-
找工作八股文----《操作系统》
系列文章目录
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
《图解网络-小林》学习笔记
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
提示:这里可以添加本文要记录的大概内容:例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
提示:以下是本篇文章正文内容,下面案例可供参考一、硬件结构
- 存储器金字塔
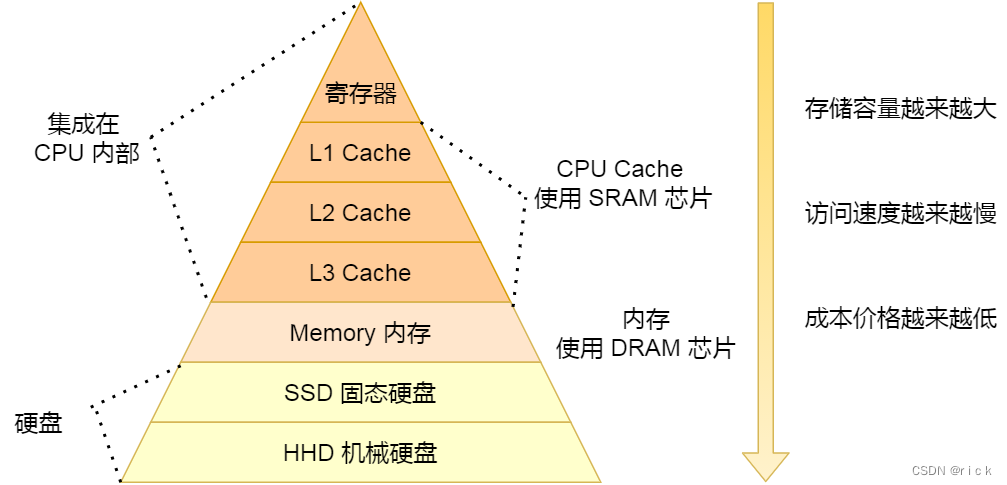
L1 Cache 通常会分为「数据缓存」和「指令缓存」,这意味着数据和指令在 L1 Cache 这⼀层是分
开缓存的
2. CPU缓存各级关系
