-
第五章 C++与STL入门 例题
提交地址: 算法竞赛入门经典(第二版)-刘汝佳-第五章 C++与STL 例题
中文题目地址:算法竞赛入门经典(第二版)-刘汝佳-第五章 C++与STL 例题与习题
5.1 从C到C++
5.2 STL初步
5.2.1 排序与检索
例题5-1:大理石在哪儿?
思路:
水题一道,直接暴力排序+检索即可。
代码:
#include#include using namespace std; const int N = 10010; int a[N];//石头数组 int main() { int n, q, kase = 0; //每次读入一个n,q。直到n,q都为0为止。 while(cin >> n >> q, n || q) { //对于每一组测试数据都要输出 printf("CASE# %d:\n", ++kase); for(int i = 0; i < n; i ++) cin >> a[i];//读入每一个石头上的整数 sort(a, a + n);//升序 while(q--)//处理q个询问 { int x; cin >> x; int idx = lower_bound(a, a + n, x) - a;//在已经排好序的数组a中寻找x; if(a[idx] == x) printf("%d found at %d\n", x, idx + 1); else printf("%d not found\n", x); } } return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
总结:
- 下面三种函数的作用区间都是左闭右开。
- sort()函数:sort(start,end,cmp)。默认升序,start是要排序数组的起始地址,end是数组结束地址的下一位,cmp用于规定排序的方法,可不填,默认升序。
- lower_bound()函数:lower_bound(begin,end,num)的含义是从数组的begin位置到end位置-1位置二分查找一个大于或等于num的数字,找到则返回该数字的地址,不存在则返回end。通过返回的地址减去起始地址begin,可以找到数字在数组中的下标。
- upper_bound()函数:upper_bound( begin,end,num)的含义是从数组的begin位置到end-1位置二分查找第一个大于num的数字,找到返回该数字的地址,不存在则返回end。通过返回的地址减去起始地址begin,得到找到数字在数组中的下标。
- 不管起点下标是从0开始还是1,都应该减去的是a。

5.2.2 不定长数组:vector
例题5-2:木块问题
思路:
用vector定义一个二位数组,第一维表示是第几堆木块,第二维表示高度,pile[i][j]:表示为第i堆的第j个木块是哪个木块。
直接模拟操作。对于这四种操作,有很多的相似性。所以可以简化一下,不用每一种情况直接模拟。代码:
#include#include #include #include using namespace std; const int N = 30; //创建n个木块的二维数组 vector<int> pile[N]; int n; //找到块a,在哪一块上面和他的高度 void find_block(int a,int &p, int &h) { for(p = 0; p < n; p ++) for(h = 0; h < pile[p].size(); h ++) if(pile[p][h] == a) return; } //将p这一堆上面的移走 void clear_above(int p, int h) { for(int i = h + 1; i < pile[p].size(); i++) { int b = pile[p][i]; pile[b].push_back(b);//把木块b放回原位 } pile[p].resize(h + 1);//p块只应保留下标0~h的元素 } //将pa这一堆移到pb上面去 void pile_onto(int pa, int ha, int pb) { for(int i = ha; i < pile[pa].size(); i ++) pile[pb].push_back(pile[pa][i]); pile[pa].resize(ha); } //输出每一堆的情况。 void print() { for(int i = 0; i < n; i ++) { printf("%d:",i); for(int j = 0; j < pile[i].size(); j ++) printf(" %d",pile[i][j]); cout << endl; } } int main() { //读入每一个操作 string s1, s2; int a, b; cin >> n; //一开始每个块都只有自己这一块木头 for(int i = 0; i < n; i ++) pile[i].push_back(i); while(cin >> s1 >> a >> s2 >> b) { int pa, pb, ha, hb; //对于要操作的a,b,找到他们所在在块的编号和所在块的高度 find_block(a, pa, ha); find_block(b, pb, hb); //如果两个木块在一堆视为非法操作 if(pa == pb) continue; if(s2 == "onto") clear_above(pb, hb);//如果为onto 则将Pb那一堆归位 if(s1 == "move") clear_above(pa, ha);//如果为move 则将pa那一堆归位 pile_onto(pa, ha, pb); } //输出答案 print(); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
总结:

