-
Zookeeper原理(data tree结构、工作原理、架构、应用场景)

Zookeeper
ZooKeeper 是 Apache 软件基金会的一个软件项目,它为大型分布式计算提供开源的分布式配置服务、同步服务和命名注册等。
1. 数据结构(data tree)
zookeeper 提供的名称空间非常类似于标准文件系统,key-value 的形式存储。名称 key 由斜线 / 分割的一系列路径元素,zookeeper 名称空间中的每个节点都是由一个路径标识。zookeeper使用的数据模型是树形结构,与Unix文件系统很像。
在内存中,zookeeper存储了整棵树的内容,包括所有的数据节点路径、节点数据、ACL信息,zookeeper会定时将这个数据存储到磁盘上。zookeeper的数据节点和分布式服务中实例可以实现一一对应的关系。
每一个数据节点默认最大存储1MB的数据。
每个数据节点的路径名是唯一的,不允许重复,可以通过路径名唯一标识一个数据节点。

相关 CAP 理论
CAP 理论指出对于一个分布式计算系统来说,不可能同时满足以下三点:
-
一致性:在分布式环境中,一致性是指数据在多个副本之间是否能够保持一致的特性,等同于所有节点访问同一份最新的数据副本。在一致性的需求下,当一个系统在数据一致的状态下执行更新操作后,应该保证系统的数据仍然处于一致的状态。
-
可用性:每次请求都能获取到正确的响应,但是不保证获取的数据为最新数据。
-
分区容错性:分布式系统在遇到任何网络分区故障的时候,仍然需要能够保证对外提供满足一致性和可用性的服务,除非是整个网络环境都发生了故障。
一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。
在这三个基本需求中,最多只能同时满足其中的两项,P 是必须的,因此只能在 CP 和 AP 中选择,zookeeper 保证的是 CP,对比 spring cloud 系统中的注册中心 eruka 实现的是 AP。

2. 工作原理
zookeeper工作原理就是接收所有分布式节点上报的数据,根据既定的算法进行存储和清理,进而达到动态感知和协调各个节点工作的目的。从设计模式的角度看,zookeeper是一个基于观察者模式设计的分布式服务协调框架,负责存储和管理分布式服务关心的数据,在数据发生变化时,通知给已经注册的观察者。
zookeeper约等于一个文件管理系统+通知框架的组合。
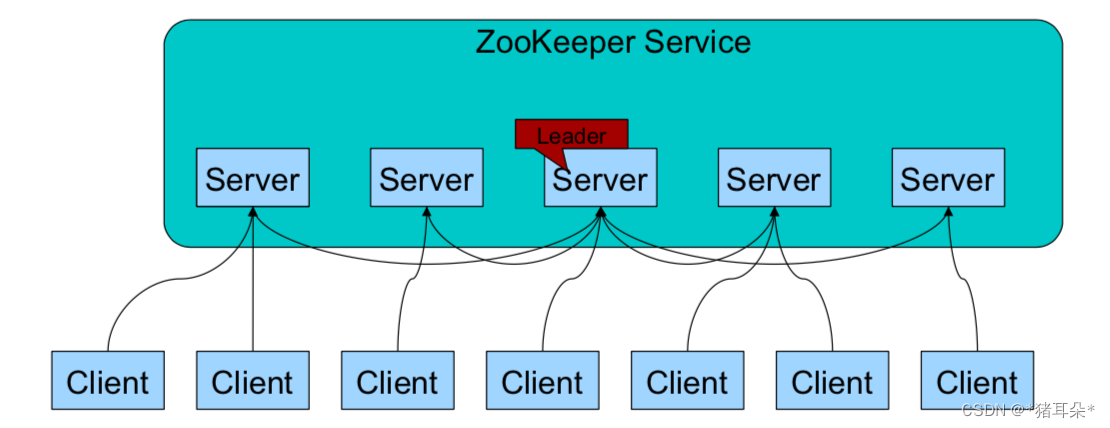
3. 架构
zookeeper在设计之处的目的之一就是要解决单点故障问题,所以zookeeper是支
持集群部署的服务。
- zookeeper集群中,有且只有一个leader,其他都是follower。
- zookeeper集群中,只有半数以上节点存活,才能正常工作,如6个节点,挂了3个,集群就瘫痪,5个节点,挂了3个,集群就瘫痪,从这个角度讲,部署6台并没有比部署5台可靠性增加,所以,zookeeper建议集群中节点数量为基数。
- 全局数据一致,每个节点的数据都一样,客户端无论连接哪个节点,读取的数据都是一致的。
- 来自同一个客户端的更新请求,按顺序执行。
- 数据更新保证原子性。
- 实时性,保证在很短时间内,客户端能读到最新数据。
4. 应用场景
- 统一命名服务
- 统一配置管理
- 统一集群管理
- 服务器节点上下线及时感知
参考:https://blog.csdn.net/tales522/article/details/123319268
分布式环境下,经常需要对服务进行统一命名,便于识别,一个服务就是一个IP地址。统一配置管理实现时,可将配置文件写入zookeeper的一个数据节点中,所有客户端监听这个节点变化,就能够做到准实时同步配置的效果了。
分布式环境中,实时掌握每个服务的状态是必须的,可以将每个服务的信息写入zookeeper的一个数据节点上,监听zookeeper的数据节点就能动态感知服务的变化。
分布式服务中服务的上下线状态也是一个非常重要的关注指标,zookeeper能够实现这种感知。
END
-
-
相关阅读:
CentOS 7设置固定IP地址
抽象工厂模式
Linux常见概念及命令介绍
“蔚来杯“2022牛客暑期多校训练营3
文本情感计算技术(深度)
心血管疾病预测--逻辑回归实现二分类
JVM - 内存模型
apple-app-site-association nginx
Day27.组合总和II、分割回文串
flutter EventBus
- 原文地址:https://blog.csdn.net/cjw12581/article/details/126040929