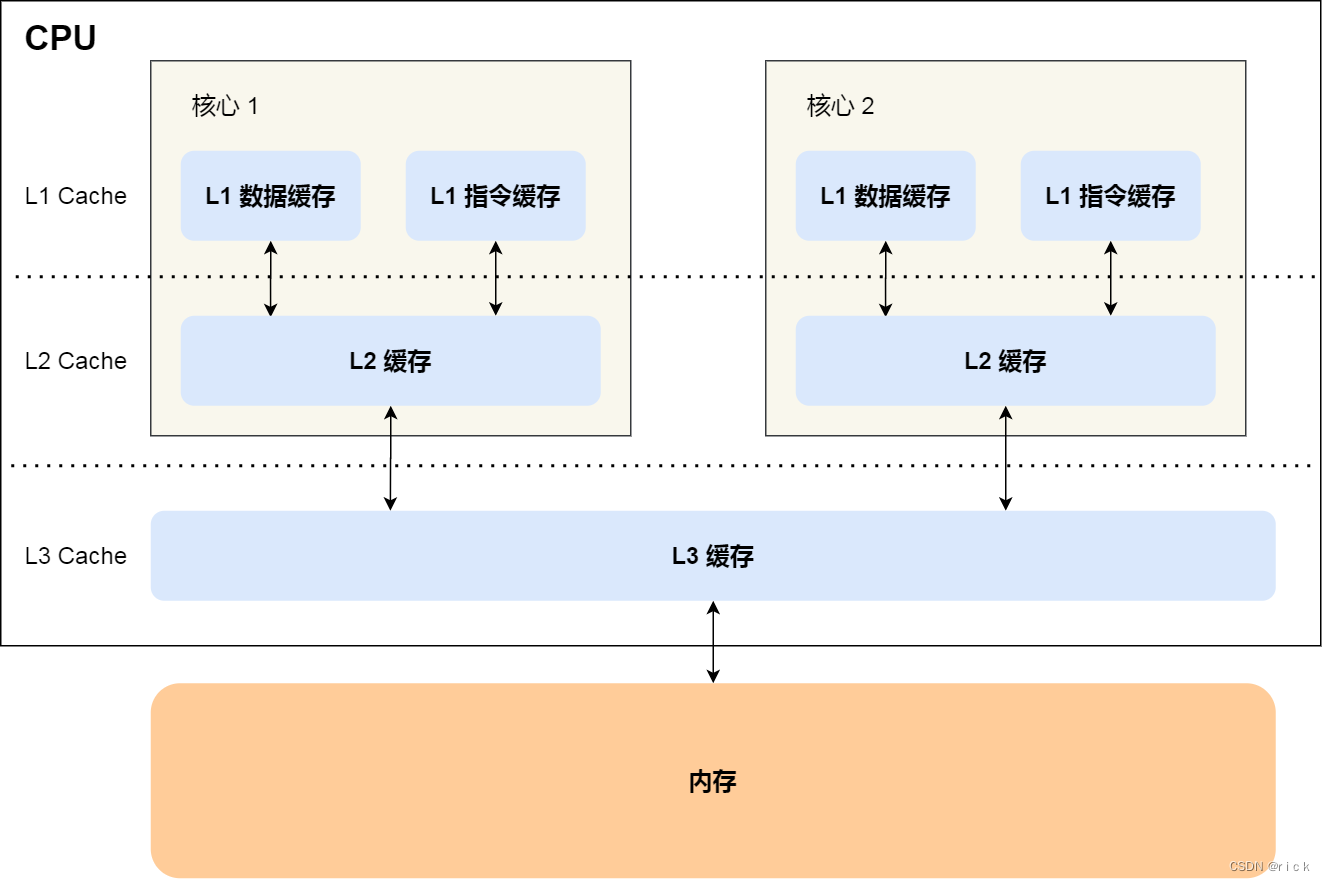
越靠近 CPU 核⼼的缓存其访问速度越快,CPU 访问 L1 Cache 只需要 2~4 个时钟周期,访问 L2 Cache⼤约 10~20 个时钟周期,访问 L3 Cache ⼤约 20~60 个时钟周期,⽽访问内存速度⼤概在 200~300个 时钟周期之间。所以,CPU 从 L1 Cache 读取数据的速度,相⽐从内存读取的速度,会快 100 多倍。
内存地址映射到 CPU Cache 地址⾥的策略有很多种,其中⽐较简单是直接映射 Cache,它巧妙的把内存
地址拆分成**「索引 + 组标记 + 偏移量」**的⽅式,使得我们可以将很⼤的内存地址,映射到很⼩的 CPU
Cache 地址⾥。- 问题来了,那在什么时机才把 Cache 中的数据写回到内存呢?
