-
第七天项目实战一
电信运营商用户流失名单预测
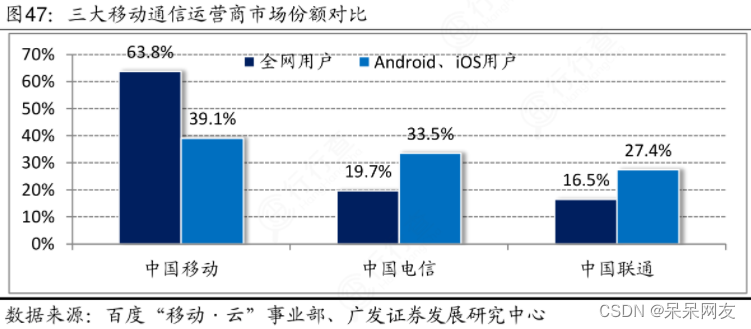
项目背景
国内通信市场逐渐的成熟,三大运营商营销模式业务日益趋同,竞争压力比较大,高新增用户已经成为过去式,用户的流失率提高已经成为普遍现象。在通信市场上,电信运营商面临竞争者之间的强大挑战。如何提高用户的满意度,降低流失率成为主要问题,有效的发展客户,进而提高收入,成为了电信运营商运营管理者的主要问题。
需求拆解
用户流失的原因:信号不稳定,网速慢,价格不划算
交付:每周提交一次用户流失概率比较大的人员名单收集数据
价格不划算: 套餐价格(对比竞品)
超出套餐部分的通话费用比较贵:对即将超出套餐的进行提醒,并合理推荐套餐
超出套餐部分的流量费用比较贵:对即将超出套餐的进行提醒,并合理推荐套餐这里整理了一份电信运营商都数据,数据字段格式如下,我们先将数据读入内存:
import pandas as pd data = pd.read_excel('CustomerSurvival.xlsx') data.head()- 1
- 2
- 3
数据处理
缺失值
可见数据不存在缺失值,这里就不需要进行特殊处理了,下面进行异常值的处理
data.info() <class 'pandas.core.frame.DataFrame'> RangeIndex: 4975 entries, 0 to 4974 Data columns (total 10 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 ID 4975 non-null int64 1 套餐金额 4975 non-null int64 2 额外通话时长 4975 non-null float64 3 额外流量 4975 non-null float64 4 改变行为 4975 non-null int64 5 服务合约 4975 non-null int64 6 关联购买 4975 non-null int64 7 集团用户 4975 non-null int64 8 使用月数 4975 non-null int64 9 流失用户 4975 non-null int64 dtypes: float64(2), int64(8) memory usage: 388.8 KB- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
异常值
data['额外通话时长'].quantile([0,0.25,0.5,0.75,1]) 0.00 -2828.333333 0.25 -126.666667 0.50 13.500000 0.75 338.658333 1.00 4314.000000 Name: 额外通话时长, dtype: float64 (data['额外通话时长'] > 339).sum() 1241- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
可见四分位数中存在差值较大的情况,同时看到时常超过339的也很多,所以我们将范围超过3000的数据作为异常数据处理。
# 在业务指标值中,认定超过3000,或者剩余3000为异常值 data = data[data['额外通话时长'] < 3000] data = data[data['额外通话时长'] > -3000]- 1
- 2
- 3
特征工程
# 删除ID列,这一列与结果无关,所以属于无用列,我们进行删除 del data['ID'] # 连续数据,离散化 extra_time_cut = [[-3000,-1000,0,1000,3000],[2,4,3,1]] data['额外通话时长'] = pd.cut(data['额外通话时长'], bins=[-3000,-1000,0,1000,3000], labels=[2,4,3,1]) data['额外流量'] = np.where(data['额外流量']>0,2,1)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
模型选择
# 单科决策树,Adaboost,GBDT,随机森林 (谁好选谁) import sklearn.model_selection as ms #模型选择 import sklearn.tree as st #决策树 import sklearn.ensemble as se #集成学习 import sklearn.metrics as sm #评估模块 # 整理输入和输出 x = data.iloc[:,:-1] y = data.iloc[:,-1] train_x,\ test_x,\ train_y,\ test_y = ms.train_test_split(x,y, test_size=0.1, random_state=7, stratify=y) def select_model(name,model): print('--------',name,'----------') model.fit(train_x,train_y) pred_test_y = model.predict(test_x) print(sm.classification_report(test_y,pred_test_y)) model_dict = {'单颗决策树':st.DecisionTreeClassifier(), 'Adaboost':se.AdaBoostClassifier(st.DecisionTreeClassifier(), n_estimators=100), 'GBDT':se.GradientBoostingClassifier(n_estimators=100), '随机森林':se.RandomForestClassifier(n_estimators=100)} for name,obj in model_dict.items(): select_model(name,obj) -------- 单颗决策树 ---------- precision recall f1-score support 0 0.95 0.92 0.93 107 1 0.98 0.99 0.98 383 accuracy 0.97 490 macro avg 0.96 0.95 0.96 490 weighted avg 0.97 0.97 0.97 490 -------- Adaboost ---------- precision recall