-
4.爬虫之Scrapy框使用2
1. 数据解析
1.1 第三方模块解析
import scrapy class ChoutiSpider(scrapy.Spider): name = 'chouti' allowed_domains = ['dig.chouti.com'] start_urls = ['http://dig.chouti.com/'] def parse(self, response): from bs4 import BeautifulSoup soup = BeautifulSoup(response.text, 'lxml') # 获取新闻列表 div_list = soup.find_all(class_='link-item') for div in div_list: # 避免广告 try: # 标题及内容 title = div.find(class_='link-title').text # 链接 url = div.find(class_='link-title').attrs.get('href') print(f""" 标题: {title} 链接: {url} """) except Exception as e: continue- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
1.2 自带库解析
自带xpath 与 css选择器 解析- 1
import scrapy class ChoutiSpider(scrapy.Spider): name = 'chouti' allowed_domains = ['dig.chouti.com'] start_urls = ['http://dig.chouti.com/'] def parse(self, response): # 自带xpath 与 css选择器 title_list1 = response.xpath('//a[contains(@class, "link-title")]') print(len(title_list1)) # 25 title_list2 = response.css('.link-title') print(len(title_list2)) # 25- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
1. 获取文本信息
xpath: .../text() css: (会转为xpath) response.css("css查找标签规则::text") 上述两个都会得到一个选择器列表对象, 可能存放多个选择器对象, 选择器对象携带文本数据. 选择器列表对象.extract() 得到所有选择器对象携带信息, 值是一个列表套字符串. 选择器列表对象.extract_first() 获取第一个选择器对象的携带信息, 等同于对象.extract()[0]. 匹配到的对象有多个, 那么列表中就有多个字符串.- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

import scrapy class ChoutiSpider(scrapy.Spider): name = 'chouti' allowed_domains = ['dig.chouti.com'] start_urls = ['http://dig.chouti.com/'] def parse(self, response): # title_list1匹配到多个对象 title_list1 = response.xpath('//a[contains(@class, "link-title")]/text()') print(title_list1) """ [, ...] """ title_list2 = response.css(".link-title") print(title_list2) """ [# 获取每个对象的文本信息 title_list3 = response.xpath('//a[contains(@class, "link-title")]/text()').extract() print(title_list3) """ [ '新闻1的内容', '新闻2的内容', ...] """ # 获取第一个标签对象的文本字符串 title_list4 = response.xpath('//a[contains(@class, "link-title")]/text()').extract_first() print(title_list4) """ 新闻1的内容, """ # 获取第一个标签对象的文本字符串 title_list5 = response.css(".link-title::text").extract_first() print(title_list5) """ 新闻1的内容, """ - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