- 保持内存与 Cache ⼀致性最简单的⽅式是,把数据同时写⼊内存和 Cache 中,这种⽅法称为写直达(Write Through)。
- 软中断
- 为了避免由于中断处理程序执⾏时间过⻓,⽽影响正常进程的调度,Linux 将中断处理程序分为上半部和下
半部: - 上半部,对应硬中断,由硬件触发中断,⽤来快速处理中断;
- 下半部,对应软中断,由内核触发中断,⽤来异步处理上半部未完成的⼯作;
二、操作系统结构
- 三种内核架构
- 宏内核,包含多个模块,整个内核像⼀个完整的程序;
- 微内核,有⼀个最⼩版本的内核,⼀些模块和服务则由⽤户态管理;
- 混合内核,是宏内核和微内核的结合体,内核中抽象出了微内核的概念,也就是内核中会有⼀个⼩型的内核,其他模块就在这个基础上搭建,整个内核是个完整的程序。
Linux 的内核设计是采⽤了宏内核,Window 的内核设计则是采⽤了混合内核。
Linux 可执⾏⽂件格式叫作 ELF,Windows 可执⾏⽂件格式叫作 PE。三、内存管理
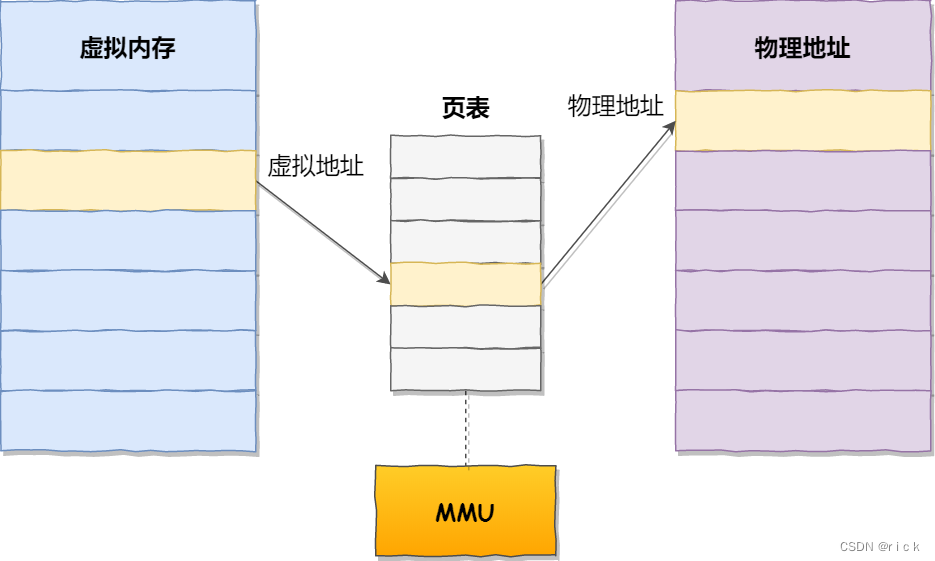
- 操作系统会提供⼀种机制,将不同进程的虚拟地址和不同内存的物理地址映射起来。
如果程序要访问虚拟地址的时候,由操作系统转换成不同的物理地址,这样不同的进程运⾏的时候,写⼊的是不同的物理地址,这样就不会冲突了。 - 我们程序所使⽤的内存地址叫做虚拟内存地址(Virtual Memory Address)。实际存在硬件⾥⾯的空间地址叫物理内存地址(Physical Memory Address)。
- 操作系统是如何管理虚拟地址与物理地址之间的关系?
- 主要有两种⽅式,分别是内存分段和内存分⻚,分段是⽐较早提出的,我们先来看看内存分段。
- 分段的办法很好,解决了程序本身不需要关⼼具体的物理内存地址的问题,但它也有⼀些不⾜之处:
第⼀个就是内存碎⽚的问题。
