-
【论文笔记】—低照度图像增强—Supervised—基于频率的分解和增强模型—2020-CVPR
【论文介绍】
提出了一种基于频率的分解和增强模型,用于低光图像去噪,并增强细节。
- 【题目】:Learning to Restore Low-Light Images via Decomposition-and-Enhancement
- 【DOI】:10.1109/CVPR42600.2020.00235
- 【时间】:2020
- 【会议】:2020-CVPR
- 【机构】:大连理工大学、香港城市大、Pengcheng Lab
- 【论文链接】:https://openaccess.thecvf.com/content_CVPR_2020/papers/Xu_Learning_to_Restore_Low-Light_Images_via_Decomposition-and-Enhancement_CVPR_2020_paper.pdf
- 【代码链接】:未公开
【提出问题】
- 实际的低光照图像信噪比很低,受噪声影响很大,现有的方法基本都无法同时完成提亮和去噪这两个任务。
- 简单地在前处理或者后处理步骤中加入降噪的缓解并不能很好的解决这个问题。
其一,降噪模型难以从极低的信噪比中提取出有效的信息。(即使先提亮,信息量也不会增加,即不能改善信噪比)。
其二,现有去噪方法,噪声可能会被不可预测地放大,产生的图像仍然具有低信噪比,因此难以进一步去噪。
【解决方案】
提出了一种基于频率的分解和增强模型,首先在低频层中学习恢复图像对象,然后基于恢复的图像自适应地增强高频细节。
启发1:噪声在不同频率层中表现出不同程度的对比度,并且在低频层中检测噪声比在高频层中容易得多。
启发2:已知自然图像的原始部分,例如边缘和角落,具有非常低的本征维数[29]。如此低的维度意味着少量的图像示例足以很好地表示图像基元[41]。因此,给定基元的低频信息,就可能能够更好的推断相应的高频信息。
例如:图1应用高斯滤波器将(b)分解为低频层(c)和高频层(d),并观察到低频层保留了足够的信息用于恢复对象和颜色,然后可以用于增强高频细节。

【创新点】
- 模型:基于频率的分解和增强模型来增强低光图像。 首先在抑制噪声的同时恢复低频层的图像内容,然后恢复高频图像细节。
- 网络模块:一个注意上下文编码 (ACE) 模块来分解输入图像以自适应地增强高/低频层,一个跨域变换 (CDT) 模块来抑制噪声和细节增强。
- 数据集:创建了一个具有真实噪声的低光图像配对数据集。(未公开)
【网络模型】
在第一阶段,网络在抑制噪声的情况下增强输入图像 I 的低频内容,然后将其放大以产生 Ia。
在第二阶段,网络从 Ia 中推断出高频细节以产生输出增强图像 Ic。
在第一阶段,网络在抑制噪声的情况下增强输入图像 I 的低频内容,然后将其放大以产生 I^a。
学习低频图像增强函数C(·),然后学习用于颜色恢复的放大函数A(·)。通过联合建模从C(·)到A(·)的映射,网络不必同时学习全局信息(例如,光照)和局部信息(例如,颜色),从而得到更有效的增强。

其中,I是低光照sRGB原图,α是可学习的全局比例,I^a是第一部分的输出即低频图像增强结果 。
在第二阶段,网络从 I^a 中推断出高频细节以产生输出增强图像 I^c。
基于来自第一阶段的I^a来学习高频细节增强函数D(·),而不是直接从具有噪声的原始输入图像I中恢复高频细节。D(·)然后以残差方式建模,并且最终的增强图像可以获得为:

图4可视化模型的每个步骤的输出。

注意上下文编码 (ACE) 模块
其目的是将图像分解为基于频率的层,以便在两个阶段中进行自适应增强。参考博客

输入Xin为H×W×C维度的矩阵,分为三个branch,两路经过的是不同的空洞卷积,记为fd1和fd2,用于提取不同感受野中的特征。 通过计算得到这两个特征之间的对比度感知注意力图 Ca:

理解一下这里的Ca, 表示像素级的相对对比度信息,其中高对比度的像素被视为属于高频层。 为了将低频内容特征取出,这时候将Ca取反
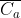 ,取出原低对比度的像素,即Xc。
,取出原低对比度的像素,即Xc。
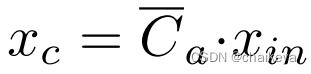
这里的Xc^↓指的是Xc经过一层pooling层缩小特征维度,g、h、f代表着一系列卷积、reshape、转置等组成的操作,这里的意图是为了通过考虑每个像素与所有其他像素关系来计算非局部增强特征。
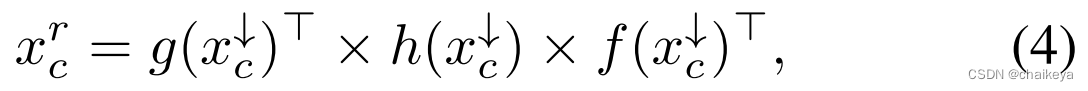
结构中存在着两个ACE部分,上面的ACE部分使用的是低频的增强,即Ca处需要计算逆,而下面的ACE部分使用的是高频的增强,即原生的Ca。图6就展示了两者的区别,Ca使用的高频的特征,而Ca逆使用的是低频特征。

跨域转换 (CDT) 模块
旨在增加感受野,同时弥合弱光域和增强域之间的特征差距。
也就是解决域间隙问题,即在噪声低光域中提取的频率感知特征与在增强域中提取的特征。

在第一阶段,首先,来自编码器Xen的噪声特征首先经由Ca的逆即低频内容特征在空间上重新加权,以滤除高对比度信息。然后,与来自相应解码器的特征Xde连接,从连接的特征[Xen,Xde]计算全局缩放向量V,用于以 channel-wise 方式自适应地重新缩放来自不同域的特征,得到v后两者再度相乘和得到最后的Xout。
在第二阶段,使用对比度感知的注意力图Ca即高频,来学习图像细节,类似于ACE模块。这里的Xde即图中decoder中直接连接的部分,Xen编码器的噪声特征:

【损失函数】
使用了两个loss,Lacc和Lvgg,参考博客,深度学习之L1 loss和L2 loss的区别
Lacc:是个普通的L2 loss,If^gt是低频图像的GT,I^c是模型恢复图,I^gt是恢复图的GT,为了尽可能使低频图和恢复图都接近GT,C指的是第一阶段重建的低频图中的图像内容。
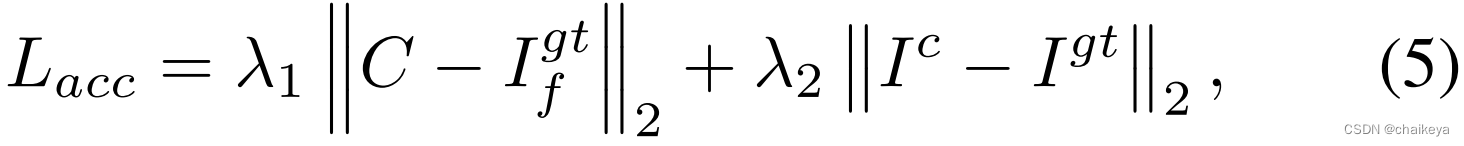
Lvgg:是个普通的L1 loss,Φ使用的是训练完毕的VGG,提取特征后进行两图对比的loss,为了尽可能使两图的全局语义特征相同。
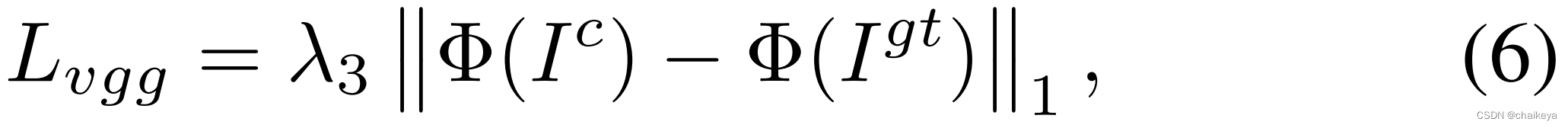
【数据集】
创建了一个具有真实噪声的低光图像配对数据集。这个数据集源数据来自SID数据集。但是作者指出,SID数据集训练数据是Raw数据对。而本文则在SID的基础上,对SID的Raw数据对上通过“Exposure Compensation”,“White balance”,“De-linearization”三个步骤,将Raw数据对转化为了非线性的sRGB数据对。
【实验结果】
1、定量分析
表1:与最先进的增强方法的比较。 最佳性能以粗体标记。 请注意,* 表示模型是在我们的 sRGB 训练集上重新训练的。
不管是在 Raw数据对上还是sRGB数据对上本文的方法都表现得最好;
且SID和Deep UPE方法通过在 sRGB 训练集上进行去噪训练,结果表现得比原来方法更好。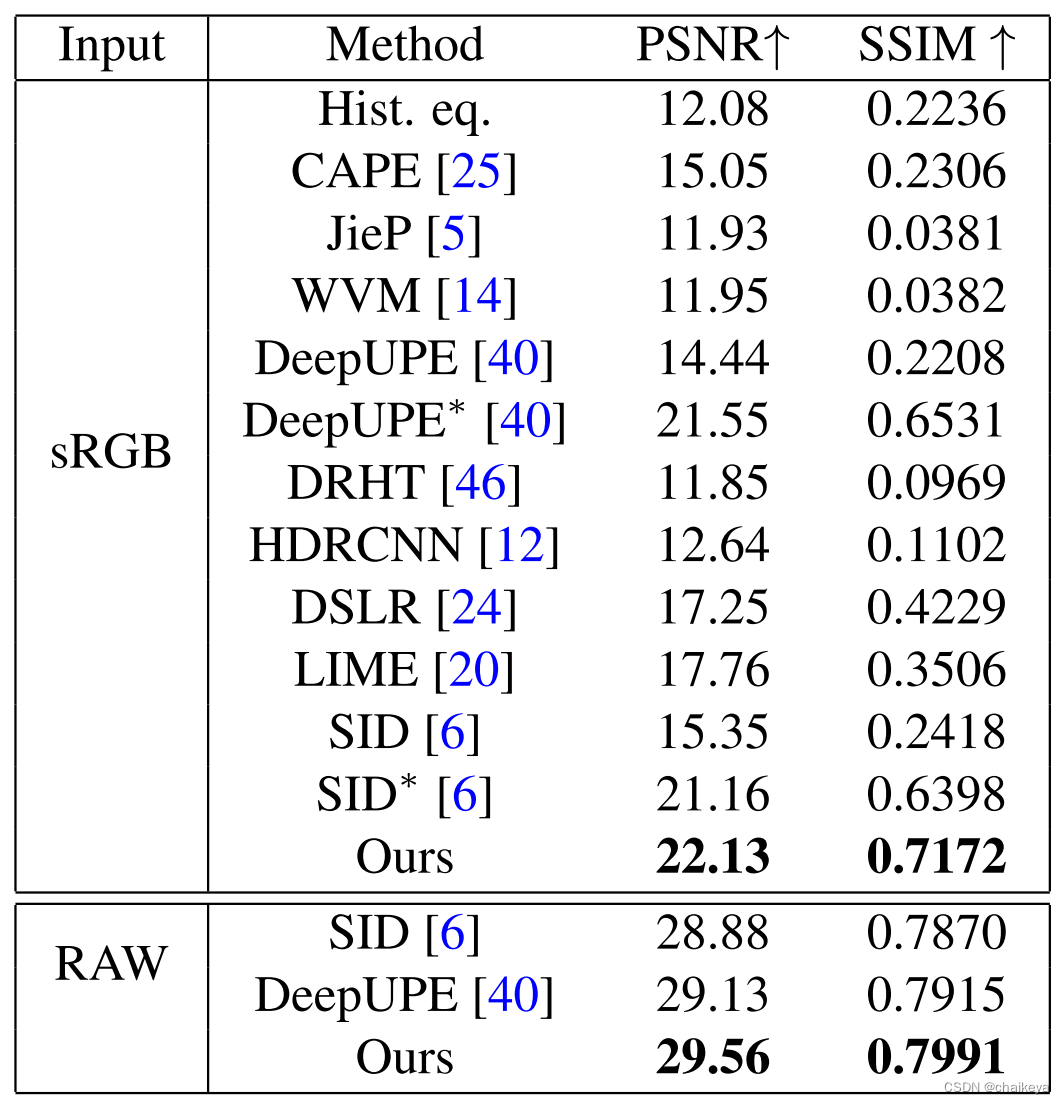
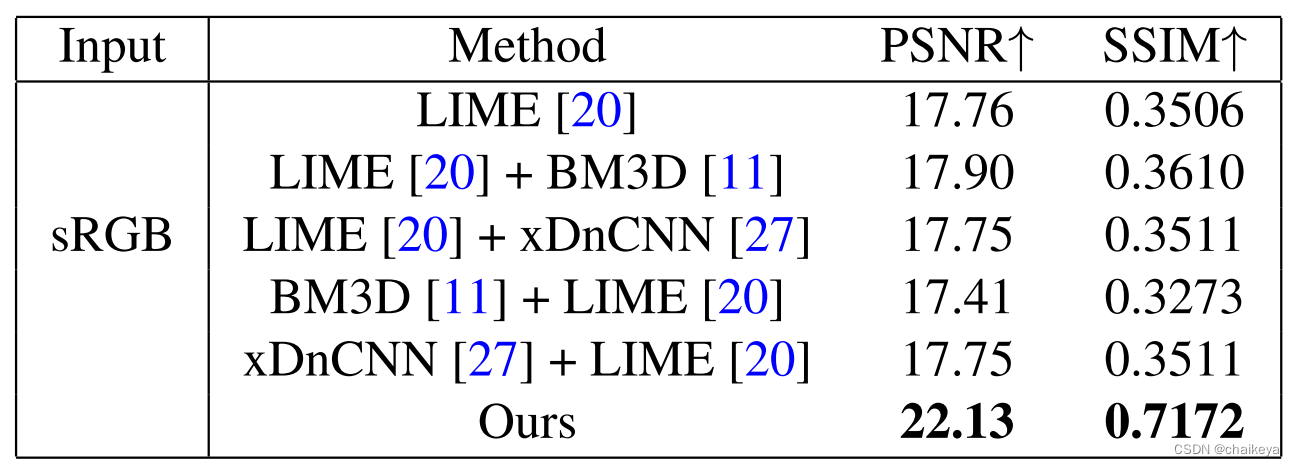
表2:比较增强和去噪方法的不同组合。最佳性能以粗体标出。