2. 获取属性
xpath获取属性: .../@属性名 css获取属性: ::attr(属性名) 得到一个选择器对象, 携带属性数据. 上述两个都会得到一个选择器列表对象, 可能存在多个选择器对象, 选择器对象携带属性数据. 通过extract() 得到所有选择器对象携带信息, 值是一个列表套字符串. extract_first() 获取第一个选择器对象的携带信息, 等同于对象.extract()[0].- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

import scrapy class ChoutiSpider(scrapy.Spider): name = 'chouti' allowed_domains = ['dig.chouti.com'] start_urls = ['http://dig.chouti.com/'] def parse(self, response): title_list1 = response.xpath('//a[contains(@class, "link-title")]/@href') print(title_list1) print(title_list1.extract_first()) """, ... ] url地址 """ title_list2 = response.css(".link-title::attr(href)") print(title_list2) print(title_list2.extract_first()) """, ...] url地址 """ - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
2. 配置文件属性说明
2.1 全局配置user-Agent
setting.py配置文件中USER_AGENT属性设置默认的user-Agent. (/是换行显示) USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) ' \ 'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.134 Safari/537.36 Edg/103.0.1264.71'- 1
- 2
- 3
- 4
2.2 日志级别
setting.py配置文件中LOG_LEVEL属性设置日志级别. LOG_LEVEL = 'ERROR' 设置之后再不带运行日志执行, 程序出现问题会在终端抛出异常信息.- 1
- 2
- 3
- 4
- 5
3. 数据持久化
持久化: 将数据保存到计算机硬盘.- 1
3.1 保存到文件
将爬取的数据保存到文件, 支持 .csv .json .jsonlines .jl . xml . marshal .pickle 格式.- 1
parser方法返回列表套字典形式的参数. 参数形式: return [{'key': 'value', ...}, ...] 通过命令启动爬虫程序: scrapy crawl 爬虫程序名 -o 输出文件名.后缀 (-o --> out)- 1
- 2
- 3
- 4
- 5
- 6
# chouti.py import scrapy class ChoutiSpider(scrapy.Spider): name = 'chouti' allowed_domains = ['dig.chouti.com'] start_urls = ['http://dig.chouti.com/'] def parse(self, response): # 获取新闻的div标签, 目前一页25条 div_list = response.xpath('//div[contains(@class, "link-item")]') # 定义放回的列表 res_list = [] # 遍历每条新闻标签 for div in div_list: # 获取新闻 content = div.css('.link-title::text').extract_first() # 获取新闻链接 url = div.css('.link-title::attr(href)').extract_first() # 获取封面 phone = div.css('.image-scale::attr(src)').extract_first() # 将每一条新闻的信息封装成一个字典, 在添加到列表中 res_list.append({'content': content, 'url': url, 'phone': phone}) # 将数据返回 return res_list- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
在获取到div标签对象的时候, 使用css编辑器可以直接从当前的div对象查找. 如果使用xpath解析器的话, 在前面加上., 从当前div对象开始查找, 不然就是全局查找了.- 1
- 2
执行命令: scrapy crawl chouti -o chouti.csv 在项目目录下生成一个文件, .scv文件可以使用excel工具打开.- 1
- 2
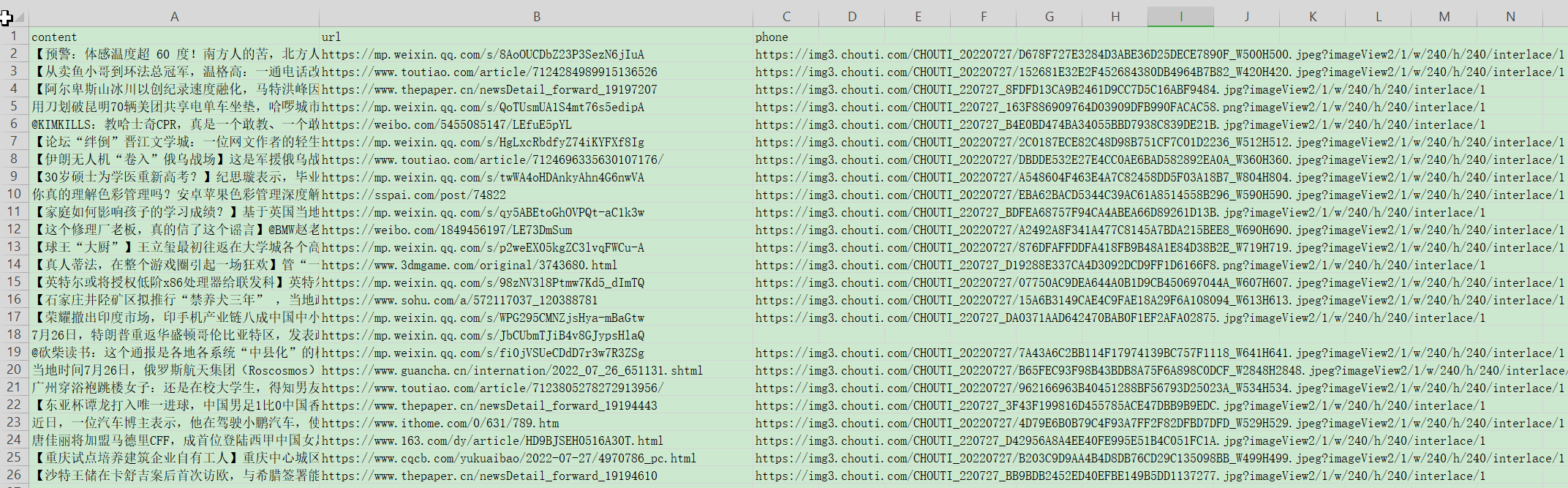
3.2 保存到数据库
pipline item 存储(支持mysql, redis, 文件...) * 1. 在item.py 中写一个类- 1
- 2
# item.py import scrapy # 继承Item类 class FisetscrapyItem(scrapy.Item): # define the fields for your item here like: # 定义字段 content = scrapy.Field() url = scrapy.Field() phone = scrapy.Field()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
* 2. spinder中爬虫程序中导入item.py中定义的类, 实例化得到一个item对象 将数据保存到item对象中, item对象['属性名'] = 值 不支持.属性的方式, 作者没有写__setattr__ 与 __getattr__ 方法 保存的对象有多个使用yield返回, 单个对象可以使用return返回.- 1
- 2
- 3
- 4

* img标签静态图与动态图的class属性的值不一样.- 1
# chouti.py import scrapy # 导入item中定义的类 from items import FisetscrapyItem class ChoutiSpider(scrapy.Spider): name = 'chouti' allowed_domains = ['dig.chouti.com'] start_urls = ['http://dig.chouti.com/'] def parse(self, response): # 获取新闻的div标签, 目前一页25条 div_list = response.xpath('//div[contains(@class, "link-item")]') # 定义item类 item = FisetscrapyItem() # 遍历每条新闻标签 for div in div_list: # 获取新闻 content = div.css('.link-title::text').extract_first() # 获取新闻链接 url = div.css('.link-title::attr(href)').extract_first() # 获取封面 phone = div.css('.image-scale::attr(src)').extract_first() # 封面是动态图使用上述方法无法获取到 if not phone: phone = div.css('.matching::attr(src)').extract_first() # 将每一条新闻的信息封装到item对象中 item['content'] = content item['url'] = url item['phone'] = phone # 制作成迭代器 [item对象1, ... item对象25] yield item- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
* 3. 在settings.py 中配置ITEM_PIPELINES属性, 配置保存执行的类 ITEM_PIPELINES = { '项目名.pipeline.文件保存执行的类名(持久化的类名)': 数字 } # 优先级, 数字越小, 优先级有高.- 1
