-
大数据运维工程师面试
当前你们公司使用的Hadoop版本是什么
ambari2.5.1 Hadoop 2.7.3.2.6.2.14-5- 1
HDFS常见的数据压缩格式有哪些,介绍其中一种详细的实现方式
1 gzip压缩 优点:压缩率比较高,而且压缩/解压速度也比较快;hadoop本身支持,在应用中处理gzip格式的文件就和直接处理文本一样;有hadoop native库;大部分linux系统都自带gzip命令,使用方便。 缺点:不支持split。 应用场景:当每个文件压缩之后在130M以内的(1个块大小内),都可以考虑用gzip压缩格式。譬如说一天或者一个小时的日志压缩成一个gzip文件,运行mapreduce程序的时候通过多个gzip文件达到并发。hive程序,streaming程序,和java写的mapreduce程序完全和文本处理一样,压缩之后原来的程序不需要做任何修改。 2 lzo压缩 优点:压缩/解压速度也比较快,合理的压缩率;支持split,是hadoop中最流行的压缩格式;支持hadoop native库;可以在linux系统下安装lzop命令,使用方便。 缺点:压缩率比gzip要低一些;hadoop本身不支持,需要安装;在应用中对lzo格式的文件需要做一些特殊处理(为了支持split需要建索引,还需要指定inputformat为lzo格式)。 应用场景:一个很大的文本文件,压缩之后还大于200M以上的可以考虑,而且单个文件越大,lzo优点越明显。 3 snappy压缩 优点:高速压缩速度和合理的压缩率;支持hadoop native库。 缺点:不支持split;压缩率比gzip要低;hadoop本身不支持,需要安装;linux系统下没有对应的命令。 应用场景:当mapreduce作业的map输出的数据比较大的时候,作为map到reduce的中间数据的压缩格式;或者作为一个mapreduce作业的输出和另外一个mapreduce作业的输入。 4 bzip2压缩 优点:支持split;具有很高的压缩率,比gzip压缩率都高;hadoop本身支持,但不支持native;在linux系统下自带bzip2命令,使用方便。 缺点:压缩/解压速度慢;不支持native。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
HDFS垃圾回收的时间模式是多久,如何修改该时间
fs.trash.interval (默认值是0) fs.trash.checkpoint.interval (默认值是0) HDFS垃圾回收时间默认是360分钟fs.trash.interval=360将其修改为fs.trash.interval=1440(该配置解决数据误删)- 1
- 2
- 3
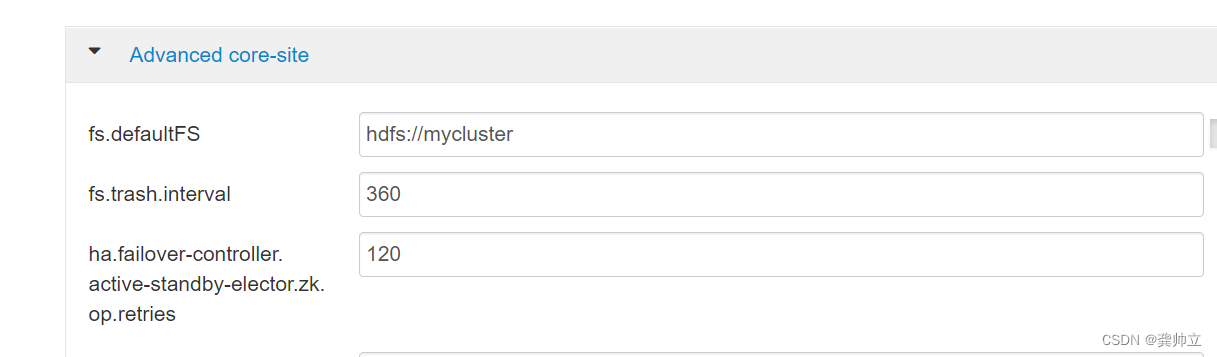
HDFS如何生效机架感知,取消机架感知有什么问题
net.topology.script.file.name /etc/hadoop/conf/topology_script.py - 1
- 2
HDFS常见的运维操作有哪些,哪些操作是高危的,如果高危操作出现问题,如何解决
hdfs文件夹增改删查 hdfs用户增改删赋权 hdfs数据均衡 Kerberos操作最复杂- 1
- 2
- 3
- 4
HDFS常见的故障是什么,如何处理,是否可以给出三种预案来防范大部分常见故障
定期block全盘扫描,引起dn心跳超时而脱离集群 namenode迁移裁撤,遇到客户端无法写入 集群dn不均衡导致文件写入失败 namenode设置了HA,但故障时未成功切换 集群时间不一致- 1
- 2
- 3
- 4
- 5
你经历过哪些严重的Hadoop故障
HDFS常用的IO压力测试工具有哪些看自己 常用的是Apache JMeter- 1
- 2
Hadoop哪些地方依赖于主机名,是否可以全部替换为IP呢(HDFS/YARN/SPARK)
NameNode、DataNode和SecondaryNameNode都是以hostname启动的了。 使用主机名的作用是为了更快地跳转,如果使用IP可能会走路由,造成访问服务延迟更甚至于报错- 1
- 2
HDFS有哪些核心的指标需要采集和监控,最重要的三个指标是什么
功能监控:需要周期性检测HDFS集群能否写入文件,读取文件 错误 容量 容量 延时- 1
- 2
- 3
- 4
- 5
HDFS节点下线,如何提升其下线速度