f1-score support 0 0.95 0.92 0.93 107 1 0.98 0.99 0.98 383 accuracy 0.97 490 macro avg 0.96 0.95 0.96 490 weighted avg 0.97 0.97 0.97 490 -------- GBDT ---------- precision recall f1-score support 0 0.98 0.90 0.94 107 1 0.97 0.99 0.98 383 accuracy 0.97 490 macro avg 0.98 0.95 0.96 490 weighted avg 0.97 0.97 0.97 490 -------- 随机森林 ---------- precision recall f1-score support 0 0.96 0.90 0.93 107 1 0.97 0.99 0.98 383 accuracy 0.97 490 macro avg 0.97 0.94 0.95 490 weighted avg 0.97 0.97 0.97 490- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
模型的优化
这里以Adaboost为例子来说明有子模型的模型如何优化。
#单颗树 sub_model = st.DecisionTreeClassifier() params = {'criterion':['gini','entropy'], 'max_depth':np.arange(2,9), 'min_samples_split':np.arange(2,21), 'min_samples_leaf':np.arange(1,11)} sub_GS = ms.GridSearchCV(sub_model,params,cv=3) sub_GS.fit(x,y) #AdaBoost main_model = se.AdaBoostClassifier(sub_GS.best_estimator_) params = {'n_estimators':np.arange(20,201,10)} main_GS = ms.GridSearchCV(main_model,params,cv=3) main_GS.fit(x,y) best_model = main_GS.best_estimator_ pred_best_y = best_model.predict(test_x) print(sm.classification_report(test_y,pred_best_y)) precision recall f1-score support 0 0.98 0.95 0.97 107 1 0.99 0.99 0.99 383 accuracy 0.99 490 macro avg 0.98 0.97 0.98 490 weighted avg 0.99 0.99 0.99 490- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
保存模型
import pickle dict_info = {'数据结构':data.columns[:-1], '数据转换':{'额外通话时长':extra_time_cut, '额外流量':{'条件>':0,'True':2,'False':1}}, '模型':best_model} with open('用户流失预测模型.pickle','wb') as f: pickle.dump(dict_info,f) print('模型保存成功')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
加载模型
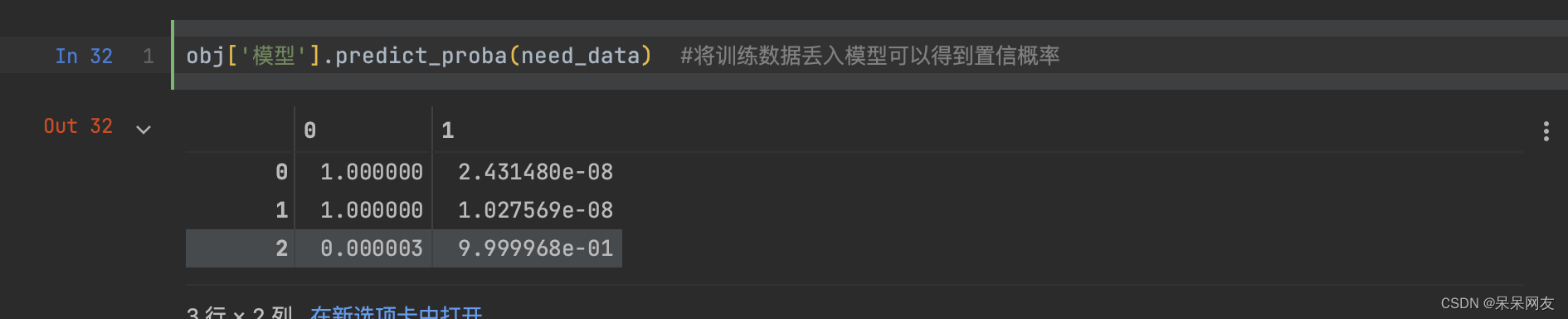
with open('./联通用户流失预测模型.pickle','rb') as f: obj = pickle.load(f) obj['数据结构'] Index(['套餐金额', '额外通话时长', '额外流量', '改变行为', '服务合约', '关联购买', '集团用户', '使用月数'], dtype='object') need_data = [[1,1000,500,0,0,1,0,25], [2,0,0,1,1,2,1,25], [1,-500,-500,0,1,0,1,13]] need_data = pd.DataFrame(need_data,columns=obj['数据结构']) need_data['额外通话时长'] = pd.cut(need_data['额外通话时长'],bins=obj['数据转换']['额外通话时长'][0], labels=obj['数据转换']['额外通话时长'][1]) need_data['额外流量'] =np.where(need_data['额外流量']>obj['数据转换']['额外流量']['条件>'], obj['数据转换']['额外流量']['True'], obj['数据转换']['额外流量']['False']) #得到置信概率 need_data['流失概率'] = obj['模型'].predict_proba(need_data)[:,-1] #将训练数据丢入模型可以得到置信概率 # 交付流失概率前50名的数据 res = need_data.sort_values(by='流失概率',ascending=False).head(50)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
置信概率得到的是一个可信与不可信的二维数据
交付内容
res.to_csv('流失预测结果.csv')- 1
-
相关阅读:
zemax光线光扇图
用 AWTK 和 AWPLC 快速开发嵌入式应用程序 (2)-走马灯
JavaScript构造函数和原型:ES5 中的新增方法
图像缩放和旋转算法
Autovue springboot集成
Rust安装(windows)
Big Data -- Postgres
(01)ORB-SLAM2源码无死角解析-(57) 闭环线程→计算Sim3:理论推导(1)求解R,使用四元数
《痞子衡嵌入式半月刊》 第 78 期
基于STM32的设计智慧超市管理系统(带收银系统+物联网环境监测)
- 原文地址:https://blog.csdn.net/weixin_45256637/article/details/126166601