- 2
- 3
- 4
- 5
ITEM_PIPELINES = { # 一个配置信息代码保存一样, 可以配置类保存到不同的位置 'fisetscrapy.pipelines.FisetscrapyPipeline': 300, }- 1
- 2
- 3
- 4
* 4. piplines.py 中写持久化的类 只要爬虫程序执行后有返回结果, 就会触发piplines.py的持久化的类的方法. process_item()方法, 返回一个结果(非None)触发一次. open_spider()方法, 触发一次, 在第一次process_item方法执行前触发. close_spider()方法, 触发一次, 在最后一次process_item方法执行后触发. 三个方法都需要接收spider参数, spider是当前执行的爬虫脚本对象, spider.name可以获取到爬虫脚本的名称, 在执行多个爬虫文件时可以通过爬虫爬虫脚本的名称将爬取的数据保存到不同的文件或数据库中. process_item需要接收item参数, item 参数是爬虫脚本返回的item对象.- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
# iplines.py 测试代码 class FisetscrapyPipeline: def open_spider(self, spider): print('开始') def close_spider(self, spider): print('结束') # 只有爬虫程序中有数据返回, 就会执行一次process_item方法 def process_item(self, item, spider): print(1)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

# iplines.py 真实代码 class FisetscrapyPipeline: def open_spider(self, spider): # 开启文本句柄 self.file_obj = open('chouti.text', mode='wt', encoding='utf-8') def close_spider(self, spider): # 关闭文本句柄 self.file_obj.close() # 只有爬虫程序中有数据返回, 就会执行一次process_item方法 def process_item(self, item, spider): # 做为一行写入 content = item['content'] url = item['url'] phone = item['phone'] print(content, url, phone) # 在字符串后加上\n, 不然所有的数据挤在一行. self.file_obj.write(content + ' ' + url + ' ' + phone + '\n')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
3.3 多存储方式
* 1. 在settings.py 中配置ITEM_PIPELINES属性- 1
ITEM_PIPELINES = { # 保存到文件的类 优先级高 'fisetscrapy.pipelines.FisetscrapyPipeline': 300, # 保存到mysql的类 优先级低 'fisetscrapy.pipelines.FisetscrapyPipelineMysql': 301, }- 1
- 2
- 3
- 4
- 5
- 6
* 2. 在匹配pipelines.py中 添加FisetscrapyPipelineMysql类 * pipelines.py中定义的类接收类item一定要将item返回, 不然下面持久化的类的item就是None, 而不是对象.- 1
- 2
