-
自学Python 50 正则表达式(二)使用 re模块
# Python 正则表达式(二)使用 re模块活动地址:CSDN21天学习挑战赛
本篇在Python正则表达式(一)的基础上,继续讲解Python正则表达式的相关内容。
在Python语言中,使用 re模块提供的内置标准库函数来处理正则表达式。在这个模块中,既可以直接匹配正则表达式的基本函数,也可以通过编译正则表达式对象,并使用其方法来使用正则表达式。在本节的内容中,将详细讲解使用re模块的基本知识。
一、re模块库函数介绍
在下表中,列出了 Python语言内置模块re中常用的内置函数和方法,它们中的大多数函数也与已经编译的正则表达式对象((regex obiect)和正则匹配对象(regex matchobject) 的万法同名并且具有相同的功能。
函数/方法 描述 compile(pattern,flags = 0) 使用任何可选的标记来编译正则表达式的模式,然后返回一个正则表达式对象 match(pattern,string,flags=0) 尝试使用带有可选的标记的正则表达式的模式来匹配字符串。加果匹配成功,就返回匹配对象;如果失败,就返回None search(pattern,string,flags=0) 使用可选标记搜索字符串中第一次出现的正则表达式模式。如果匹配成功,则返回匹配对象;如果失败,则返回 None findall(pattern,string [, flags]) 查找字符串中所有(非重复)出现的正则麦达式模式,并返回一个匹配列表 finditer(pattern,string [, flags]) 与findall()函数相同,但返回的不是一个列表,而是一个迭代器。对于每一次匹配,迭代器都返回一个匹配对象 split(patterm,string,maxsplit=0) 根据正则表达式的模式分隔符,split函数将字符串分割为列表,然后返回成功匹配的列表,分割最多操作maxsplit次(默认分割所有匹配成功的位置) sub(pattern,repl, string,count=0) 使用repl替换所有正则表达式的模式在字符串中出现的位置,除非定义count,否则就将替换所有出现的位置(另见subn()函数,该函数返回替换操作的数目) purge() 清除隐式编译的正则表达式模式 group(num=0) 返回整个匹配对象,或者编号为num的特定子组 groups(default=None) 返回一个包含所有匹配子组的元组(如果没有成功匹配,则返回一个空元组) groupdict(default=None) 返回一个包含所有匹配的命名子组的字典,所有的子组名称作为字典的键(如果没有成功匹配,则返回一个空字典) 二、使用 compile() 函数编译正则表达式
在 Python程序中,函数compile()的功能是编译正则表达式。使用函数compile()的语法如下所示。
compile(source, filename, mode [, flags [,dont_ inherit] ])- 1
通过使用上述格式,能够将source编译为代码或者AST 对象。代码对象能够通过 exec语句来执行或者eval()进行求值。各个参数的具体说明如下所示。
●参数 source: 字符串或者AST(Abstract Syntax Trees)对象;
●参数 filename: 代码文件名称,如果不是从文件读取代码则传递一些可辨认的值;
●参数 mode:指定编译代码的种类,可以指定为exce、eval 和 single;
●参数 flags 和 dont_inherit: 可选参数,极少使用。
例如在下面的实例中,演示了使用函数 cmpile() 将正则表达式的字符串形式编译为Patterm实例的过程:import re pattern = re.compile('[a-zA-Z]') result = pattern.findall('as3SioPdj#@23awe') print (result)- 1
- 2
- 3
- 4
在上述代码中,先使用函数re.compile将正则表达式的字符串形式编译为Pattern实例,然后使用Pattern实例处理文本并获得匹配结果(一个Match实例),最后使用Match实例获得信息,进行其他的操作。执行后输出:

三、使用函数 match() 匹配正则表达式
在Python程序中,函数match()的功能是在字符串中匹配正则表达式,如果匹配成功则返回MatchObject对象实例。使用函数match()的语法格式如下所示。
re.match(pattern, string, flags=0)- 1
●参数 pattern: 匹配的正则表达式;
●参数 string: 要匹配的字符串;
●参数 lags: 标志位,用于控制正则表达式的匹配方式,例如是否区分大小写、多行匹配等。
参数lags的选项值信息如下表所示:参数 含义意义 re.I 忽略大小写 re.L 根据本地设置而更改\w、\W、\b、\B、\s,以及\S的匹配内容 re.M 多行匹配模式 re.S 使“."元字符也匹配换行符 re.U 匹配Unicode字符 re.X 忽略patteyn中的空格,并且可以使用“#”注释 匹配成功后,函数match() 会返回一个匹配的对象,否则返回None。我们可以使用函数group(num)或函数groups()来获取匹配表达式。
例如下面在Python的交互式命令行程序中演示了使用match()以及group()的过程:>>> import re >>> m = re.match('foo', 'foo') #模式匹配字符串 >>> if m is not None: #如果匹配成功,就输出匹配内容 ... m.group() ... 'foo'- 1
- 2
- 3
- 4
- 5
- 6
例如下面是一个失败的匹配示例,会返回None.