如何让节点快速下线的本质其实就是提高副本的复制速度。三个参数控制. 第一是控制namenode任务分发,其次控制datanode复制速率,前提是不影响正常生产任务的进行。集群规模越小,下线的越慢,比如因为分发的总数会慢很多。 1.入口参数:从namenode层面控制任务分发,这个参数修改必须重启namenode,不需要重启datanode. dfs.namenode.replication.work.multiplier.per.iteration 2.出口参数:相比上面从nanode任务分发控制,下面两个使用datanode层面控制,这两个参数也需要重启namenode 1)dfs.namenode.replication.max-streams 个参数含义是控制datanode节点进行数据复制的最大线程数,从上面我们知道block的复制优先级分成5种。这个参数控制不包含最高优先级的块复制。即除最高优先级的复制流限制 2) dfs.namenode.replication.max-streams-hard-limit- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
HDFS常见的误删除数据场景,以及如何防止数据被误删除
HDFS层面开启trash功能(fs.trash.interval) 定期作备份操作snapshot- 1
- 2
HDFS集群对外提供的访问方式有几种,哪种最为常见,每种方式各自的优缺点和使用场景
命令行访问 Web访问–HUE Web访问–HDFS的REST API- 1
- 2
- 3
HDFS你做过哪些性能调优,哪些是通用的,哪些是针对特定场景的

Hadoop日常的运维操作有什么管理工具,已经搭建的集群如何使用ambari
1、HDFS管理操作: hadoop dfsadmin 2、文件验证系统:HDFS支持使用fsck命令检测系统故障,fack会反馈各种文件出现的状况,比如文件块丢失、副本数不足等问题。hadoop fsck 3、DataNode块扫描任务:每个DataNode都会执行一个块扫描任务,周期性验证所存储块的状态,使得出现问题的块能够容易查找和修复。 4、均衡器:hdfs balancer5 5、Web访问–HUE- 1
- 2
- 3
- 4
- 5
已经搭建的集群如何使用ambari 没操作过,如果项目有需要可以研究一下- 1
- 2
Hadoop各类角色如何进行扩容,缩容,节点迁移(IP变更)
现在项目使用的大部分都是集成的大数据集群,角色的扩缩容在界面操作即可。 下面引用其他人的文章https://www.cnblogs.com/sw-code/p/16388176.html- 1
- 2
Hadoop各类角色的JVM参数配置如何设定
https://my.oschina.net/U74F1zkKW/blog/471338#OSC_h2_3- 1
HDFS的block大小如何设置,取决于哪些因素
我们在HDFS中存储数据是以块(block)的形式存放在DataNode中的,块(block)的大小可以通过设置dfs.blocksize来实现; 在Hadoop2.x的版本中,文件块的默认大小是128M,1.x老版本中默认是64M; HDFS文件块大小设置原理 HDFS文件块大小设置主要取决于磁盘传输速率,目前通过Namenode对HDFS元数据进行寻址的时间约为10ms,即查找到目标block的时间为10ms。 寻址时间为传输时间的1%时,则为最佳状态 因此,传输时间为10ms/0.01=1000ms=1s 目前磁盘的传输速率普遍为100MB/s 因此,block大小为1s*100MB/s=100MB 因为电脑底层数据采用二进制存储,所以目前的block块官方大小设置为128MB。 实际项目中可以根据你服务器的网速以及磁盘读写速率来调整: 10GE>1GE; nvme固态盘>SATA固态盘>机械硬盘- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
YARN的nodemanager上跑任务的时候,有时候会将磁盘全部打满,如何解决
在处理问题之前首先要思考一下造成这样问题的原因: 1、磁盘太小(扩容) 2、YARN参数不合理 客户提交任务的操作过于频繁,yarn.log-aggregation.retain-seconds”参数配置过高,导致汇聚的日志无法在短时时间内释放,从而引起磁盘被占满。- 1
- 2
- 3
- 4