第⼆个就是内存交换的效率低的问题 - 为了解决内存分段的内存碎⽚和内存交换效率低的问题,就出现了内存分⻚。
分段的好处就是能产⽣连续的内存空间,但是会出现内存碎⽚和内存交换的空间太⼤的问题。
要解决这些问题,那么就要想出能少出现⼀些内存碎⽚的办法。
分⻚是把整个虚拟和物理内存空间切成⼀段段固定尺⼨的⼤⼩。这样⼀个连续并且尺⼨固定的内存空间, 我们叫⻚(Page)。在 Linux 下,每⼀⻚的⼤⼩为 4KB 。
- 段⻚式内存管理
内存分段和内存分⻚并不是对⽴的,它们是可以组合起来在同⼀个系统中使⽤的,那么组合起来后,通常称为段⻚式内存管理。地址结构就由段号、段内⻚号和⻚内位移三部分组成。
段⻚式地址变换中要得到物理地址须经过三次内存访问:
- 第⼀次访问段表,得到⻚表起始地址;
- 第⼆次访问⻚表,得到物理⻚号;
- 第三次将物理⻚号与⻚内位移组合,得到物理地址。
- Linux内存管理
- Linux 内存主要采⽤的是⻚式内存管理,但同时也不可避免地涉及了段机制。
四、进程与线程
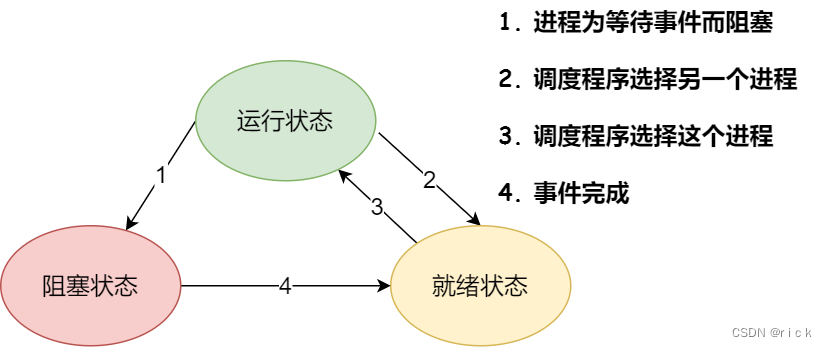
- 当进程要从硬盘读取数据时,CPU 不需要阻塞等待数据的返回,⽽是去执⾏另外的进程。当硬盘数据返回时,CPU 会收到个中断,于是 CPU 再继续运⾏这个进程。
- 在⼀个进程的活动期间⾄少具备三种基本状态,即运⾏状态、就绪状态、阻塞状态。
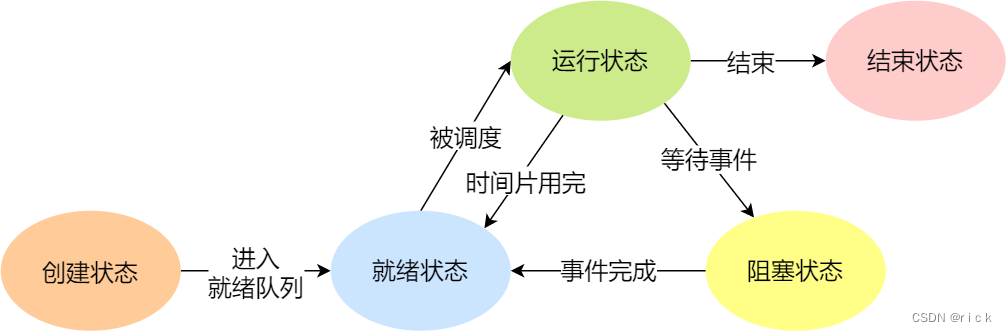
3.进程和线程的区别
线程是调度的基本单位,而进程是资源拥有的基本单位。
4.调度算法
4.1 先来先服务调度算法(First Come First Services FCFS)

每次从就绪队列选择最先进入队列的进程,然后一直运行,直到进程退出或被阻塞,才会继续从队列中选择第一个进程接着运行。- FCFS不利于短作业,当一个长作业先运行了,那么后面的短作业等待的时间就会很长。
