主从库集群
Redis 提供了主从库模式,以保证数据副本的一致,在从库执行一下命令可以建立主从库关系:
replicaof
Redis 的主从库之间采用的是读写分离的方式:
- 读操作:主库、从库都可以接收;
- 写操作:到主库执行,然后将写操作同步给从库。
写操作只在主库执行,主要是为了避免多实例写导致的数据一致性问题,减少多实例之间数据一致的协商开销。
主从同步是如何进行的
下图是主从第一次同步的流程:
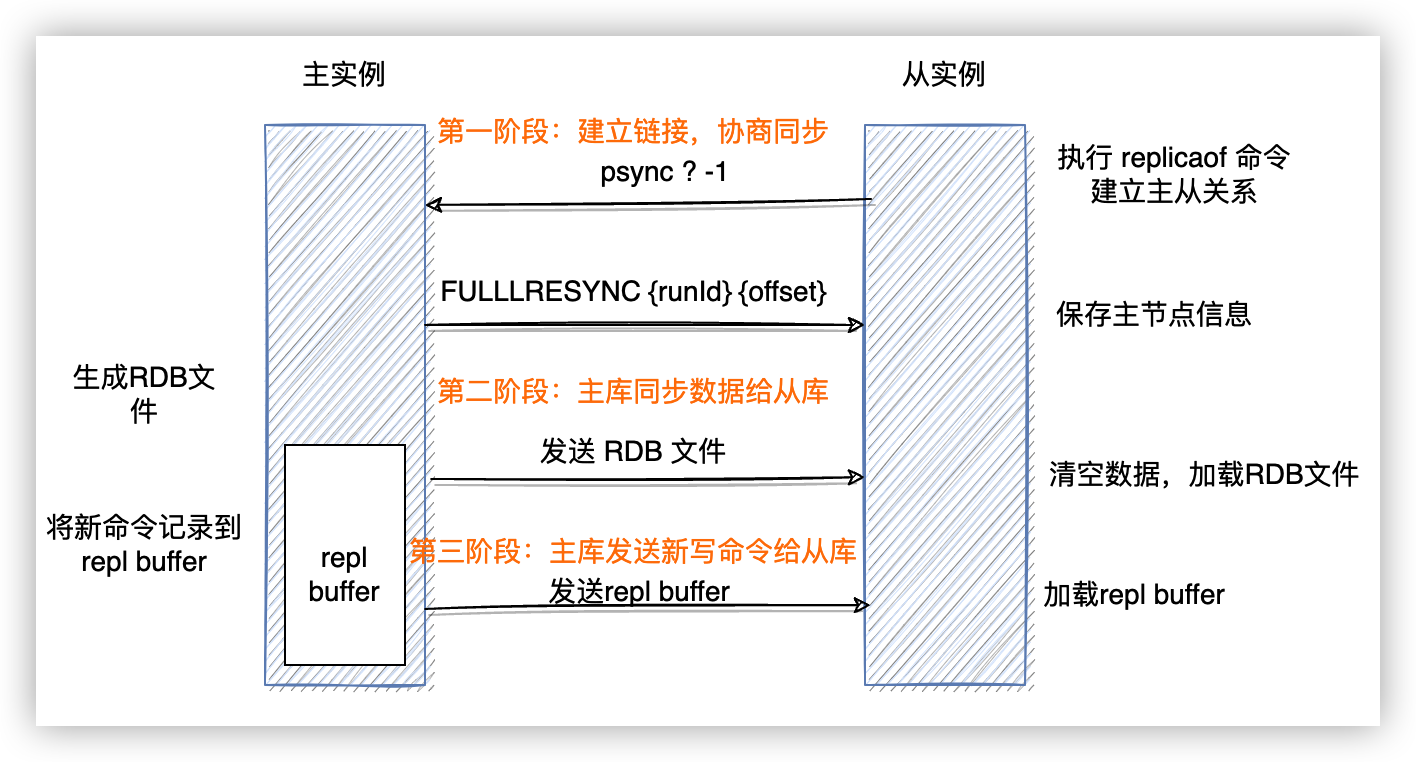
第一阶段
第一阶段,从库会给主库发送 psync 命令,类似 tcp 的握手,该命令有两个参数:主库的 runid 和复制进度 offset。
- runid 是每个 Redis 实例启动时都会自动生成的一个随机 ID,用来标记这个实例。从库第一次和主库同步时,不知道主库的 runid ,所以将 runid 设置为 “?”;
- offset 是从库到目前为止处理的偏移量,第一次同步的时候会传 -1 。
收到 psync 命令后,主库会用 FULLRESYNC 响应带上主库 id 和当前的复制进度 offset 返回给从库,从库会记录这两个参数。
第二阶段
主库在收到 psync 后,会执行 bgsave 命令,生成 RDB 文件,然后将文件发送给从库。从库收到文件后,会先情况当前的数据,然后加载 RDB 文件。
第三阶段