HDFS集群多个业务方使用时如何提前做好运维规划,如权限,配额,流量突增,数据安全,目录结构
优先根据哪个项目紧急程度来决定,以及这个业务负责人的难搞程度来决定- 1
HDFS中,小文件的定义是什么,如何对小文件进行统计分析,如何优化该问题
小文件是指文件size小于HDFS上block大小的文件。这样的文件会给hadoop的扩展性和性能带来严重问题 每隔一段时间对小文件进行merge以便减少小文件数量。 小文件优化的方向: 准备阶段: (1)在数据采集的时候,就将小文件或小批数据合成大文件再上传HDFS; (2)在业务处理之前,在HDFS上使用MapReduce程序对小文件进行合并; 工作阶段: (3)在MapReduce处理时,可采用CombineTextInputFormat提高效率; (4)开启uber模式,实现jvm重用; 结束阶段:存储方式 (5)采用Hadoop Archive:一个高效的将小文件放入HDFS块中的文件存档工具,能够将多个小文件打包成一个HAR文件,从而达到减少NameNode的内存使用; (6)采用SequenceFile SequenceFile是由一系列的二进制k/v组成,如果为key为文件名,value为文件内容,可将大批小文件合并成一个大文件;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
HDFS的namenode如何进行主备切换
HDFS ZKFC实现NameNode自动切换- 1
手动切换namenode的状态 适用于当主nemenode节点硬件损坏,需要停机修复时,先手动将状态转移; 需要将 namenode1切换为 active 状态的三种方法(namenode1此时为standby): 查看节点状态 hdfs haadmin -getServiceState namenode1 # 将 active 状态从 namenode2 节点切换到 namenode1 上 (1)$ hdfs haadmin -failover namenode2 namenode1 # 将 namenode2 过渡到 Standby; (2)$ hdfs haadmin -transitionToStandby --forcemanual namenode2 # 将 namenode1过渡到 Active; (3)$ hdfs haadmin -transitionToActive --forceactive namenode1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
YARN的nodemanager导致机器死机,如何解决
1、重启服务器 2、恢复业务 3、查看YARN日志/var/log/hadoop-yarn/yarn- 1
- 2
- 3
如何下线YARN的nodemanager节点,假如该节点持续在运行计算任务
下线服务前需要提前与研发、数仓沟通会不会影响业务计算和运行状态,直接在ambari或者cdh关掉服务即可 如该节点持续在运行计算任务,需先停止计算任务或者杀掉任务 可参考:https://blog.csdn.net/u010834071/article/details/114596997- 1
- 2
- 3
YARN的nodemanager节点,从Active Nodes转为Lost Nodes,有哪些原因,在哪里设置
YARN WEB UI 运行状态查看集群整体情况,发现 LOST 节点 Yarn 显示资源使用率达到 100%,而集群节点内存,CPU 等资源却使用不是很高。 Yarn 在配置时,通过设定每个 NodeManager 可以分配的 Container 内存, 以及 CPU,来设定每个节点的资源。目前每个 NodeManager 配置了 120G,CPU 配置了 32VCore。 目前集群可能存在的问题是,每个 Container 分配的资源过高,实际任务并不需要这么多资源,从而出现了资源被分配完,但是使用率低的情况。 https://juejin.cn/post/7056610580655767565- 1
- 2
- 3
- 4
- 5
- 6
- 7
YARN的nodemanager节点如果转为Lost Nodes后,该节点上的计算任务是否还会正常继续
可以- 1
HDFS的快照原理简要介绍一下,为什么可以确保数据的安全性