>>> import re >>> m = re.match('papa', ' foo') #模式匹配字符串 >>> if m is not None: #如果匹配成功,就输出匹配内容 ... m.group() ...- 1
- 2
- 3
- 4
- 5
因为匹配失败,所以m被赋值为None。
四、使用函数search()扫描字符串并返回成功的匹配
在Python程序中,函数search()的功能是扫描整个字符串并返回第一个成功的匹配。 事实上,要搜索的模式出现在一个字符串 中间部分的概率,远大于出现在字符串起始部分的概率。这也就是将函数search()派上用场的时候。函数search()的工作方式与函数match()完全一致, 不同之处在于函数search()会用它的字符串参数,在任意位置对给定正则表达式模式搜索第一次出现的匹配情况。如果搜索到成功的匹配,就会返回一个匹配对象。否则,返回None。
接下来将举例说明match()和search()之间的差别。以匹配个更长的字符串为例,下面使用字符串“foo”去匹配“seafood”:>>> import re >>> m = re.match('foo', 'seafood')#匹配失败 >>> if m is not None: m.group() ...- 1
- 2
- 3
- 4
由此可以看到。此处匹配失败。match()试图从字符串的起始部分开始匹配模式。也就是说,模式中的“f"将匹配到字符串的首字母“s”上。这样的匹配肯定是失败的。然而,字符串“foo"确实出现在"seafood”之中(某个位置),所以,我们该如何让python得出肯定的结果呢?答案是使用searh()函数,而不是尝试匹配。search() 函数不但会搜索模式在字符中第一次出现的位置,而且严格地对学符从左到右搜索。
>>> import re >>> m = re.search('foo', 'seafood')#匹配失败 >>> if m is not None: m.group() ... 'foo' #搜索成功,但是匹配失败 >>>- 1
- 2
- 3
- 4
- 5
- 6
五、使用函数 findall()查找并返回符合的字符串
在Python程序中,函数findall()的功能是在字符串中查找所有符合正则表达式的字符串,并返回这些字符串的列表。如果在正则表达式中使用了组,则返回一个元组。 函数re.match()函数和函数re.search()的作用基本一样, 不同的是,函数re.match()只从字符串中第一个字符开始匹配。而函数re.scarch()则搜索整个字符串。
使用函数findall()的语法格式如下所示。re.findall (pattern, string, flags=0)- 1
请看下面的实例,功能是使用函数fndall()匹配字符串。
import re #导入模块 re #定义一个要操作的字符串变量s s = "adfad asdfasdf asdfas asdfawef asd adsfas" #将正则表达式的字符串形式编译为Pattern实例 reObjl = re.compile('((\w+)\s+\w+)') print (reObjl.findall(s)) #第1次调用函数findall() #将正则表达式的字符串形式编译为Pattern实例 reObj2 = re.compile('(\w+)\s+\w+') print (reObj2.findall(s)) #第2次调用函数findall() #将正则表达式的字符串形式编译为Pattern实例 reObj3 = re.compile('\w+\s+\w+') print (reObj3.findall(s)) #第3次调用函數findal- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
因为函数 findall()返回的总是正则表达式在字符串中所有匹配结果的列表,所以此处主要讨论列表中“结果”的展现方式,即fndall中返回列表中每个元素包含的信息。执行后会输出:

六、使用搜索替换函数sub()和subn()