- FCFS对长作业有利,适用于CPU繁忙型作业的系统,而不适用于I/0繁忙型作业的系统。
4.2 短作业优先调度算法(Shortest Job First,SJF)
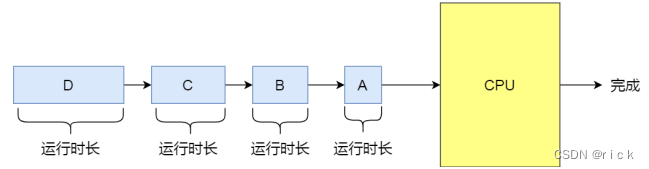
优先选择运行时间最短的进程来运行,有助于提高系统吞吐量。
- SJF不利于长作业,很容易造成一种极端现象。比如,⼀个⻓作业在就绪队列等待运⾏,⽽这个就绪队列有⾮常多的短作业,那么就会使得⻓作业不断的往后推,周转时间变⻓,致使⻓作业⻓期不会被运⾏。
前⾯的「先来先服务调度算法」和「最短作业优先调度算法」都没有很好的权衡短作业和⻓作业
4.3 高响应比优先调度算法(Highest Response Ratio Next, HRRN)
-
HRRN主要是权衡了短作业和长作业。
每次进⾏进程调度时,先计算「响应⽐优先级」,然后把「响应⽐优先级」最⾼的进程投⼊运⾏,

4.4 时间片轮转调度算法(Round Robin,RR)
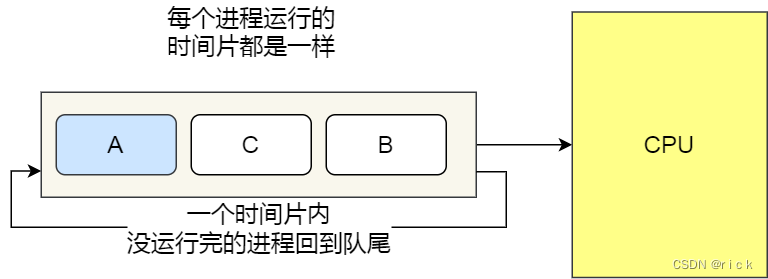
每个进程被分配⼀个时间段,称为时间片(Quantum),即允许该进程在该时间段中运⾏。 -
如果时间⽚⽤完,进程还在运⾏,那么将会把此进程从 CPU 释放出来,并把 CPU 分配给另外⼀个进程;
-
如果该进程在时间⽚结束前阻塞或结束,则 CPU ⽴即进⾏切换;
⼀般来说,时间⽚设为 20ms~50ms 通常是⼀个⽐较合理的折中值
4.5 最高级优先级调度算法(Highest Priority First,HPF)
该算法也有两种处理优先级⾼的⽅法,⾮抢占式和抢占式:- ⾮抢占式:当就绪队列中出现优先级⾼的进程,运⾏完当前进程,再选择优先级⾼的进程。
- 抢占式:当就绪队列中出现优先级⾼的进程,当前进程挂起,调度优先级⾼的进程运⾏。
但是依然有缺点,可能会导致低优先级的进程永远不会运⾏。
