-
正则表达式实战
正则在实际中太多时候用到了,但还没有系统梳理过,把一些正则参考实际经常用到的写一个简单的手册。
一、正则表达式简介
正则表达式(Regular Expression)是用于描述一组字符串特征的文本模式,用来匹配特定的字符串。通过特殊字符(称为“元字符”)+普通字符(例如,a 到 z 之间的字母)来进行模式描述,从而达到文本匹配一个或多个字符串。
正则表达式目前被集成到了各种文本编辑器/文本处理工具当中
应用场景
(1)验证:表单提交时,进行用户名密码的验证。
(2)查找:从大量信息中快速提取指定内容,在一批url中,查找指定url。
(3)替换:将指定格式的文本进行正则匹配查找,找到之后进行特定替换。
二、正则表达式基本要素
(1)字符类
(2)数量限定符
(3)位置限定符
(4)特殊符号
注意:正则表达式基本是与语言无关的,我们可以结合语言/工具与正则表达式进行文本处理,在后面的博客中,我将使用grep来进行验证。(grep是一款Linux下按行匹配文本的工具,如下,使我们常使用的两个选项)
-E:使用扩展正则匹配
--color:将匹配得到的内容进行语法高亮
1. 字符类

字符组
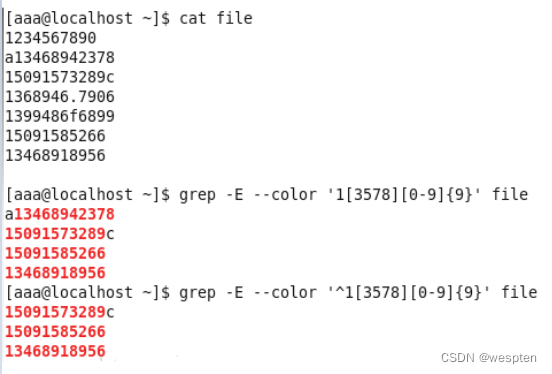
正则 解释 [aA] 字符组[] 允许匹配一组可能出现的字符,如:[jJ]ava 表示匹配java或者Java [0-9] 字符-代表区间,如:[0-9a-zA-Z] 表示匹配任意大小写字母数字 \ 对特殊符号进行转义,如: [\<\>]表示匹配<>尖括号^ 实现取反操作,如:[^a-z] 表示匹配不包含小写字母的字符 字符串
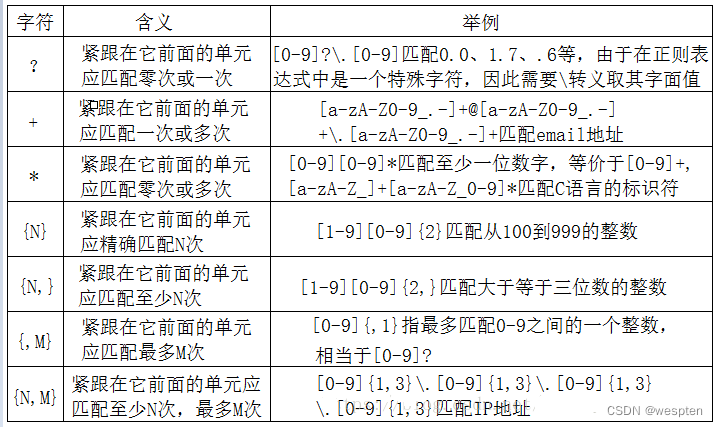
正则 解释 ^ 匹配一个字符串的开始 $ 匹配一个字符串的结束 . 匹配任何一个字符,注意:它只能出现在方括号以外,但是匹配的时候不包括\n ? 匹配可选字母,即出现该字母为一次或零次 + 匹配必须至少出现一次的字符,即一次或多次 * 匹配必须至少出现零次的字符,即零次或多次 {n} 匹配n次 {n,m} 匹配n次到m次 "^The":表示所有以"The"开始的字符串("There","The cat"等);
"of despair$":表示所以以"of despair"结尾的字符串;
"^abc$":表示开始和结尾都是"abc"的字符串——呵呵,只有"abc"自己了;
"notice":表示任何包含"notice"的字符串。"ab*":表示一个字符串有一个a后面跟着零个或若干个b。("a", "ab", "abbb",……);
"ab+":表示一个字符串有一个a后面跟着至少一个b或者更多;
"ab?":表示一个字符串有一个a后面跟着零个或者一个b;
"a?b+$":表示在字符串的末尾有零个或一个a跟着一个或几个b。"ab{2}":表示一个字符串有一个a跟着2个b("abb");
"ab{2,}":表示一个字符串有一个a跟着至少2个b;
"ab{3,5}":表示一个字符串有一个a跟着3到5个b。"hi¦hello":表示一个字符串里有"hi"或者"hello";
"(b¦cd)ef":表示"bef"或"cdef";
"(a¦b)*c":表示一串"a""b"混合的字符串后面跟一个"c";"a.[0-9]":表示一个字符串有一个"a"后面跟着一个任意字符和一个数字;
"^.{3}$":表示有任意三个字符的字符串(长度为3个字符);"[ab]":表示一个字符串有一个"a"或"b"(相当于"a¦b");
"[a-d]":表示一个字符串包含小写的'a'到'd'中的一个(相当于"a¦b¦c¦d"或者"[abcd]");
"^[a-zA-Z]":表示一个以字母开头的字符串;
"[0-9]%":表示一个百分号前有一位的数字;
",[a-zA-Z0-9]$":表示一个字符串以一个逗号后面跟着一个字母或数字结束。举例如下:
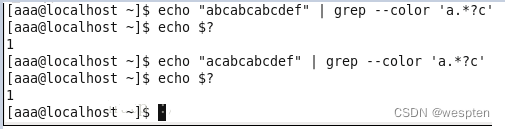
例1:

注意:1.grep采用的贪心匹配,它会匹配当前行中的所有匹配内容
2.echo $?表示是否匹配成功(如果成功返回值为0,不成功返回值为1)
例2:
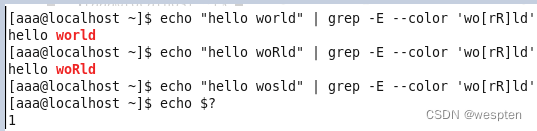
例3:
例4:
例5:

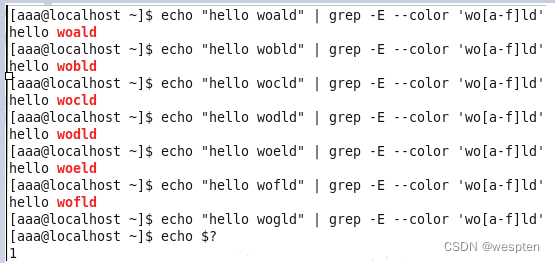
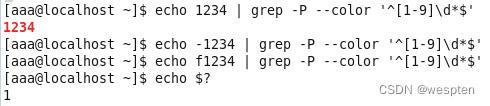
2. 数量限定符
举例如下:
例1:
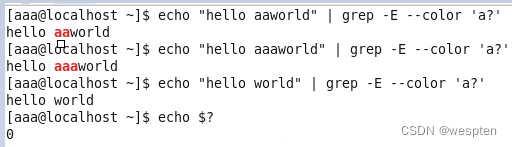
例2:
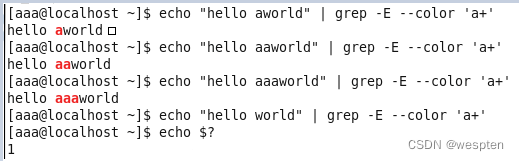
由此,我们可以看出,“前面的单元”默认是指?或+前面的字符。
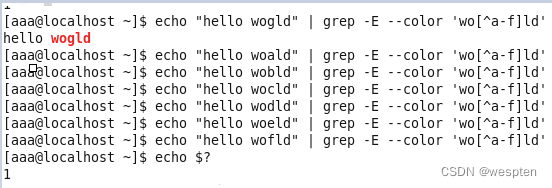
例3:

例4:
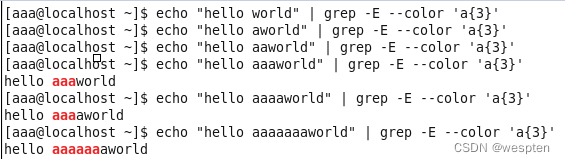
例5:

例6:

注意:该结果为匹配失败,在相关文档中并未出现,应该啊是错误或者废弃的用法
例7:

3. 位置限定符
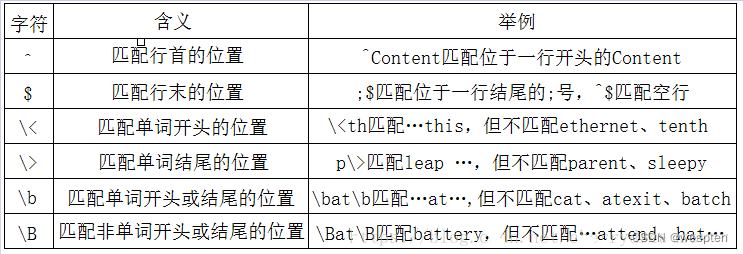
举例如下:
例1:

例2:

例3:

例4:
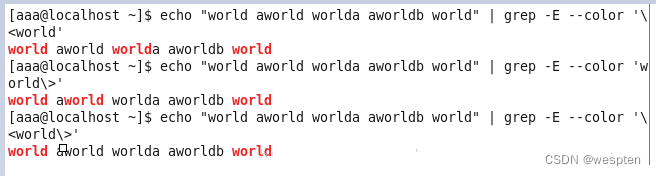
例5:

例6:
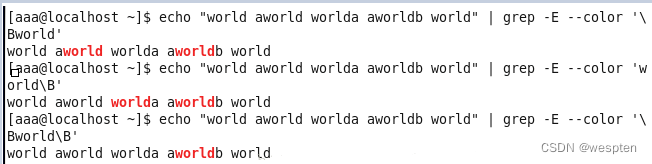
4. 特殊符号
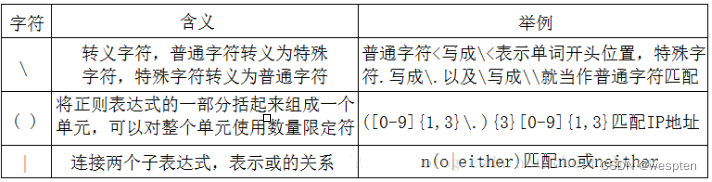
举例如下:

假如我们去掉-E选项,会有什么现象呢?

此时,不难发现,去掉-E选项之后没有进行正常的正则匹配,这种现象需要我们引入如下的两个概念!
5. 基本正则表达式&扩展正则表达式
区别:正则表达式的扩展正则(Extended规范)和基本正则(Basic规范)下,有些字符应该解释为普通字符,要表示上述特殊含义则需要加“\”转义字符。反之,在扩展规范下,应被理解为特殊含义,要取其字面值,也要对其进行“\”转义。
因此,grep工具带上-E选项,表示使用扩展正则来进行匹配,若没有该选项,则表示使用基准正则来进行匹配。
对于上述的问题,我们举例如下:
例1:

例2:当目标字符串当中本身就包含了
 字符,要想进行正则匹配,应该这样做:
字符,要想进行正则匹配,应该这样做:
例3:

5. 其他普通字符集及其替换
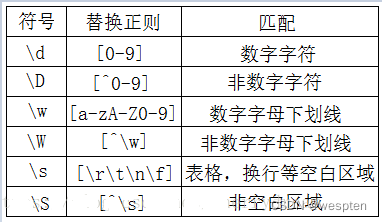
举个例子:

综上,正则表达式有以下三个分类:
(1)基本正则表达式:Basic即BPEs
(2)扩展正则表达式:Extended即EREs
(3)Perl的正则表达式:PREs
因此,当grep指令不跟任何参数时,表示要使用BREs,后面跟“-E”表示使用EREs,后面跟“-P”参数,表示使用PREs
三、正则表达式高级应用
分组
正则 解释 () 表示捕捉匹配到的数据,如 (.*?)(\d{4}) 表示匹配4个数字 (\d{1,2}) 表示匹配到提取的1个到2个数字 (?:code) 非捕捉分组,匹配code但不获取 看个实例:匹配并提取下面的数字。
就可以有多种写法,
第一种写法:(?:\d+|tel)[\-\:](\d{5})表示先匹配到数字或者tel字符,接着匹配-和:,最后提取五位数字。
第二种写法,(?:.+)[-:](\d{5})表示直接匹配到-和:,再提取五位数字。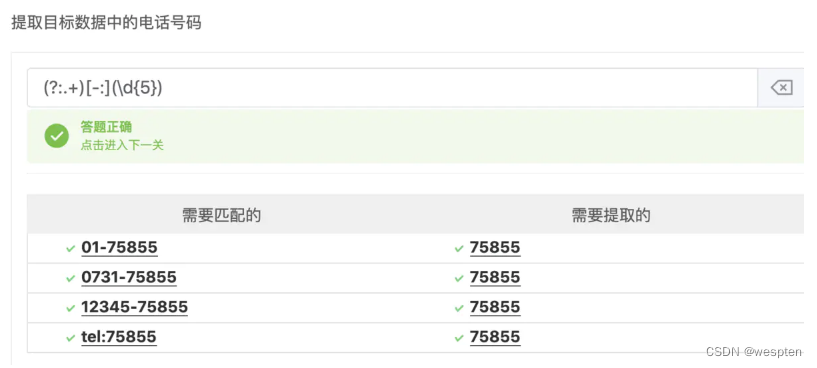
先行断言、后行断言
正则 解释 \x 分组的回溯调用,匹配某种之前的规则。如 (\w)(\w)\2\1表示匹配某种AB-BA对称组合,注意加括号(?=表达式) 表示匹配到所在位置右侧的表达式。如 (?=.*?[a-z])表示匹配至少一个小写的字符串(?!表达式) 表示右边不能出现某字符。如: \w+@(?!qq.com)表示匹配不是qq邮箱(?<=表达式) 表示匹配到所在位置左侧的表达式,如: (?<=王).+就表示匹配王姓名字(? 指在某个位置向左看,表示所在位置左侧不能匹配到表达式,如: ^\$.*?(? 表示匹配两个$$之间的数据再看个匹配小数的实例。
写法一:
(? 表示从小数点左边匹配。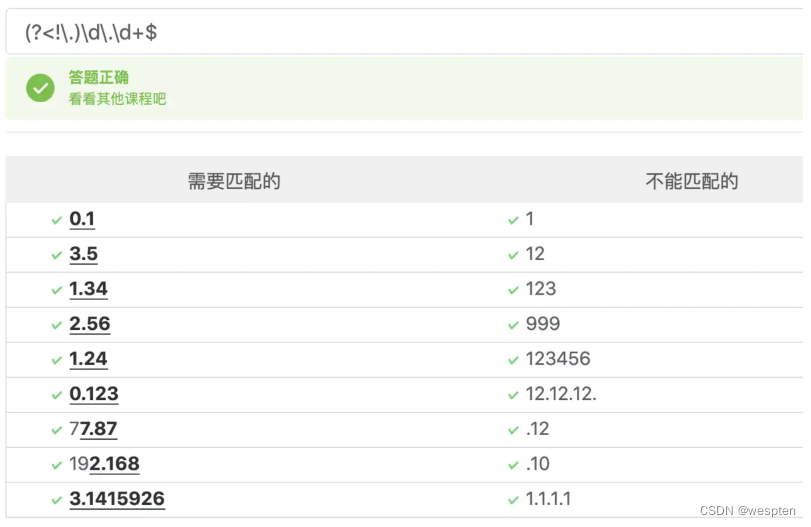
写法二:
^\d+\.(?!\.)\d+$表示从小数点右边匹配。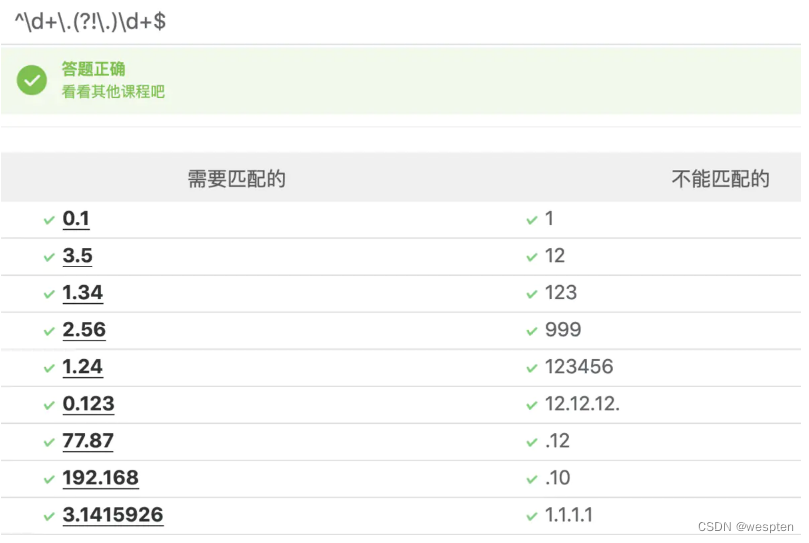
结合上面两种写法,就可以总结出小数点的左右两边都不能再有小数点的写法:
\d(?贪婪模式与非贪婪模式
1.贪婪模式:正则表达式匹配时,会尽量多的匹配符合条件的内容
举例如下:

注意:grep默认采用贪婪匹配,可能会对我们的测试结果造成干扰,大家可以上网使用“正则在线转换工具”进行测试
2.非贪婪模式:正则表达式匹配时,会尽量少的匹配符合条件的内容,也就是说,一旦发现匹配符合要求,立马就匹配成功,而不会继续匹配下去(除非有g,开启下一组匹配)
举例如下:
零宽断言
正则 解释 \w 表示匹配包括下划线的任何单词字符,等价于[A-Za-z0-9_] \d 表示匹配任意数字,等价于[0-9] \s 表示匹配空白字符,如:空格、tab、换行等 \b 表示匹配单词的边界,如:\bcode\b 匹配code.xxxx,xxx.code 取反 \w 将小写改为大写即可\W,如:不以字母开头,[^\w] 1.所谓断言,是用来声明一个应该为真的事实。在正则表达式中,只有当断言为真时才会继续进行匹配。
2.零宽断言:像用于查找某些内容之前或者之后的东西,其中一些特殊字符如“\b、^、$”等用于指定一个位置,这个位置应满足一定的条件。
3.分类:
(1)零宽度正预测先行断言(?=exp)
它断言自身出现的位置之后能匹配的表达式exp。如:\b\w+(?=ing\b),表示匹配以ing结尾的单词的前面的部分(除ing以外的部分)。当我们要查找“I'm singing while you're dancing.”时,它会匹配sing和danc
举例如下:

(2)零宽度正回顾后发断言(?>=exp)
它断言自身出现的位置的前面能匹配的表达式exp。如:(?<=\bre)\w+\b会匹配以re开头的单词的后半部分(除er以外的部分),例如:在查找“reading a book”时,它匹配ading
举例如下:

四、正则表达式案例
1. 手机号码
2. 非零的正整数
3. 非零开头的最多带两位小数的数字

4. 由数字和26位字母组成的字符串

5. QQ号,从10000开始

6. IP地址
\d+\.\d+\.\d+\.\d+7.判断账号是否合法
^[a-zA-Z0-9][a-zA-Z0-9_]{4,15}$8.日期格式
^\d{4}-\d{1,2}-\d{1,2}更多正则:
正则 解释 ^1[3-9]\d{9}$ 匹配手机号码。以1开头的九位纯数字,第二位为3到9数字。 ((25[0-5]|2[0-4]\d|1\d{2}|[1-9]?\d)\.){3}(25[0-5]|2[0-4]\d|1\d{2}|[1-9]?\d)\:\d.+$ 匹配IP地址和端口 ((25[0-5]|2[0-4]\d|1\d{2}|[1-9]?\d)\.){3}(25[0-5]|2[0-4]\d|1\d{2}|[1-9]?\d) 匹配IP地址,注意IP的地址的取值区间,具体写法参考: https://www.cnblogs.com/FashionDoo/p/10685631.html ^(http(s)?:\/\/)\w+[^\s]+(\.[^\s]+){1,}[\/] 匹配域名地址,http://xxx.xxx.xxx.xx/ ^(http(s)?:\/\/)\w+[^\s]+(\.[^\s]+){1,}[\/].+ 匹配url地址,http://xxx.xxx.xxx.xx/xxx [1-9][0-9,X]{14,17} 匹配身份证号码 \n\s*\r 匹配空白行 ^\s*|\s*$ 匹配首尾的空格 \b[kK][eE][yY]\b 匹配私钥key字符 \w+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+) 匹配邮箱 [a-zA-Z]:[\\/]{1,2}(?:[a-zA-Z0-9\.\-_ ]+[\\/]{1,2})*([a-zA-Z0-9\.\-_ ]+) 匹配windows绝对地址 五、正则在线验证网址
https://regexr-cn.com/
https://tool.oschina.net/regex/#
https://www.codejiaonang.com/#/course/regex_chapter1/0/7
https://ihateregex.io/ -
相关阅读:
SpringCloud——Gateway(Predicate断言工厂、Filter过滤器工厂、token校验)
SpringBoot基础
day-3-2-3
final语法
带宽优化新思路:RoCE网卡聚合实现X2增长
Java 多线程:基础
JuiceFS 在多云架构中加速大模型推理
Windows bat 脚本注册系统服务教程详解
实现阿里云模型服务灵积 DashScope 的 Semantic Kernel Connector
简述数据中心网络的特点,数据中心网络规划设计
- 原文地址:https://blog.csdn.net/qq_35029061/article/details/126170636