在Python程序中,有两个函数/方法用于实现搜索和替换功能,这两个函数是sub()和subn()。 两者几乎样,都是将某个字符串 中所有匹配正则表达式的部分进行某种形式的替换。用来替换的部分通常是一个字符串, 但它也可能是一个函数,该函数返回一个用来替换的字符串。函数subn()和函数sub()的用法类似,但是函数subn()还可以返回一个表示替换的总数,替换后的字符串和表示替换总数的数字一起作为-个拥有 两个元素的元组返回。
在Python程序中,使用函数sub()和函数subn()的语法格式如下所示。re.sub( pattern, repl, string[, count]) re.subn( pattern, repl, string[, count] )- 1
- 2
上述各个参数的具体说明如下所示。
●pattern: 正则表达式模式;
●repl: 要替换成的内容;
● string: 进行内容替换的字符串;
●count: 可选参数,最大替换次数。
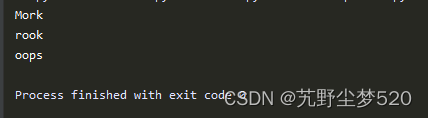
例如在下面的实例中,演示了使用函数sub()实现替换功能的过程:import re #导入模块re print(re.sub('[abc]', 'o','Mark')) #找出字母a、b或者C print(re.sub('[abc]', 'o','rock')) #将"rock"变成"rook” print(re.sub('[abc]', 'o','caps')) #将caps变成oops- 1
- 2
- 3
- 4
在上述实例代码中,首先在“Mark"中找出字母a、b或者c,并以字母“o”替换,Mark就变成Mork了。然后将“rock”变成“rook”。重点看最后行代码,有的读者可能认为可以将caps 变成oaps,但事实并非如此。函数re.sub()能够替换所有的匹配项,并且不只是第一个匹配项。因此正则表达式将会把caps变成ops,因为c和a都被转换为o。执行后会输出:
七、使用分割函数split()
在Python程序中,模块re和正则表达式中的对象函数split() 对于相对应字符串的工作方式是类似的,但是与分割一个固定字符串相比,它们基于正则表达式的模式分隔字符串,为字符串分隔功能添加一些额外功能。如果不想为每次模式的出现都分割字符串,就可以通过为参数max设定一个值(非零)的方式来指定最大分割数。如果给定的分隔符不是使用特殊符号来匹配多重模式的正则表达式,那么函数re.split()与函数str.split() 的工作方式相同,例如下面的演示过程基于单引号进行分割。
>>> re.split(':', 'strl:str2:str3') ['strl', 'str2', 'str3']- 1
- 2
请看下面的实例,功能是使用函数split()分割一个字符串。
import re DATA = ( 'MMMMM View, CA 88888', 'SSSSS, CA' , 'LLL AAAAA, 99999', 'cccccc 99999', 'PPPP AAAA CA', ) for datum in DATA: print(re.split(',|(?= (?:\d{5}|[A-Z]{2})) ',datum))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
上面的正则表达式拥有一个简单的组件, 使用pi语句基于退号分割字符串。更重要的部分是最后的正则表达式,可以通过该正则表达式预览扩展符号。在普通的英文字符串中,如果空格紧跟在五个数字(ZIP编码)成者两个大写字母(美国联邦州缩写)之后,就用spit() 函数分隔该空格。执行后会输出:

-
相关阅读:
Java Fork/Join 并发编程
Day07--wxs的概念以及其基本的用法
mybatis02
Linux——文件编程练手1:实现Linux cp命令的代码
controller-manager学习三部曲之一:通过脚本文件寻找程序入口
CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING
AliIAC 智能音频编解码器:在有限带宽条件下带来更高质量的音频通话体验
数据挖掘(六) 层次聚类
OptaPlanner 发展方向与问题
Nvidia的DeepStream通过配置文件中sink插件,快速进行视频数据的保存
- 原文地址:https://blog.csdn.net/weixin_46066007/article/details/126147936