在从库处理完 RDB 文件时,主库会将期间处理的写操作放在 replication buffer 中,等到从库处理完 RDB 文件后,主库会将修改操作都发送给从库执行,从而完成主从同步。
基于长连接的命令传播
主从库的连接建立成功,并且完成第一次的全量同步之后,主从库之间会维持一个长链接,主库会将之后接收到的写操作同步给从库。
增量同步
在使用过程中,可能会出现主从库之间网络闪断的情况,如果恢复连接后采用全量同步的方式,必然会有很大的开销。Redis 2.8 之后,采用增量同步的方式来完成这个操作。
当主从断连之后,主库会把期间收到的写操作命令写入 replication buffer,同时也会把这些操作命令也写入 repl_backlog_buffer 这个缓冲区。
repl_backlog_buffer 是一个环形缓冲区,主库会记录自己的偏移量 master_repl_offset,从库会记录自己的偏移量 slave_repl_offset。用命令 info Replication 可以查看对应的 offset。
主从库恢复连接后,从库会用 psync 发送自己的 slave_repl_offset 给主库,主库对比自己的 master_repl_offset ,将两个 offset 之间的写操作同步给从库。
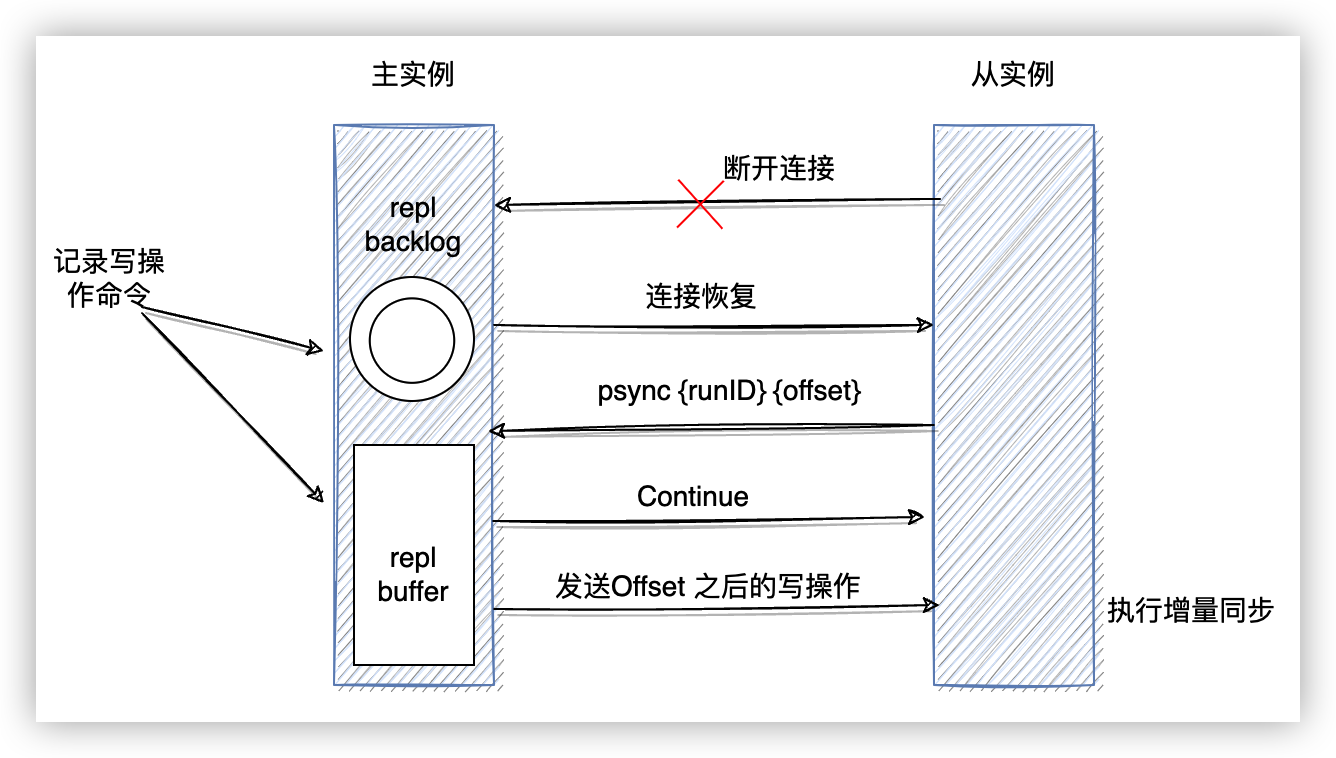