5.2.3 集合:set

例题5-3:安迪的第一个字典
思路:

代码:
#include#include #include #include #include using namespace std; set<string>dict;//string 集合 int main() { /* stringstream的用法:当读入一个字符串s为"hello".的时候,我们想要的只是hello而不是"hello". 所以这个时候,我们只需要把其中的非字母的标点符号全部转成空格。 然后用stringstream再对s进行读入。就不会读入空格,只能得到hello */ string s, buf; while(cin >> s)//一直读入一个字符串,读到不能读 { //对于字符串s的每一字符判断一下是否是英文字符,是的话就转成小写,不是则转成空格。 for(int i = 0; i < s.length(); i ++)//为什么转小写字母是因为单词都是小写,只有句子首单词才大写首字母。 if(isalpha(s[i]))//如果当前这个字符是英文字符的话 就转成小写字母否则改为空格。 s[i] = tolower(s[i]); else s[i] = ' '; //转换之后,s就从之前的含有""、.各种标点符号的字符串,转换成一个只有英文字符和空格的字符串。 //此时,再用stingstream对s进行重读入即可得到单词。 stringstream ss(s); while(ss >> buf) dict.insert(buf); } for(auto a : dict) cout << a << endl; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
总结:
- 其中stringstream的用法很关键,需要掌握。
- set里面的数据自动从小到大排序。
- isalpha()函数:isalpha(s[i])判断s[i]是否是英文字符。
- tolower()函数:tolower(s[i])将s[i]转成小写字母。
5.2.4 映射:map

例题5-4:反片语

思路:
把每一个单词标准化,全部转为小写字母后再排序,然后再放到map中统计。
一个单词能通过字母重排得到另外一个单词 当且仅当 这两个单词 标准化之后 是相同的。代码:
#include#include #include #include #include using namespace std; vector<string>words;//存储每一个单词 map<string,int>cnt;//单词标准化之后的映射 //将字符串s 标准化,转成小写字母排序 string repr(string s) { for(int i = 0; i < s.length(); i ++) s[i] = tolower(s[i]); sort(s.begin(), s.end()); return s; } int main() { int n = 0; string s; while(cin >> s) { if(s[0] == '#') break; words.push_back(s); string r = repr(s);//将当前单词标准化. // if(!cnt.count(r)) cnt[r] = 0; cnt[r] ++;//标准化之后的放入map计数 } vector<string>ans;//存储答案 for(int i = 0; i < words.size(); i ++) { //如果当前这个单词标准化之后只出现一次, if(cnt[repr(words[i])] == 1) ans.push_back(words[i]); } //将答案数组排个序 sort(ans.begin(),ans.end()); for(int i = 0; i < ans.size();i ++) cout << ans[i] << endl; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
总结:
- 结论:一个单词能通过字母重排得到另外一个单词 当且仅当 这两个单词 标准化之后 是相同的。