from itemadapter import ItemAdapter import pymysql class FisetscrapyPipeline: def open_spider(self, spider): # 开启文本句柄 self.file_obj = open('chouti.text', mode='wt', encoding='utf-8') def close_spider(self, spider): # 关闭文本句柄 self.file_obj.close() # 只有爬虫程序中有数据返回, 就会执行一次process_item方法 def process_item(self, item, spider): # 做为一行写入, content = item['content'] url = item['url'] phone = item['phone'] self.file_obj.write(content + ' ' + url + ' ' + phone + '\n') # 这里一定要将item返回不然下面持久化的类的item就是None, 而不是对象 return item class FisetscrapyPipelineMysql: def open_spider(self, spider): # 创建数据库连接对象 self.conn = pymysql.connect( host='127.0.0.1', user='root', # csdn提示文章有风险 不推广, 牛bl password=你的密码, database='chouti', port=3306, ) def close_spider(self, spider): # 关闭mysql self.conn.close() def process_item(self, item, spider): curses = self.conn.cursor() # 写sql语句, 数据库是chouti, 表名是 article, 字段有 content, url, phone sql = 'insert into article (content, url, phone) value(%s, %s, %s)' content = item['content'] url = item['url'] phone = item['phone'] curses.execute(sql, [content, url, phone]) # 二次确认 self.conn.commit() # 这里一定要将item返回不然下面持久化的类的item就是None, 而不是对象 return item- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
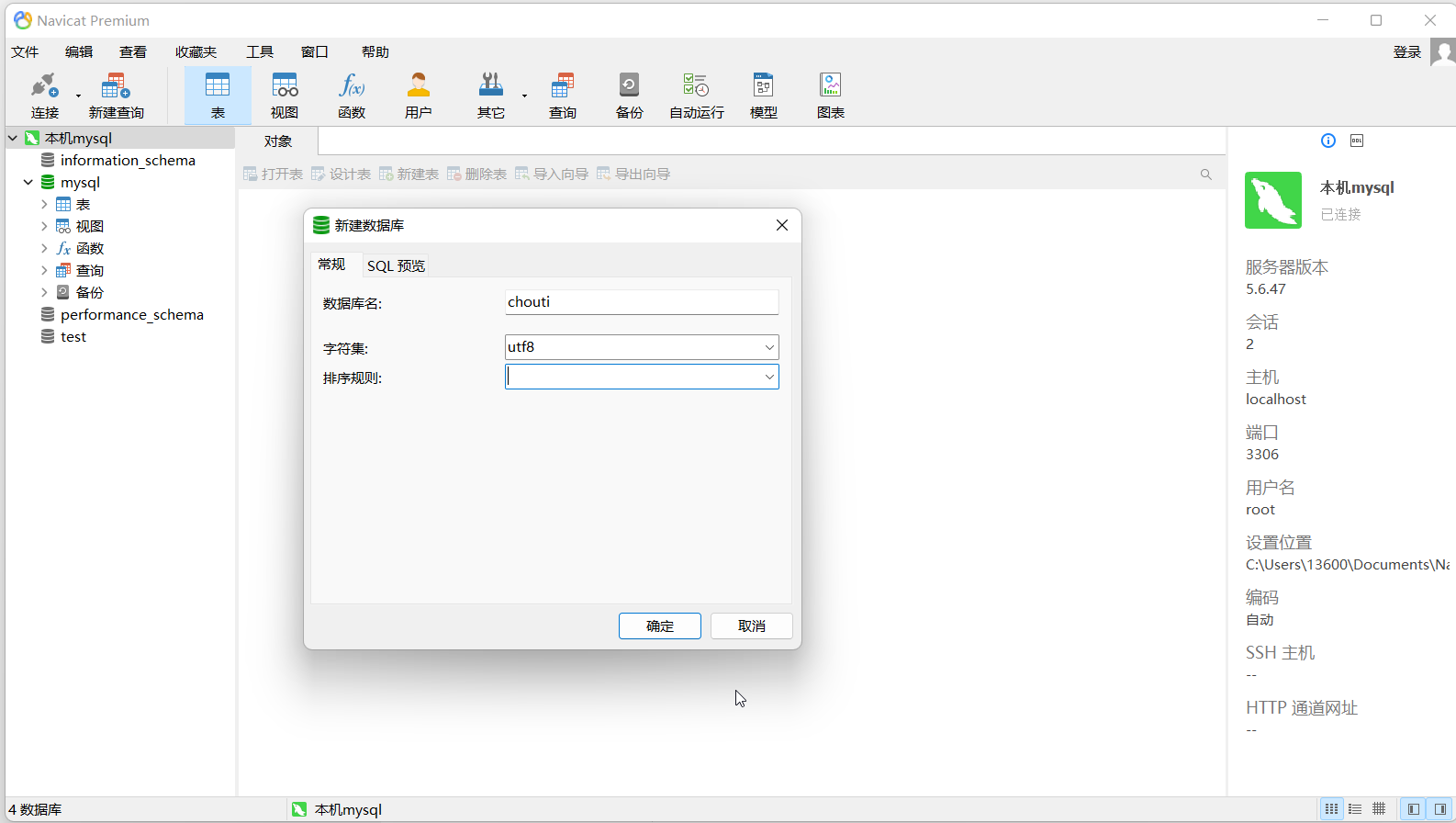
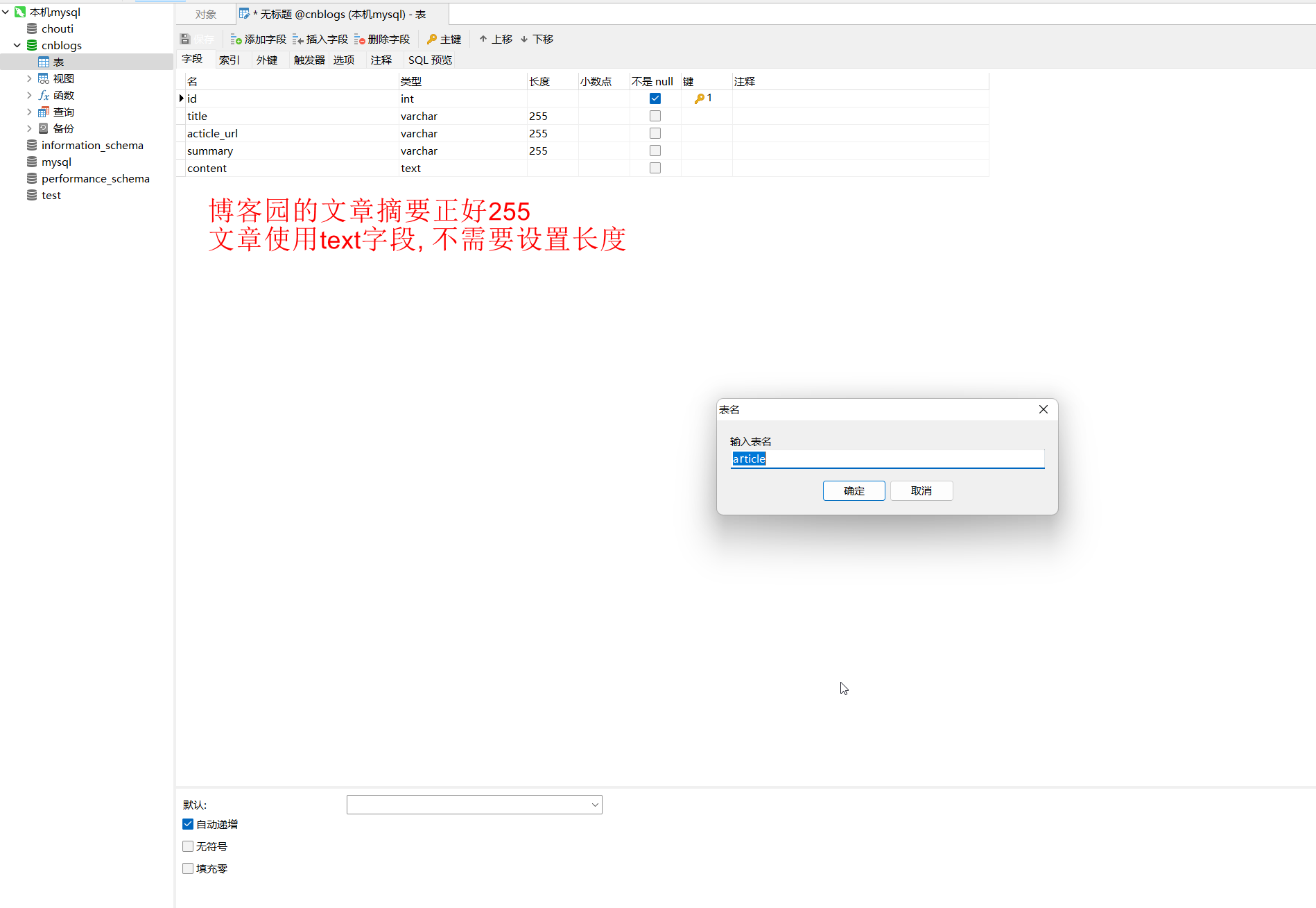
* 3. 新建数据库- 1
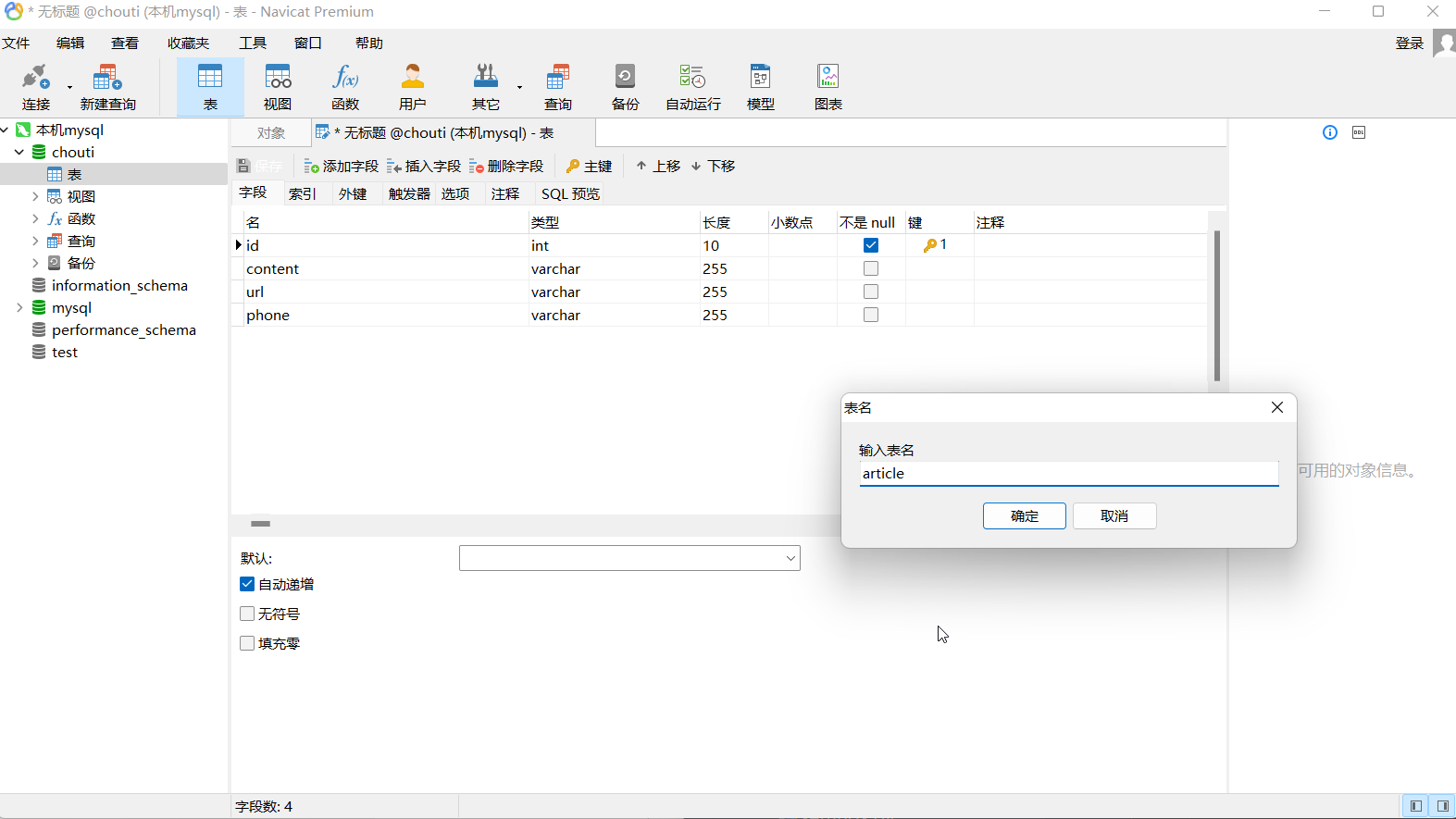
* 4. 创建表- 1
* 5. 执行之后数据先保存到text文件一份, 再保存到数据库一份.- 1

4. 案例
爬取原则: 深度优先: 先进先出, 队列(默认). 广度优先: 先进后出, 栈.- 1
- 2
- 3
4.1 创建项目
* 1. 创建Crapy项目 命令: scrapy startproject cnblogs C:\Users\13600\Desktop\synchro\Project- 1
- 2
C:\Users\13600\Desktop>scrapy startproject cnblogs C:\Users\13600\Desktop\synchro\Project New Scrapy project 'cnblogs', using template directory 'c:\program\python38\lib\site-packages\scrapy\templates\project', created in: C:\Users\13600\Desktop\synchro\Project You can start your first spider with: cd C:\Users\13600\Desktop\synchro\Project scrapy genspider example example.com- 1
- 2
- 3
- 4
- 5
- 6
- 7
* 2. 创建爬虫脚本(爬虫脚本名称与项目名不能重复) 命令: scrapy genspider cnblog www.cnblogs.com- 1
- 2
PS C:\Users\13600\Desktop\synchro\Project\cnblogs> scrapy genspider cnblog www.cnblogs.com- 1
* 3. 在项目目录下创建运行爬虫脚本主程序main.py- 1
# main.py from scrapy.cmdline import execute execute(['scrapy', 'crawl', 'cnblog'])- 1
- 2
- 3
- 4
- 5
* 4. 修改爬虫配置文件- 1