直接将现有的去噪方法作为预处理/后处理步骤应用于增强方法并不能很好地工作。由于噪声已经深深地埋在低光图像中的图像内容和细节中,因此单独增强和去噪这些图像效果不佳。相反,我们抑制了低频层中的噪声,然后自适应地增强了内容和细节,从而产生了更好的性能。
评价指标:
PSNR:(峰值信噪比)值越大,表示图像失真越小。
SSIM:(结构相似性)取值范围[0,1],值越大,表示图像失真越小。2、定性分析
图8:与其他方法比较,红色框表示大多数现有方法失败的嘈杂区域。
这是由索尼相机拍摄的,然后作者还用iPhone相机拍摄也取得了好的效果,证明模型的泛化能力

图10:去噪方法对比,“ X+”表示使用LIME[20]进行后处理,而“+X ”表示使用LIME进行预处理。红色框表示大多数现有方法失败的噪声区域。
(g)(h)由于在增强步骤中增强了噪声和细节,因此结果的噪声更大。还值得注意的是,这些方法都不能很好地恢复颜色(由噪声引起),例如树的紫色。相反,我们的方法可以产生具有噪声抑制和色彩恢复的清晰图像(d)。

-
相关阅读:
好用、高性能的远程控制软件推荐
华东师范大学副校长周傲英:数据赋能,从数据库到数据中台
数字孪生电力系统,可视化应用实现科学调度的电子设备
SpringCloud 三种服务调用方式,你学会了吗?
数字孪生技术在智慧城市应用的推进建议
JAVA宠物寄存中心计时收费系统计算机毕业设计Mybatis+系统+数据库+调试部署
ElasticSearch之Windows中环境安装
springMVC
docker-compose模板文件、命令的使用
【QT】点击按钮弹出对话框的注意事项
- 原文地址:https://blog.csdn.net/qq_39751352/article/details/126171653