Hdfs的快照(snapshot)是在某一时间点对指定文件系统拷贝,快照采用只读模式,可以对重要数据进行恢复、防止用户错误性的操作。 快照分两种:一种是建立文件系统的索引,每次更新文件不会真正的改变文件,而是新开辟一个空间用来保存更改的文件,一种是拷贝所有的文件系统。Hdfs属于前者。- 1
- 2
- 3
YARN的yarn.nodemanager.local-dirs和yarn.nodemanager.log-dirs参数应该如何设置,有哪些常见的问题
yarn.nodemanager.local-dirs 参数解释:中间结果存放位置,类似于1.0中的mapred.local.dir。注意,这个参数通常会配置多个目录,已分摊磁盘IO负载。 默认值:${hadoop.tmp.dir}/nm-local-dir yarn.nodemanager.log-dirs参数解释:日志存放地址(可配置多个目录)。 默认值:${yarn.log.dir}/userlogs 常见问题:磁盘IO过大、日志存放磁盘超限- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
distcp拷贝数据的时候,出现了java.lang.outofmemoryerror:java heap space,如何处理
解决方法: 第一种方法:修改hdfs-site dfs.checksum.type 第二种方法:加-D参数 hadoop distcp -Ddfs.checksum.type=CRC32 -update src dst- 1
- 2
- 3
- 4
- 5
有两个hadoop集群,机器相同,磁盘占用相同,一个集群磁盘的使用率比较均匀,另一个集群磁盘使用率起伏较大(很多写满的,很多使用率很低的),那么第二个集群会有哪些问题
MR程序无法很好地利用本地计算的优势,机器之间无法达到更好的网络带宽使用率,机器磁盘无法利用等等 二、解决方案 1、balancer 2、distcp- 1
- 2
- 3
- 4
hdfs namenode启动慢,常见的原因有哪些?如何优化?
1、删除大量文件之后立刻重启NameNode(例如删除100万个文件),NameNode启动慢。 3、内存不够导致hdfs namenode启动慢 答:删除大量文件时,不要立刻重启NameNode,待DataNode删除了对应的Block后重启NameNode,即不会存在这种情况。您可以通过hdfs dfsadmin -report命令来查看磁盘空间,检查文件是否删除完毕。 答:扩容- 1
- 2
- 3
- 4
- 5
hadoop的hdfs、yarn配置的zookeeper,是否可以分开
可以 Hadoop提供的服务,主要是两个:分布式存储、分布式计算。 分布式就是由多台机器协同来完成的任务。 Hadoop的分布式系统,都采用Master-Slave的主从模式,在这样的模式下,分布式存储系统(HDFS)的主节点,是NameNode。分布式资源管理系统(Yarn)的主节点,是ResourceManager。 可以把Hadoop想象成单机操作系统扩展到一个集群的情况,其中的NameNode就是文件系统的中央管理枢纽,ResourceManager就相当于单机中负责管理机器中的内存、cpu的那个操作系统的调度系统。 其实这两个框架谈不上什么分工协作的。 HDFS可以理解为像个文件系统,YARN可以理解为像个shell。 从设计的初衷上,二者就没什么分工协作, 说得更专业点,叫"耦合度低"。假设我们写一个MRv2(yarn)的简单程序,如果输入输出都不是HDFS路径,而是本地硬盘路径(local)的话,那这个程序跟hdfs可能就完全没有关系了- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
相关阅读:
01|JVM类加载机制
大学网课搜题公众号搭建教程(内含接口)
数据库update(动态更新)-SqlServer
OpenWRT搭建个人web站点并结合内网穿透实现公网远程访问
数据挖掘实验(一)数据规范化【最小-最大规范化、零-均值规范化、小数定标规范化】
ECU Bootloader自学笔记
电脑技巧:Win10粘贴文件到C盘提示没有权限的解决方法
vue3动态组件组件shallowRef包裹问题
机械设计师应该在工作中培养哪些良好习惯?
Vue中的侦听属性watch
- 原文地址:https://blog.csdn.net/weixin_38850930/article/details/126162250