因为 repl_backlog_buffer 是一个环形队列,所以,如果从库的读取速度比较慢,就有可能导致从库还未读取的操作被主库新写的操作覆盖,如果主库接收从库的 psync 时发现从库的 offset 已经被覆盖,为了不丢失数据那么就会发起全量同步。为了避免全量同步,这时候就需要增加 repl_backlog_size 的值,这个值和缓冲空间大小有关,缓存空间大小 = 主库写入命令速度 * 操作大小 - 主从库间网络传输命令速度 * 操作大小 。考虑到突发压力,通常 repl_backlog_size 会设置为 计算结果的 2 到 4 倍。
级联主从
如果一个主库下有很多的从库,这些从库都要和主库进行全量同步的时候,主库的压力会非常大,忙于 fork 子进程生成 RDB 文件,影响主线程处理客户端请求。这是可以将主从结构改成主→ 从 → 从 的联机结构,缓解主库的压力。
实验
我们可以用 docker-compose 实验 Redis 主从同步:
version: "3"
services:
redis-master:
image: redis:7
ports:
- "16379:6379"
container_name: "redis-master"
command: redis-server
networks:
- redis-replica
redis-slave-1:
image: redis:7
ports:
- "6380:6379"
container_name: "redis-slave-1"
command: redis-server --replicaof redis-master 6379
depends_on:
- redis-master
networks:
- redis-replica
redis-slave-2:
image: redis:7
ports:
- "6381:6379"
container_name: "redis-slave-2"
command: redis-server --replicaof redis-slave-1 6379
depends_on:
- redis-slave-1
networks:
- redis-replica
networks:
redis-replica:
这里定义了一个主库 redis-master 以及两个从库 redis-slave-1、redis-slave-2。它们是一个级联的主从关系 redis-master ← redis-slave-1 ← redis-slave-2
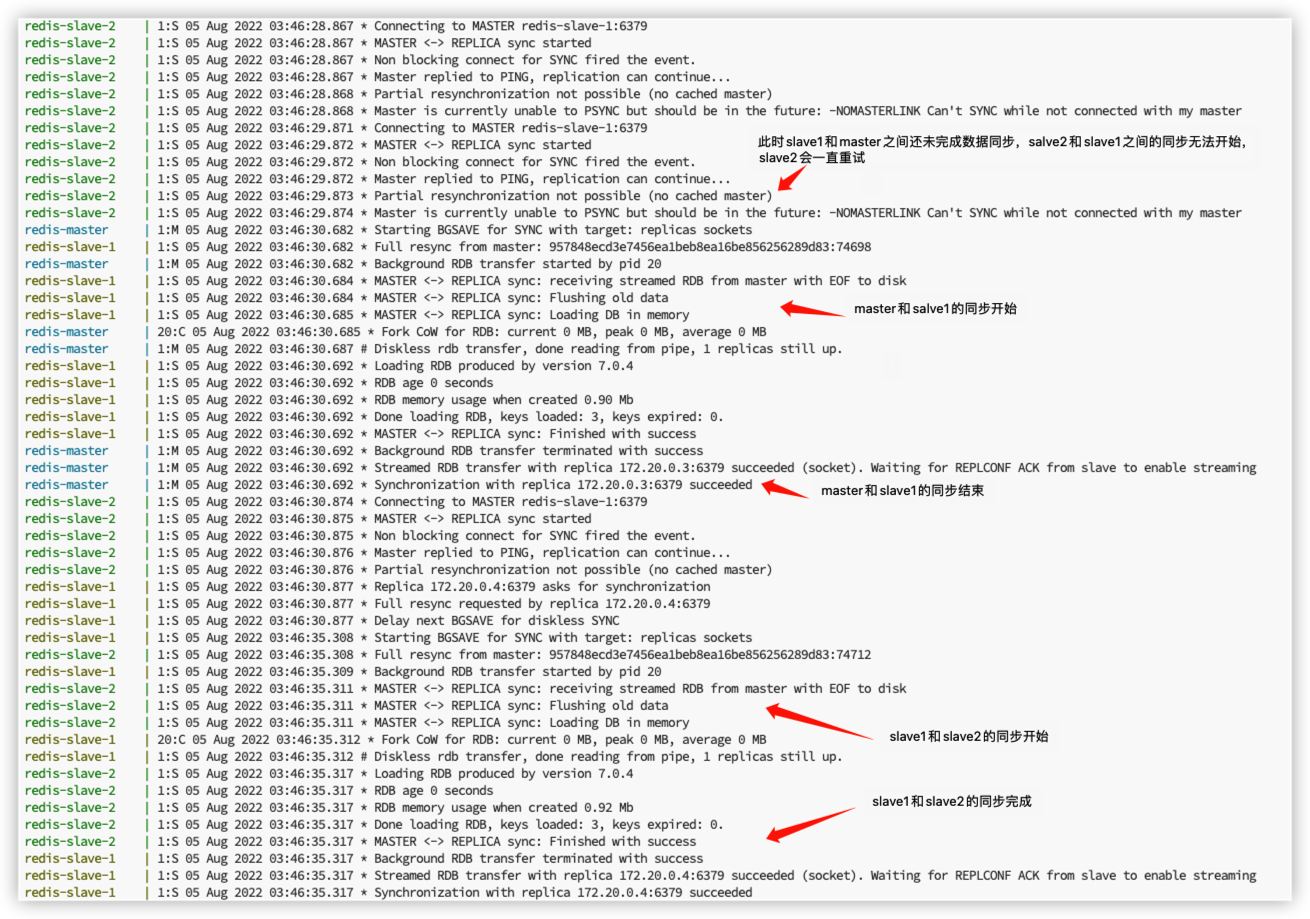
我预先在 master 中插入了一些数据之后在设置了两个 slave 节点。启动之后,可以看到 slave2 先向 salve1 发起了同步请求,但是 slave1 还没和 master 完成同步,所以 salve2 一直在重试,直到 salve1 和 master 完成同步后才开始 slave2 和 salve1 之间的数据同步。