# 不遵循爬虫协议 ROBOTSTXT_OBEY = False # 展示错误日志 LOG_LEVEL = 'ERROR' # 全局USER_AGENT USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) ' \ 'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.134 Safari/537.36 Edg/103.0.1264.71'- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
4.2 爬虫脚本
* 1. 在item.py中创建item对象.- 1
import scrapy class CnblogsItem(scrapy.Item): # define the fields for your item here like: title = scrapy.Field() article_url = scrapy.Field() summary = scrapy.Field() content = scrapy.Field()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
* 2. 获取所有文章标签, 在遍历标签列表获取文章的标签, 连接, 摘要...- 1
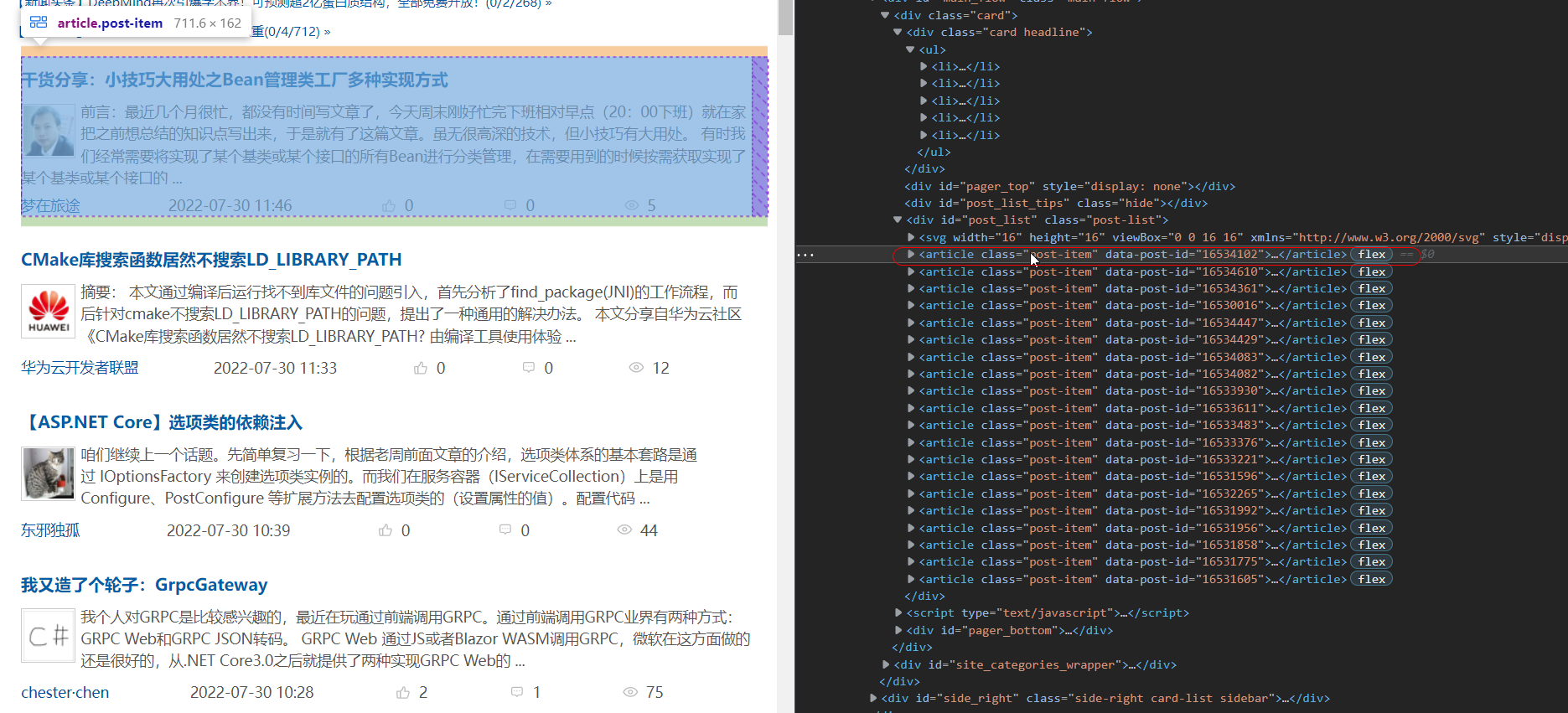
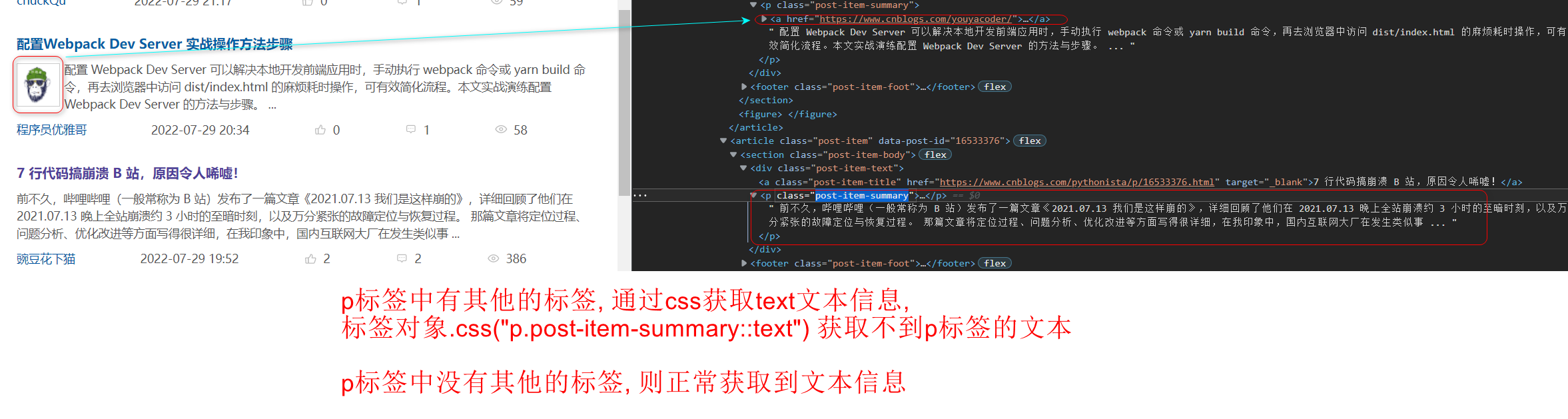
文章摘要的p标签有两种情况 <p> <img> 头像<img> 文章摘要</p> <p> 文章摘要</p> 通过css选择器获取:(如果p标签中有子标签或获取子标签的文本信息) summary = article.css('p.post-item-summary::text') p标签中有img标签会得到两个Selector对象 [ <Selector xpath="descendant-or-self::p[@class and contains(concat(' ', normalize-space(@class), ' '), ' post-item-summary ')]/text()" data='\n '>, <Selector xpath="descendant-or-self::p[@class and contains(concat(' ', normalize-space(@class), ' '), ' post-item-summary ')]/text()" data='\n 问题描述 经过前两篇文章,分别使...'> ] p标签中没有img标签会得到一个Selector对象 [ <Selector xpath="descendant-or-self::p[@class and contains(concat(' ', normalize-space(@class), ' '), ' post-item-summary ')]/text()" data='\n 前不久,哔哩哔哩(一般常称为 B...'> ] [Selector对象][-1] [Selector对象, Selector对象][-1] 获取最后的一个Selector对象获取文本信息, 在去除空格. summary = article.css('p.post-item-summary::text')[-1].extract().strip()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
import scrapy # from scrapy.http.request import Request # 在 scrapy的__init__ 中 写了 from scrapy.http import Request, 那么可以直接 from scrapy import Request from scrapy import Request class CnblogSpider(scrapy.Spider): name = 'cnblog' allowed_domains = ['www.cnblogs.com'] start_urls = ['http://www.cnblogs.com/'] def parse(self, response): # 获取item对象 from items import CnblogsItem item = CnblogsItem() # 获取所有的article标签 article_list = response.css('article.post-item') # 遍历article标签 for article in article_list: # 获取标签 title = article.css('a.post-item-title::text').extract_first() item['title'] = title # 获取文章链接 article_url = article.css('a.post-item-title::attr(href)').extract_first() item['article_url'] = article_url # 获取文章摘要 summary = article.css('p.post-item-summary::text')[-1].extract().strip() item['summary'] = summary """ 将文章链接做成一个request对象返回, 如果返回的是一个链接会再次支持爬虫程序去爬取这个链接. 爬取之后会返回响应对象. Request方法参数: url: 再次爬取的地址, 值为字符串. callback: 回调执行的方法, 响应对象回来默认到执行parse方法. 值是一个自定义方法. meta: 爬虫程序两个方法可以使用参数作为数据传递的管道, 值为字典类型. """ yield Request(article_url, callback=self.parse_detail, meta={'item': item}) def parse_detail(self, response, **kwargs): # 从response中获取出item对象 item = response.meta.get('item') # 获取到html标签的文档, 不然下载再来就是没有排版的文字. content = response.css('#cnblogs_post_body').extract_first() item['content'] = content # 将数据返回 yield item- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
需要再次对数据进行爬取的时候, 返回一个request对象. from scrapy import Request yeild Request('地址', callback='响应返回执行的方法', meta='将数据保存到下一次的响应对象中')- 1
- 2
- 3
- 4
* 3. 在settings配置文件中配置数据持久化类- 1
ITEM_PIPELINES = { 'cnblogs.pipelines.CnblogsPipeline': 300, }- 1
- 2
- 3
* 4. 编写数据持久化类代码- 1
# pipelines.py from itemadapter import ItemAdapter class CnblogsPipeline: def open_spider(self, spider): # 创建数据连接对象 import pymysql self.conn = pymysql.connect( user='root', password=你的密码, host='127.0.0.1', database='cnblogs', port=3306 ) def close_spider(self, spider): # 关闭连接 self.conn.close() def process_item(self, item, spider): # 创建游标对象 cursor = self.conn.cursor() # 写sql语句 sql = 'insert into article (title, acticle_url, summary, content) values(%s, %s, %s, %s)' # 获取数据(值是一个列表) values = self.get_value(item) # 插入数据 cursor.execute(sql, values) # 二次确认 self.conn.commit() return item @staticmethod def get_value(item): item_dict = item.__dict__.get('_values') return list(item_dict.values())- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
* 5. 创建数据库与表- 1
