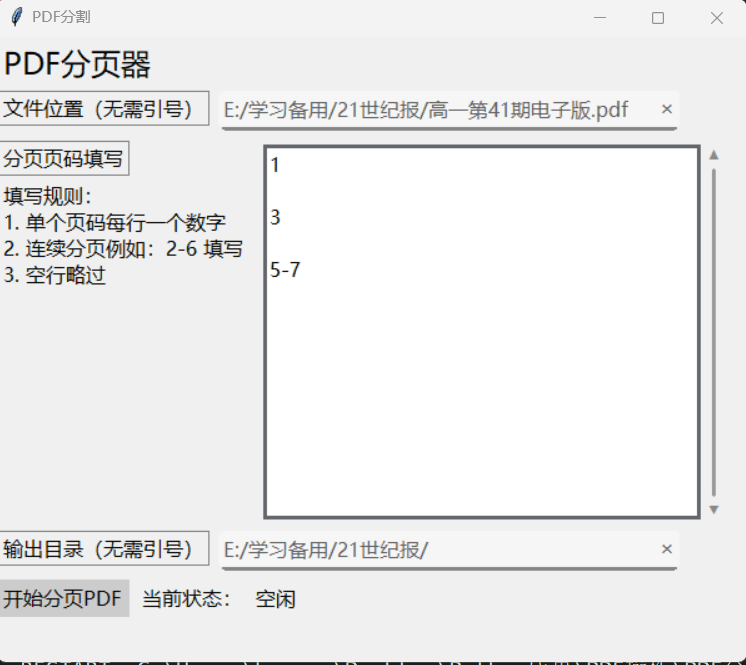
源PDF文件:

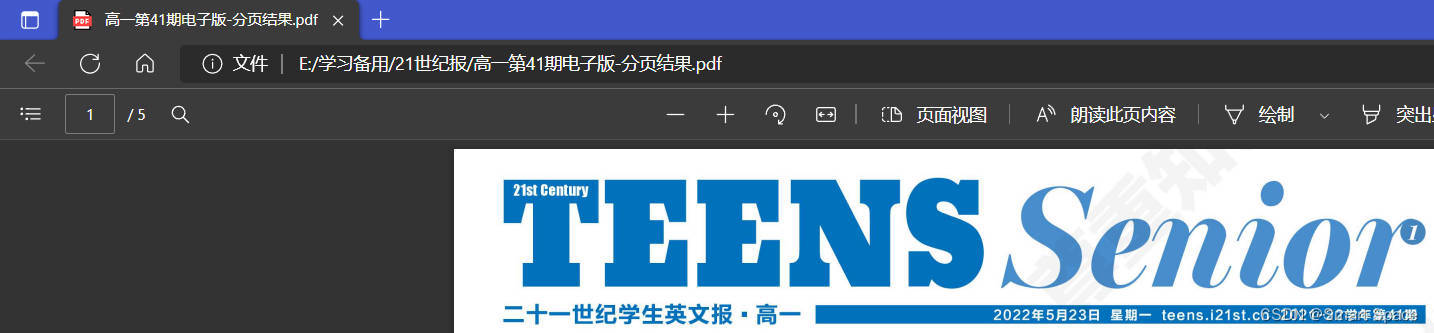
结果:
合并程序
界面设计
<tinui> <line> <title text='PDF合并器'>title> line> <line> <line> <label text='文件位置填写'>label> line> <line> <paragraph text='填写规则: 1. 每行一个文件路径 2. 空行略过'>paragraph> line> <textbox width='350' height='300' scrollbar='True'>pages_textboxtextbox> line> <line> <label text='输出目录(无需引号)'>label> <entry width='350'>result_path_entryentry> line> <line> <button text='开始合并PDF' command='self.funcs["start"]'>button> <paragraph text='当前状态:'>paragraph> <paragraph text='空闲'>stateparagraph> line> tinui>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
源文件代码
from tkinter import Tk,Frame import os from tinui import * from PyPDF2 import PdfFileReader, PdfFileWriter, PdfMerger def start(*e): restate('合并中……') u.update() files_list=pages_textbox[0].get(1.0,'end').split('\n') files=list() for i in files_list: if i=='': continue else: files.append(i) fname=os.path.split(os.path.splitext(files[0])[0])[1]#取第一个文件名称 rpath=result_path_entry[0].get() if rpath[-1] not in ('\\','/'): rpath+='\\' merger=PdfMerger() for pdf in files: merger.append(pdf) merger.write(rpath+fname+'-合并结果.pdf') merger.close() restate('已生成 '+fname+'-分页结果.pdf') u.after(5000,lambda:restate()) def restate(text='空闲'): u.itemconfig(state,text=text) files_list=[]#输入框内容 rpath=None root=Tk() root.title('PDF合并') root.geometry('600x500') frame=Frame(root) frame.pack(fill='y',side='left') u=BasicTinUI(frame,height=580,width=580) u.pack(fill='both',expand=True) x=TinUIXml(u) #in x.funcs["start"] = start #during with open('pdf-hb.xml',mode='r',encoding='utf-8') as f: xml=f.read() x.loadxml(xml) #out pages_textbox = x.tags["pages_textbox"] result_path_entry = x.tags["result_path_entry"] state = x.tags["state"]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
最终效果
结语
现在,可以拿着写好的两个工具自己玩一会了,以后也用不找一要分割或合并PDF就去网络上找东西。本机够用的,也就没必要大费周章了。
这次有体验了一次使用TinUIXml的快乐。
🔆tkinter创新🔆
-
-
相关阅读:
linux 安装 Anaconda3
基于Java的药品商城管理系统设计与实现(源码+lw+部署文档+讲解等)
c++中的模板(8) -- 模板和友元函数
(2023|ICLR,检索引导,交叉引导,EntityDrawBench)Re-Imagen:检索增强的文本到图像生成器
栈的应用(C++,进制转化、括号匹配)
php fpdf使用记录
【SpringBoot】内容协商机制
Linux下 mtrace工具排查内存泄露问题
大神之路-起始篇 | 第1章.计算机科学导论之【基础绪论】学习笔记
Win10/Win11日历提醒与手机日历同步互联
- 原文地址:https://blog.csdn.net/tinga_kilin/article/details/125889317


