-
Pytorch介绍以及基本使用
目录
前言
Pytorch是torch的python版本,是由Facebook开源的神经网络框架,专门针对 GPU 加速的深度神经网络(DNN)编程,相比于Tensorflow,Pytorch简介易用。
一、为什么选择Pytorch
简洁:PyTorch的设计追求最少的封装,尽量避免重复造轮子。PyTorch的源码只有TensorFlow的十分之一左右,更少的抽象、更直观的设计使得PyTorch的源码十分易于阅读。
速度:PyTorch 的灵活性不以速度为代价,在许多评测中,PyTorch 的速度表现胜过 TensorFlow和Keras 等框架。
易用:PyTorch 是所有的框架中面向对象设计的最优雅的一个。PyTorch的面向对象的接口设计来源于Torch,而Torch的接口设计以灵活易用而著称。
生态丰富:PyTorch 提供了完整的文档,循序渐进的指南,此外,相关社区还在逐渐壮大。二、Pytorch的基本使用
2-0、张量的定义
张量:张量是一种特殊的数据结构,与Numpy中的arrays非常相似,在Pytorch中,我们使用张量对模型的输入和输出以及模型的参数进行编码。
注意:Tensors和Numpy中的数组具有底层内存共享,意味着不需要进行复制直接就可以相互转化。2-1、直接创建张量
2-1-1、torch.Tensor()
import torch torch.Tensor([1, 2, 3]) # 涉及到的参数 # data:data的数据类型可以是列表list、元组tuple、numpy数组ndarray、纯量scalar(又叫标量)和其他的一些数据类型。 # dtype:该参数可选参数,默认为None,如果不进行设置,生成的Tensor数据类型会拷贝data中传入的参数的数据类型,比如data中的数据类型为float,则默认会生成数据类型为torch.FloatTensor的Tensor。 # device:该参数可选参数,默认为None,如果不进行设置,会在当前的设备上为生成的Tensor分配内存。 # requires_grad:该参数为可选参数,默认为False,在为False的情况下,创建的Tensor不能进行梯度运算,改为True时,则可以计算梯度。 # pin_memory:该参数为可选参数,默认为False,如果设置为True,则在固定内存中分配当前Tensor,不过只适用于CPU中的Tensor。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
输出:
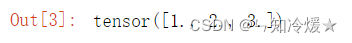
2-1-2、torch.from_numpy()
# notice: 当然我们也可以直接将numpy数组直接转化为Tensor import torch import numpy as np t1 = [1, 2, 3] np_array = np.array(t1) data = torch.from_numpy(np_array) print(data)- 1
- 2
- 3
- 4
- 5
- 6
- 7
输出:
2-2、创建数值张量
2-2-1、torch.ones()
# 创建全1张量。 torch.ones((2,4))- 1
- 2
输出:

2-2-2、torch.full()
torch.full([2,3],2.0) 参数: # size: 定义了输出张量的形状。 # full_value: 定义填充的值。- 1
- 2
- 3
- 4
- 5
输出:

2-2-3、torch.arange()
# 创建等差数列 torch.arange(0, 10, 2) 参数: start: 等差数列开始。 end: 等差数列结束。 steps: 等差数列的差是多少。- 1
- 2
- 3
- 4
- 5
- 6
- 7
输出:

2-2-4、torch.linespace()
# 创建线性间距向量 torch.linspace(2, 10, 5) # 参数: # start: 起始位置 # end: 结束位置 # steps: 步长 # out: 结果张量- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
输出:

2-2-5、torch.eye()
# 创建对角矩阵 # 即生成对角线全为1,其余部分全为0的二维数组 torch.eye(10,3) # 参数: # n: 行数 # m: 列数 # out: 输出类型,即输出到哪个矩阵。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
输出:

2-3、根据概率创建张量
2-3-1、torch.randn()
# 创建随机值 # 与rand不同的是,它创建的是包含了从标准正态分布(均值为0,方差为1)中取出的一组随机值。 torch.randn(4) # 参数 # size: 定义了输出张量的形状 # out: 结果张量- 1
- 2
- 3
- 4
- 5
- 6
输出:

2-3-2、torch.randint()
# 返回一个填充了随机整数的张量,这些整数在low和high之间均匀生成。张量的shape由参数size定义。 torch.randint(100,size=(10,10)) # 参数说明: # 常用参数: # low ( int , optional ) – 要从分布中提取的最小整数。默认值:0。 # high ( int ) – 高于要从分布中提取的最高整数。 # size ( tuple ) – 定义输出张量形状的元组。 # 关键字参数: # generator ( torch.Generator, optional) – 用于采样的伪随机数生成器 # out ( Tensor , optional ) – 输出张量。 # dtype ( torch.dtype , optional) – 如果是None,这个函数返回一个带有 dtype 的张量torch.int64。 # layout ( torch.layout, optional) – 返回张量的所需布局。默认值:torch.strided。 # device ( torch.device, optional) – 返回张量的所需设备。默认值:如果None,则使用当前设备作为默认张量类型(请参阅torch.set_default_tensor_type())。device将是 CPU 张量类型的 CPU 和 CUDA 张量类型的当前 CUDA 设备。 # requires_grad ( bool , optional ) – 如果 autograd 应该在返回的张量上记录操作。默认值:False。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
输出:

2-3-3、torch.rand()
# 创建随机值 # 均匀分布 torch.rand(4)- 1
- 2
- 3
输出:

2-4、张量的一些操作:拼接、切分索引变换
2-4-1、torch.ones_like函数和torch.zeros_like函数
input = torch.rand(4, 6) print(input) # 生成与input形状相同、元素全为1的张量 a = torch.ones_like(input) print(a) # 生成与input形状相同、元素全为0的张量 b = torch.zeros_like(input) print(b)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
输出:

2-4-2、torch.cat函数
# 生成一个两行三列的全1张量。 t = torch.ones((2,3)) # 拼接函数cat # 在给定维度上对输入的张量进行连接操作 torch.cat([t,t], dim=0) # 参数 # inputs : 待连接的张量序列,可以是任意相同Tensor类型的python 序列 # dim : 选择的扩维, 必须在0到len(inputs[0])之间,沿着此维连接张量序列。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
输出:
tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])2-4-3、torch.stack函数
# 拼接函数stack # 与cat不同的是,stack会增加维度。 简单来说就是增加新的维度进行堆叠。 # 扩维拼接! torch.stack([t,t], dim=1) # 参数 # inputs : 待连接的张量序列,可以是任意相同Tensor类型的python 序列 # dim : 选择的扩维, 必须在0到len(inputs[0])之间,沿着此维连接张量序列。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
输出:

2-4-4、torch.chunk函数
t = torch.ones((2,5)) # 在给定维度上将输入张量进行分块 torch.chunk(t, dim=1, chunks=5) # input:被分块的张量。 # chunks:要切的份数。 # dim:在哪个维度上切分。- 1
- 2
- 3
- 4
- 5
- 6
输出:

2-4-5、torch.split函数
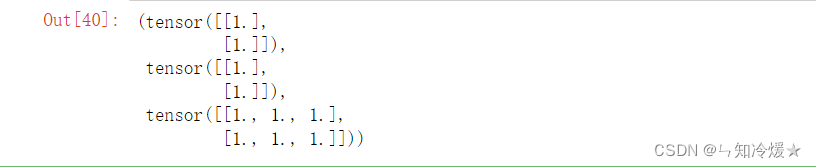
# 将tensor分成块结构 torch.split(t, [1,1,3], dim=1) # input:待输入张量 # split_size_or_sections: 需要切分的大小,可以为列表或者数字。 # dim:切分维度- 1
- 2
- 3
- 4
- 5
输出:
参考文章:
pytorch简介.
PyTorch 的基本使用.
Pytorch基础–torch.Tensor.
torch.randn和torch.rand有什么区别.
pytorch 之 torch.eye()函数.
torch.randint().
torch.stack()的官方解释,详解以及例子.
torch.split().
总结
今天是周五哎,好耶。
-
相关阅读:
[分类讨论]Bit Transmission 2022牛客多校第5场 C
计算机毕业设计springboot+vue基本微信小程序的学生作业管理小程序 uniapp
STM32标准库(固件库)分析
SpringBoot读取properties中配置的List集合
MySQL数据库(基础)
【电路笔记】-欧姆定律
5、超链接标签
MySql——性能分析
腾讯音乐评论审核、分类与排序算法技术
【动态规划专项训练】基础篇
- 原文地址:https://blog.csdn.net/weixin_42475060/article/details/126175837