5.2.5 栈、队列与优先队列

例题5-5:集合栈计算机

思路

代码
#include#include #include #include #include #include using namespace std; #define ALL(x) x.begin(),x.end() #define INS(x) inserter(x,x.begin()) typedef set<int> Set;//把set 重定义为Set。 map<Set,int> IDcache;//把集合映射为ID vector<Set>Setcache;//根据ID取集合 int ID(Set x) { if(IDcache.count(x)) return IDcache[x]; Setcache.push_back(x); return IDcache[x] = Setcache.size() - 1; } int main() { int t; cin >> t; while(t --) { stack<int>s; int n; cin >> n; //n个操作 for(int i = 0; i < n; i ++) { string op; cin >> op;//读入每次操作的指令。 if(op[0] == 'P') s.push(ID(Set())); else if(op[0] == 'D')s.push(s.top()); else { //否则都要出站两个集合。 Set x1 = Setcache[s.top()];s.pop(); Set x2 = Setcache[s.top()];s.pop(); Set x; if(op[0] == 'U') set_union(ALL(x1), ALL(x2), INS(x));//如果是U则把两个集合的并集入栈 if(op[0] == 'I') set_intersection(ALL(x1), ALL(x2), INS(x));//如果是I则把两个集合的交集入栈 if(op[0] == 'A') { x = x2; x.insert(ID(x1)); } //不管怎么样都要把x入队 s.push(ID(x)); } cout << Setcache[s.top()].size() << endl; } cout << "***" << endl; } return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
总结
1.巧妙使用宏定义 #define ALL(x) x.begin(),x.end() #define INS(x) inserter(x,x.begin()) 2.set的两个内置函数 set_union():求并集 set_intersection():求交集 3.把每一个集合set分配一个编号。- 1
- 2
- 3
- 4
- 5
- 6
- 7
例题5-6 团体队列
思路:

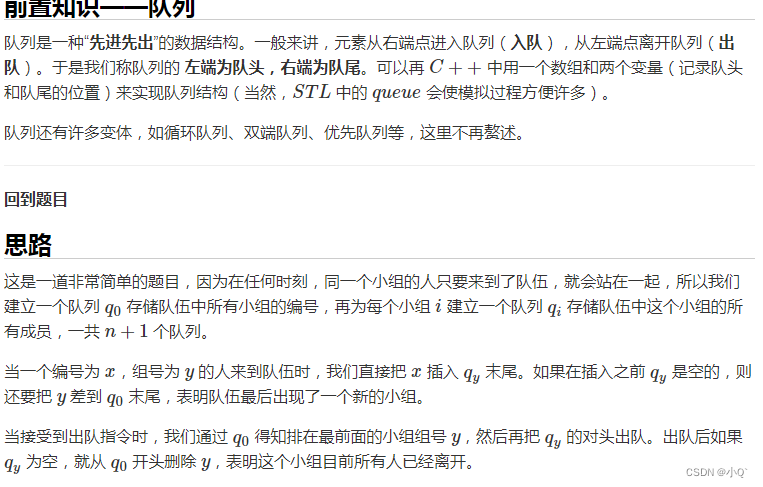
代码:
#include#include #include using namespace std; const int N = 1010, M = 1000010; int teamid[M]; int main() { int n, c = 1; while(cin >> n, n) { queue<int>team;//维护队列之间的关系 queue<int>person[N];//每个小组的人 printf("Scenario #%d\n", c++);//每个数据输出一个 //处理输入 for(int i = 0; i < n; i ++) { int cnt; cin >> cnt; while(cnt --) { int x; cin >> x; teamid[x] = i;//第x个人的属于第i组 } } string command;//命令 while(cin >> command, command != "STOP") { if(command == "ENQUEUE") { int x; cin >> x; int tid = teamid[x];//得到第x个人的小组编号 if(person[tid].empty()) team.push(tid); person[tid].push(x); } else { int tid = team.front();//取第一个小组的编号. auto &q = person[tid]; cout << q.front() << endl; q.pop(); if(q.empty()) team.pop(); } } cout << endl; } return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
总结:
- 队列插队模型。开辟M个队列维护同一个小组之间的关系,再开一个队列维护小组之间的关系。
例题5-7:丑数

思路:
通过唯一分解定理可以证明。所有的丑数 N = 2 c 1 ∗ 3 c 2 ∗ 5 c 3 N = 2^{c_1} * 3^{c_2} * 5^{c_3} N=2c1∗3c2∗5c3。

