-
Chapter 13 贝叶斯网络实践
1 朴素贝叶斯的推导、应用及分类
1.1 朴素贝叶斯的推导
朴素贝叶斯是基于“特征之间是独立的”这一朴素假设(即:一个特征出现的概率,与其他特征独立),应用贝叶斯定理的监督学习算法。
对于给定的特征向量
 ,类别
,类别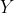 的概率可以根据贝叶斯公式得到:
的概率可以根据贝叶斯公式得到:
使用朴素的独立性假设:

在给定样本的前提下,
 是常数:
是常数: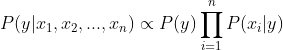
从而

1.2 朴素贝叶斯的应用
现实生活中朴素贝叶斯算法应用广泛,如文本分类,垃圾邮件的分类,信用评估,钓鱼网站检测等等。
1.3 朴素贝叶斯分类
- 高斯朴素贝叶斯——
 ,参数使用极大似然估计(MLE)即可。
,参数使用极大似然估计(MLE)即可。 - 多项分布朴素贝叶斯——对于每个类别,参数为
 ,其中
,其中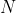 为特征的数目,
为特征的数目, 的概率为
的概率为 。参数
。参数 使用极大似然估计的结果为:
使用极大似然估计的结果为: ,
, 。假定训练集为T,则有
。假定训练集为T,则有 ,其中,
,其中, 称为Laplace平滑;
称为Laplace平滑; 称为Lidstone平滑。
称为Lidstone平滑。
2 文本数据的处理流程
(1)爬取数据
(2)对文本进行分词,可分为中文分词和英文分词,英文分词可以利用空格完成,中文分词可以利用jieba分词,参考https://blog.csdn.net/qwertyuiop0208/article/details/125251521中的文本特征抽取方法一。
(3)对数据进行预处理(包括数据清洗和校正等等)参考https://blog.csdn.net/qwertyuiop0208/article/details/125926133
(4)对数据进行标准化
(5)经过TF-IDF或者Word2vec等特征提取的方法将字符串转化为向量。
(6)用机器学习等算法建模和模型评估。
3 使用TF-IDF得到文本特征
如果一个词或短语在某一篇文章中出现的概率很高,并且在其它文章中很少出现,则认为该词或短语具有很好的类别区分能力,适合用来分类。TF-IDF用以评估一个词语对于一个文件或者一个语料库中的其中一份文件的重要程度。
详细操作见:https://blog.csdn.net/qwertyuiop0208/article/details/125251521中的文本特征抽取方法二。
4 Word2vec的使用
本质是建立了3层神经网络,将所有词都映射为一定长度的向量;取一定的窗口范围作为当前词的淋浴,估计窗口内的词。其包含两种算法,分别是skip-gram和CBOW,它们的最大区别是skip-gram是通过中心词去预测中心词周围的词,而CBOW是通过周围的词去预测中心词。
- 高斯朴素贝叶斯——
-
相关阅读:
PyTorch 加载 Mask R-CNN 预训练模型并 fine-tuning
智云通CRM:客户说“你家东西太贵了”,如何让客户觉得物超所值?
Java面试题以及答案(三)多线程(必会)
神经网络-文本-图像-音频-视频基础知识
Linux:文件解压、复制和移动的若干坑
去面试了几家BATJ等N家互联网大厂
sealos一键部署K8S环境(sealos3.0时代教程过时了,目前已经4.0了,请移步使用Sealos一键安装K8S)
暑假加餐|有钱人和你想的不一样(第8天)+多目标金鹰优化算法(Matlab代码实现)
Java项目:springboot医院管理系统
函数8:高阶函数
- 原文地址:https://blog.csdn.net/qwertyuiop0208/article/details/126186844