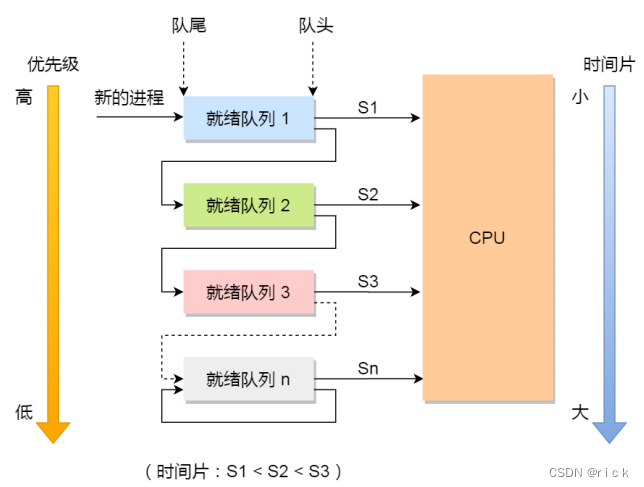
4-6 多级反馈队列调度算法(Multilevel Feedback Queue)
多级反馈队列(Multilevel Feedback Queue)调度算法是「时间⽚轮转算法」和「最⾼优先级算法」的综合和发展。- 「多级」表示有多个队列,每个队列优先级从⾼到低,同时优先级越⾼时间⽚越短。
- 「反馈」表示如果有新的进程加⼊优先级⾼的队列时,⽴刻停⽌当前正在运⾏的进程,转⽽去运⾏优
先级⾼的队列;
面试常见问题
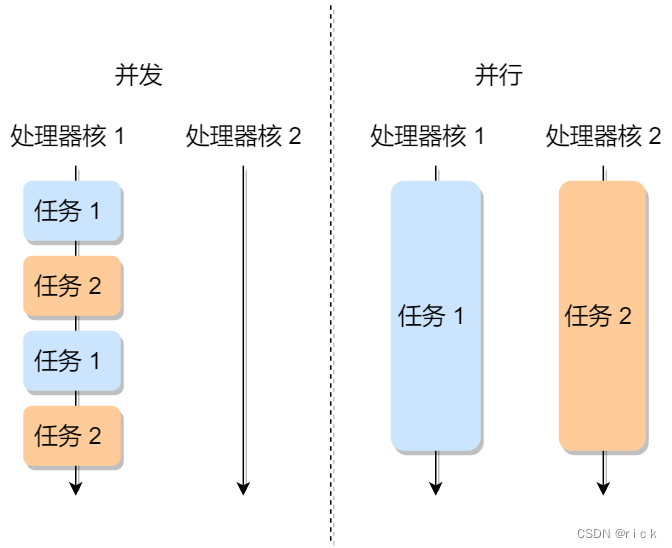
- 并发和并行有什么区别?
4.2 进程间通信
4.2.1 管道
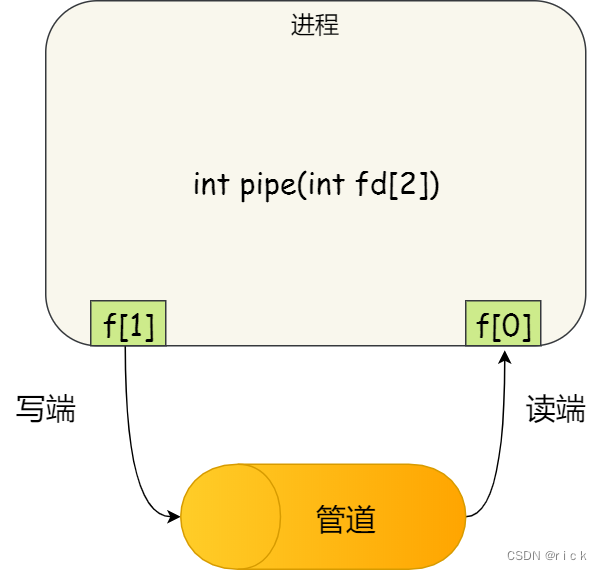
- 所谓的管道,就是内核⾥⾯的⼀串缓存
- 管道的通信⽅式是效率低的,因此管道不适合进程间频繁地交换数据。
4.2.2 消息队列
- 消息队列解决管道通信方式效率低,不适合进程间频繁地交换数据。
- 消息队列的通信模式就可以解决。⽐如,A 进程要给 B 进程发送消息,A 进程把数据放在对应的消息队列后就可以正常返回了,B 进程需要的时候再去读取数据就可以了。同理,B 进程要给 A 进程发送消息也是如此。
- 消息队列⽣命周期随内核,如果没有释放消息队列或者没有关闭操作系统,消息队列会⼀直存在,⽽前⾯提到的匿名管道的⽣命周期,是随进程的创建⽽建⽴,随进程的结束⽽销毁。
消息队列缺点:
- ⼀是通信不及时
- ⼆是附件也有⼤⼩限制,消息队列不适合⽐较⼤数据的传输
4.2.3 共享内存
消息队列的读取和写⼊的过程,都会有发⽣⽤户态与内核态之间的消息拷⻉过程。那共享内存的⽅式,就很好的解决了这⼀问题。- 共享内存的机制,就是拿出⼀块虚拟地址空间来,映射到相同的物理内存中
面试常见问题
1.为什么负数要⽤补码表示?