代码:
#include#include #include using namespace std; typedef long long ll; int a[3] = {2, 3, 5};//每次乘2 乘3 乘5 int main() { priority_queue<ll , vector<ll>, greater<ll>> heap;//优先队列 set<ll>s;//有时候会得到重复的数据 heap.push(1); s.insert(1); for(int i = 1; ;i ++) { ll x = heap.top();heap.pop(); if(i == 1500)//第1500出队的数就是答案 { cout << "The 1500'th ugly number is " << x << ".\n"; break; } for(int j = 0; j < 3; j ++) { ll x2 = x * a[j]; if(!s.count(x2))//判重 { heap.push(x2); s.insert(x2); } } } return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
总结:
- 用集合set判重是一个重要的方法。

5.3 大整数类
就是高精度算法。
5.4 竞赛题目举例
例题5-8: Unixls命令
思路:

注意本题是竖着输出的。代码:
#include#include #include using namespace std; const int maxcol = 60; const int maxn = 100 + 5; string filename[maxn]; void print(string s, int len, char ch) { cout << s; for(int i = 0; i < len - s.length(); i ++) cout << ch; } int main() { int n; while(cin >> n) { //求最大的长度M int M = 0; //读入每个文件的名字 for(int i = 0; i < n; i ++) { cin >> filename[i]; M = max(M, (int)filename[i].length()); } print("-", 60, '-');//输出函数 cout << endl; int col = (maxcol - M) / (M + 2) + 1;//得到总列数。 int row = (n + col - 1) / col;//得到总行数 向上取整。 sort(filename, filename + n);//将单词排序 //输出对应的单词 二维转化成一维 for(int r = 0; r < row; r ++) { for(int c = 0; c < col; c ++) { int idx = c * row + r;//将二维坐标转成一维坐标 if(idx < n) print(filename[idx], c == col - 1 ? M : M + 2, ' ');//如果存在就输出 } cout << endl; } } return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
总结:
- 有些时候用输出函数会更加简洁。
- 二维数组下标转换成一维数组下标(下标都从0开始):a[i][j] = a[j * row + i](竖着) a[i][j]=a[i*col+j](横着)
例题5-9:数据库

思路:

代码:
#includeusing namespace std; int n, m; string s, st; map<string, int>idmp;//将字符串->id int getID(string s) { if(idmp.find(s) == idmp.end()) idmp.insert({s, idmp.size()}); return idmp[s]; } int main() { while(cin >> n >> m) { getchar();//读入回车符 vector<int>table[n + 1]; idmp.clear();//初始化 for(int i = 0; i < n; i ++) { getline(cin, s); stringstream input(s);//定义一个stringstream流 while(getline(input, st, ',')) table[i].push_back(getID(st)); } bool flog = true; for(int i = 0; i < m - 1 && flog; i ++) for(int j = i + 1; j < m && flog; j ++) { map<pair<int,int>,int>pos;//两列对应字符串标号->行 for(int k = 0; k < n && flog; k ++)//遍历每一行 { if(pos.find({table[k][i], table[k][j]}) == pos.end()) pos[{table[k][i], table[k][j]}] = k; else { printf("NO\n%d %d\n%d %d\n", pos[{table[k][i],table[k][j]}]+1, k+1, i+1, j+1); isPNF = false; } } } if(flog) printf("YES\n"); } return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
总结:
- 本题值得注意的是用map实现将每个字符串赋值一个ID。
例题5-10:PGA巡回赛的奖金
思路:
代码:
总结:
留个坑。
-
相关阅读:
【ICIP2022】提高对抗攻击的迁移性(在注意力空间下扰动的多样性生成)
一篇文章看懂ThreadLocal!
45岁大龄程序员自述:我居然还苟在程序人生里,但是已经难以为继
24 | Linux 使用 systemd的使用方法
赶紧收藏!中秋节营销必备文案和海报,拿了就能用!
OCP集群内的AKO功能测试
今天是个好日子,TaxCore(POS软件)备案指北
阅读JavaScript文档-函数相关
查询自己电脑能够支持Win11系统升级的方法分享
普中51单片机学习(AD转换)
- 原文地址:https://blog.csdn.net/qq_53244181/article/details/126135258