* 5. 执行程序获取数据- 1

* 6. 获取下一页, 下一页, ...的数据 可以自己for循环写递增页面, 也可以通过获取>下一个的地址. 这个资源地址需要自己加上前缀.- 1
- 2
- 3

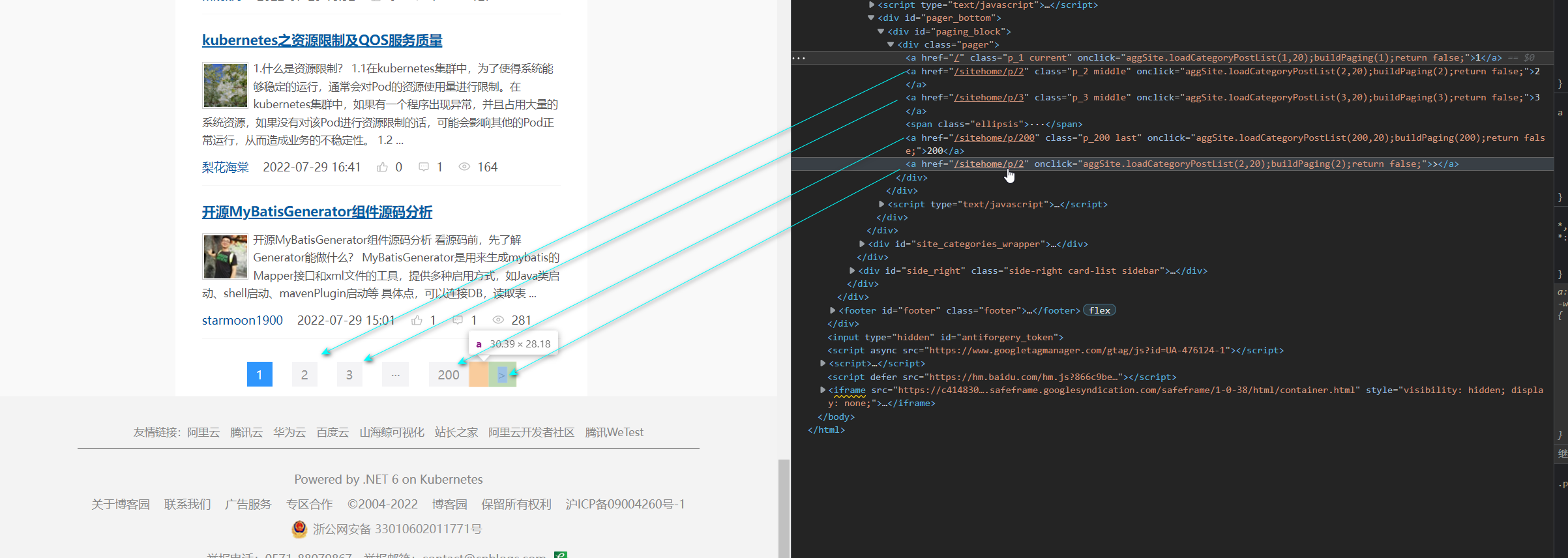
def parse(self, response): # 获取item对象 from items import CnblogsItem # 获取所有的article标签 article_list = response.css('article.post-item') # 遍历article标签 for article in article_list: ... # 在for循环后面添加上以下代码继续爬取下页的数据. # 获取下一个的地址, 爬取下一页的数据 next = 'https://www.cnblogs.com' + response.css('#paging_block>div a:last-child::attr(href)').extract_first() # 返回Request对象, 返回的响应对象还是parse方法解析 yield Request(next)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
* 7. 执行程序, 几秒就几百条数据了.- 1
5. 提高scrapy效率
在配置文件中进行相关的配置(scrapy有一套默认的配置, 有一套供用户修改的配置settings.py) * 1. 增加并发: scrapy默认开启的并发线程为32个, 可以适当进行增加. 在settings配置文件中修改CONCURRENT_REQUESTS = 100, 设置并发为100. * 2. 降低日志级别: 日志优先级别标准顺序为: ALL < TRACE < DEBUG < INFO < WARN < ERROR < FATAL < OFF 运行scrapy时会产生大量日志占用CPU,为减少CPU使用率,可修改log输出级别 settings配置文件中LOG_LEVEL='ERROR' 或 LOG_LEVEL = 'INFO' * 3. 禁止cookie: scrapy默认自动保存cookie, 占用CPU. 如果不是真的需要cookie, 可设置为不保存cookie, 以减少CPU使用率. settings配置文件中修改COOKIES_ENABLED = False * 4. 禁止请求重试: 对于失败的请求会重新发送, 则会减慢爬取速度, 因此可以在对丢失少量数据也不影响时, 禁止重试. settings配置文件中修改RETRY_ENABLED = False * 5. 减少下载超时(超时不爬取数据): 如果对一个非常慢的链接进行爬取, 减少下载超时可以让卡住的链接快速被放弃, 从而提升效率. 在settings配置文件中修改DOWNLOAD_TIMEOUT = 10 设置超时时间10秒.- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
————————————————
文章的段落全是代码块包裹的, 留言是为了避免文章提示质量低.
文章的段落全是代码块包裹的, 留言是为了避免文章提示质量低.
文章的段落全是代码块包裹的, 留言是为了避免文章提示质量低.
文章的段落全是代码块包裹的, 留言是为了避免文章提示质量低.
文章的段落全是代码块包裹的, 留言是为了避免文章提示质量低.
文章的段落全是代码块包裹的, 留言是为了避免文章提示质量低.
文章的段落全是代码块包裹的, 留言是为了避免文章提示质量低.
文章的段落全是代码块包裹的, 留言是为了避免文章提示质量低.
文章的段落全是代码块包裹的, 留言是为了避免文章提示质量低.
文章的段落全是代码块包裹的, 留言是为了避免文章提示质量低.
———————————————— -
相关阅读:
java计算机毕业设计小学课后辅助平台源代码+数据库+系统+lw文档
【项目】在线oj
荣幸地成为2022-2023年度中国第一个login的Oracle ACE
2023-python pdf转换为PPT代码
django实现用户的注册、登录、注销功能
python学习笔记(3)—— 数据结构
yml文件没有变成配置文件图标(IDEA)
论文写作——结论的内容和类型
API 网关 Apache APISIX 3.0 版本正式发布
9月1日目标检测学习笔记——通用物体检测
- 原文地址:https://blog.csdn.net/qq_46137324/article/details/126186085