负数之所以⽤补码的⽅式来表示,主要是为了统⼀和正数的加减法操作⼀样,毕竟数字的加减法是很常⽤的⼀个操作,就不要搞特殊化,尽量以统⼀的⽅式来运算。
2.⼗进制⼩数怎么转成⼆进制?
⼗进制整数转⼆进制使⽤的是「除 2 取余法」,⼗进制⼩数使⽤的是「乘 2 取整法」。
3.计算机是怎么存⼩数的?
计算机是以浮点数的形式存储⼩数的,⼤多数计算机都是 IEEE 754 标准定义的浮点数格式,包含三个部分:
- 符号位:表示数字是正数还是负数,为 0 表示正数,为 1 表示负数;
- 指数位:指定了⼩数点在数据中的位置,指数可以是负数,也可以是正数,指数位的⻓度越⻓则数值的表达范围就越⼤;
- 尾数位:⼩数点右侧的数字,也就是⼩数部分,⽐如⼆进制 1.0011 x 2^(-2),尾数部分就是 0011,⽽且尾数的⻓度决定了这个数的精度,因此如果要表示精度更⾼的⼩数,则就要提⾼尾数位的⻓度;
4. 0.1 + 0.2 == 0.3 吗?
不是的,0.1 和 0.2 这两个数字⽤⼆进制表达会是⼀个⼀直循环的⼆进制数,⽐如 0.1 的⼆进制表示为 0.00011 0011 0011… (0011 ⽆限循环),对于计算机⽽⾔,0.1 ⽆法精确表达,这是浮点数计算造成精度损
失的根源。因此,IEEE 754 标准定义的浮点数只能根据精度舍⼊,然后⽤「近似值」来表示该⼆进制,那么意味着计算机存放的⼩数可能不是⼀个真实值。5.分页是怎么解决分段的内存碎⽚、内存交换效率低的问题?
由于内存空间都是预先划分好的,也就不会像分段会产⽣间隙⾮常⼩的内存,这正是分段会产⽣内存碎⽚的原因。⽽采⽤了分⻚,那么释放的内存都是以⻚为单位释放的,也就不会产⽣⽆法给进程使⽤的⼩内
存。
更进⼀步地,分⻚的⽅式使得我们在加载程序的时候,不再需要⼀次性都把程序加载到物理内存中。我们完全可以在进⾏虚拟内存和物理内存的⻚之间的映射之后,并不真的把⻚加载到物理内存⾥,⽽是只有在程序运⾏中,需要⽤到对应虚拟内存⻚⾥⾯的指令和数据时,再加载到物理内存⾥⾯去。6、分页机制下,虚拟地址和物理地址是如何映射的?
在分⻚机制下,虚拟地址分为两部分,⻚号和⻚内偏移。⻚号作为⻚表的索引,⻚表包含物理⻚每⻚所在
物理内存的基地址,这个基地址与⻚内偏移的组合就形成了物理内存地址。
总结⼀下,对于⼀个内存地址转换,其实就是这样三个步骤:- 把虚拟内存地址,切分成⻚号和偏移量。
- 根据⻚号,从⻚表⾥⾯,查询对应的物理⻚号。
- 直接拿物理⻚号,加上前⾯的偏移量,就得到了物理内存地址。
总结
提示:这里对文章进行总结:例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
-
相关阅读:
springAOP面试题
【计算机毕业设计】基于SpringBoot的电影在线预定与管理系统的设计与实现
Layui 2.8.0 正式发布,官网全新文档站朴实归来
在基于ABP框架的前端项目Vue&Element项目中采用电子签名的处理
基于IDEA的Maven(依赖介绍和引用)
SoC和微控制器(MCU)
认识ICMP协议 —— ping命令的作用过程
WPF异步编程
GoLand2022.2.5版本Hello调动Greetings包
机器学习-无监督算法之降维
- 原文地址:https://blog.csdn.net/xiaoren886/article/details/126121426